python中,字符串是一种常用的数据类型,它可以用来表示文本、字符、符号等信息。字符串可以用单引号或双引号来表示,例如:
s1 = 'Hello'
但是,有时候我们需要对字符串进行一些特殊的处理,例如格式化、转义、编码等。这时候,我们可以在字符串的前面加上一些特殊的字符,来表示字符串的不同类型或功能。
这些特殊的字符有r’‘, b’‘, u’‘, f’’,它们分别表示原始字符串、字节字符串、Unicode字符串和格式化字符串。下面我们来详细介绍它们的含义和用法。
r’‘:原始字符串
r’‘表示原始字符串,也就是说,它会忽略字符串中的转义字符,直接按照原样输出。转义字符是一些用反斜杠(\)开头的特殊字符,它们可以表示一些无法直接输入的字符,例如换行(\n)、制表符(\t)、双引号(\")等。例如:
s = "Hello\nWorld"
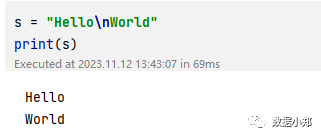
上面的代码中,\n表示换行符,所以输出结果是两行。但是如果我们在字符串前面加上r’‘,就会忽略转义字符,直接输出原始内容。例如:
s = r"Hello\nWorld"
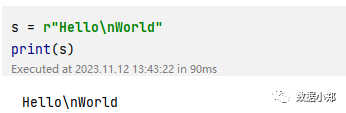
上面的代码中,\n不再表示换行符,而是直接输出为普通字符。这样就可以避免一些不必要的转义问题。
原始字符串常用于表示一些包含反斜杠的内容,例如正则表达式、文件路径等。例如:
import re
b’‘:字节字符串
b’‘表示字节字符串,也就是说,它会将字符串转换为字节类型(bytes),而不是普通的字符串类型(str)。字节类型是一种用来存储二进制数据的数据类型,它可以表示图片、音频、视频等非文本信息。字节类型和字符串类型之间可以通过编码和解码进行相互转换。编码是指将字符串按照某种规则转换为字节,解码是指将字节按照某种规则转换为字符串。常见的编码规则有UTF-8、GBK、ASCII等。例如:
s = "Hello"
上面的代码中,我们使用encode()和decode()方法来实现编码和解码。也可以直接在字符串前面加上b’‘来创建字节类型。但是要注意,字节类型只能包含ASCII字符,也就是0~127之间的字符。如果包含其他字符,就会报错。例如:
b = b"你好" # 报错:SyntaxError: bytes can only contain ASCII literal characters.
字节类型常用于处理一些二进制数据,例如网络传输、文件读写等。例如:
import requests
u’‘:Unicode字符串
u’‘表示Unicode字符串,也就是说,它会将字符串转换为Unicode类型(unicode),而不是普通的字符串类型(str)。Unicode类型是一种用来表示各种语言字符的数据类型,它可以兼容所有的字符编码,而不会出现乱码或错误。Unicode类型和字符串类型之间可以通过编码和解码进行相互转换。例如:
s = "你好"
上面的代码中,我们使用decode()和encode()方法来实现解码和编码。也可以直接在字符串前面加上u’‘来创建Unicode类型。例如:
u = u"你好"
Unicode类型在Python 2.x中是一种独立的数据类型,和字符串类型是不同的。但是在Python 3.x中,字符串类型就是Unicode类型,所以不需要再使用u’‘来表示了。例如:
s = "你好"
Unicode类型常用于处理一些多语言字符,例如中文、日文、韩文等。例如:
u = u"こんにちは"
f’‘:格式化字符串
f’‘表示格式化字符串,也就是说,它会将字符串中的花括号{}内的表达式替换为实际的值。格式化字符串可以方便地插入变量、函数、运算等内容,而不需要使用+或format()等方法。格式化字符串在Python 3.6中引入,是一种新的特性。例如:
name = "Alice"
上面的代码中,我们在字符串前面加上f’‘,然后在花括号内写入变量名或表达式。这样就可以自动替换为对应的值。也可以在花括号内加上一些格式化选项,例如对齐、填充、精度等。例如:
pi = 3.1415926
上面的代码中,我们在花括号内加上:f’‘表示格式化字符串,也就是说,它会将字符串中的花括号{}内的表达式替换为实际的值。格式化字符串可以方便地插入变量、函数、运算等内容,而不需要使用+或format()等方法。格式化字符串在Python 3.6中引入,是一种新的特性。例如:
name = "Alice"
上面的代码中,我们在字符串前面加上f’‘,然后在花括号内写入变量名或表达式。这样就可以自动替换为对应的值。也可以在花括号内加上一些格式化选项,例如对齐、填充、精度等。例如:
pi = 3.1415926
上面的代码中,我们在花括号内加上:.2f,表示保留两位小数。
格式化字符串常用于生成一些动态的文本内容,例如日志、报告、消息等。例如:
import datetime
来源-数据小郑
