SQL简介
SQL是一种操作数据库的语言; 它包括数据库创建,删除,获取行,修改行等。SQL是ANSI(美国国家标准协会)标准语言,但有许多不同版本的SQL语言。
SQL只是一种查询语言,它不是数据库。 要执行SQL查询,您需要安装任何数据库,例如Oracle,MySQL,MongoDB,PostGre SQL,SQL Server,DB2等。
1. SQL是什么?
SQL是结构化查询语言,它是一种用于存储,操作和检索存储在关系数据库中的数据的计算机语言。
SQL是关系数据库系统的标准语言。所有关系数据库管理系统(RDMS)如:MySQL,MS Access,Oracle,Sybase,Informix,Postgres和SQL Server都使用SQL作为其标准数据库语言。
此外,关系数据库管理系统使用不同的方言,如 -
- MS SQL Server使用T-SQL,
- Oracle使用PL/SQL,
- MS Access的SQL版本称为JET SQL(本机格式)等。
2. 为什么要使用SQL?
SQL广受欢迎,因为它具有以下优点 -
- 允许用户访问关系数据库管理系统中的数据。
- 允许用户描述数据。
- 允许用户定义数据库中的数据并操纵这些数据。
- 允许使用SQL模块,库和预编译器嵌入其他语言。
- 允许用户创建和删除数据库和表。
- 允许用户在数据库中创建视图,存储过程和函数。
- 允许用户设置表,过程和视图的权限。
3. SQL简史
- 1986年 - IBM开发了第一个关系数据库原型并由ANSI标准化,第一个关系数据库由Relational Software发布,后来被称为:Oracle。
- 1978年 - IBM致力于开发Codd的想法,并发布了一款名为System/R的产品。
- 1974年 - 出现了结构化查询语言。
- 1970年 - IBM的Dr. Edgar F. “Ted” Codd 博士是关系数据库的之父,他第一个描述了数据库的关系模型。
4. SQL处理
当RDBMS执行SQL命令时,系统会确定执行请求的最佳方式,而SQL引擎会确定如何解析任务。
此过程中包含各种组件。这些组件是 -
- 查询调度程序
- 优化引擎
- 经典查询引擎
- SQL查询引擎等
经典查询引擎处理所有非SQL查询,但SQL查询引擎不处理逻辑文件。
以下是SQL体系结构的图示 -

5. SQL命令
与关系数据库交互的标准SQL命令是:CREATE,SELECT,INSERT,UPDATE,DELETE和DROP。 这些命令可根据其性质分为以下几组:
5.1. DDL - 数据定义语言
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | CREATE |
用于在数据库中创建新表,表视图或其他对象。 |
| 2 | ALTER |
用于修改现有数据库对象,例如:表。 |
| 3 | DROP |
用于删除整个表,数据库中的表或其他对象的视图。 |
5.2. DML - 数据操纵语言
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | SELECT |
从一个或多个表中检索某些记录。 |
| 2 | INSERT |
创建一条记录。 |
| 3 | UPDATE |
用于修改(更新)记录。 |
| 4 | DELETE |
删除记录。 |
5.3. DCL - 数据控制语言
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | GRANT |
为用户提供权限。 |
| 2 | REVOKE |
撤销用户授予的权限。 |
RDBMS概念
数据库是有组织的数据集合。数据库处理程序以这样一种方式创建数据库,即只有一组软件程序为所有用户提供数据访问。
数据库的主要目的是通过存储,检索和管理来操作大量数据信息。互联网上有许多动态网站,通过数据库处理。 例如,用于检查酒店房间可用性的模型。 它是使用数据库的动态网站的一个例子。
有许多数据库可用,如:MySQL,Sybase,Oracle,Mango DB,Informix,Postgre,SQL Server等。SQL或结构化查询语言用于对存储在数据库中的数据执行操作。 SQL依赖于关系代数和元组关系演算。
1. 表
RDBMS中的数据存储在称为表的数据库对象中。 该表基本上是相关数据条目的集合,它由许多列和行组成。
请记住,表是关系数据库中最常见,最简单的数据存储形式,它有行和列组成。 以下程序是Customer表的示例 -
+------+--------+------+-------------+------------+ | ID | NAME | AGE | ADDRESS | SALARY | +------+--------+------+-------------+------------+ | 1 | 张三 | 32 | Haikou | 2000.00 | | 2 | 李四 | 25 | Guangzhou | 1500.00 | | 3 | 王五 | 25 | Haikou | 2000.00 | | 4 | 张飞 | 25 | Beijing | 6500.00 | | 5 | 张洪文 | 37 | Shanhai | 18500.00 | | 6 | 苏小牛 | 22 | Beijing | 4500.00 | | 7 | 杜博 | 24 | Shenzhen | 6700.00 | +------+--------+------+-------------+------------+
2. 字段
每个表都被分解为称为字段(也叫列)。Customer表中的字段由:ID,NAME,AGE,ADDRESS和SALARY组成。
字段是表中的一列,用于维护表中每条记录的特定信息。
3. 记录或行
记录也称为一行数据,它是表中存在的每个单独数据项。 例如,上面的CUSTOMERS表中有7条记录。 以下是Customer表中的单行数据或记录 -
+------+--------+------+-------------+------------+ | 1 | 张三 | 32 | Haikou | 2000.00 | +------+--------+------+-------------+------------+
记录是表中的水平实体。
4.列(字段)
列是表中的垂直实体,包含与表中特定字段关联的所有信息。
例如,Customer表中的一列是ADDRESS,用于表示客户的地址,如下所示 -
+-------------+ | ADDRESS | +-------------+ | Haikou | | Guangzhou | | Haikou | | Beijing | | Shanhai | | Beijing | | Shenzhen | +-------------+
5. NULL值
表中的NULL值是字段中显示为空的值,这意味着具有NULL值的字段是没有任何值的字段。
了解NULL值与零值或包含空格的字段不同非常重要。 具有NULL值的字段是在创建记录期间留空的字段,它不表示什么值。当一个字段不确定要存储什么内容时,可以使用NULL值来表示。
6. SQL约束
约束是对表上的数据列强制执行的规则。 这些用于限制可以进入表的数据类型。 这确保了数据库中数据的准确性和可靠性。
约束可以是列级别或表级别。 列级约束仅应用于一列,而表级约束应用于整个表。
以下是SQL中可用的一些最常用的约束 -
- NOT NULL约束 - 确保列不能具有
NULL值。 - DEFAULT约束 - 在未指定列时为列提供默认值。
- UNIQUE约束 - 确保列中的所有值都不同。
- PRIMARY键 - 唯一标识数据库表中的每一行/记录。
- 外键 - 唯一标识任何其他数据库表中的行/记录。
- 检查约束 -
CHECK约束确保列中的所有值都满足特定条件。 - 索引 - 用于非常快速地从数据库创建和检索数据。
NOT NULL约束
默认情况下,一列可以容纳NULL值。如果不想列有NULL值,那么需要不允许此列指定NULL定义这样的约束。
一个NULL和没有数据是不一样的,相反它代表了未知的数据。
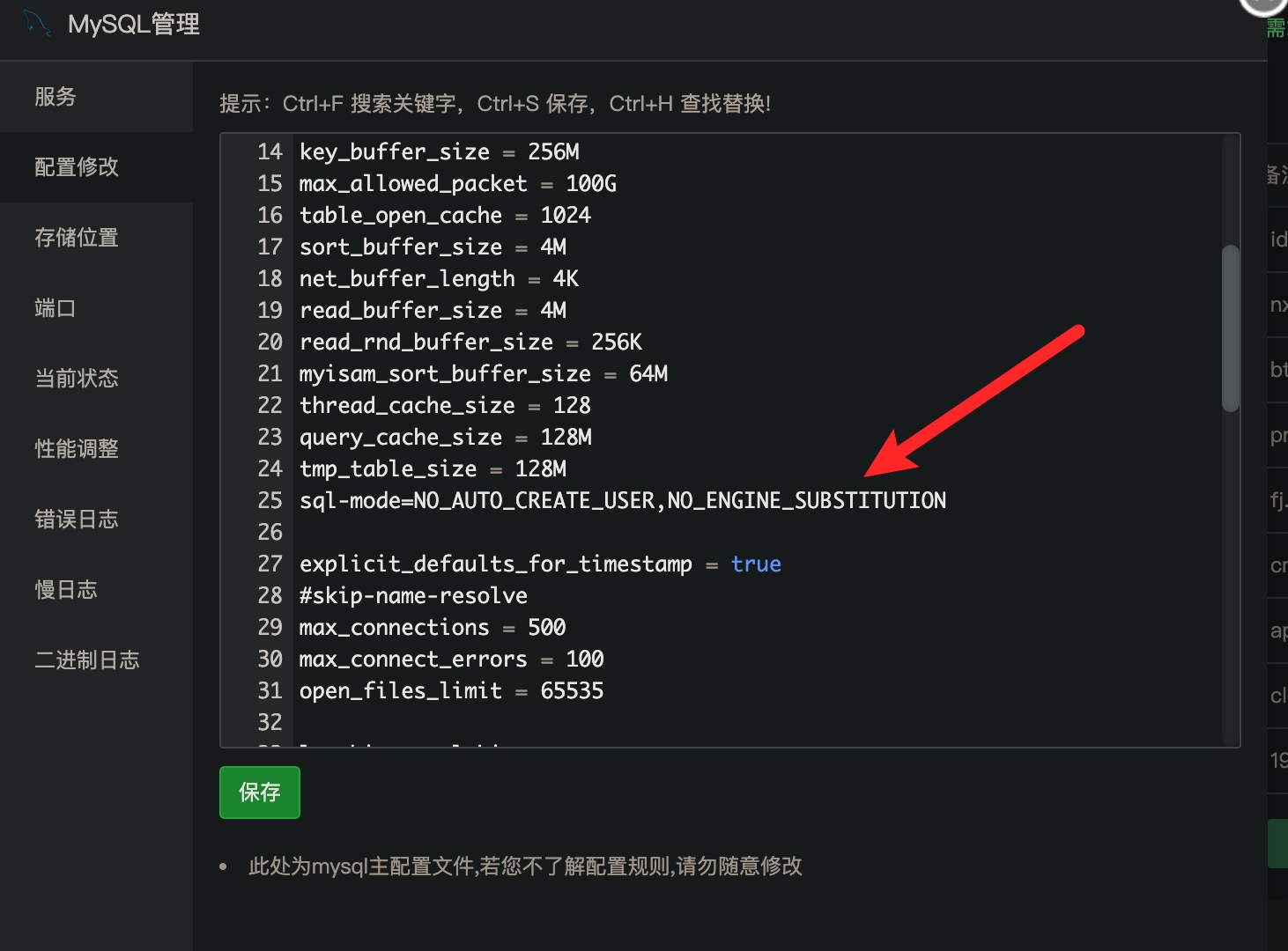
例如,下面的SQL创建一个新的表称为CUSTOMERS,并增加了五列,其中的三个: ID , NAME 和 AGE,指定不接受NULL值:
CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25) , SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
如果CUSTOMERS表已经创建,然后添加一个NOT NULL约束SALARY列在Oracle和MySQL,应该写类似如下的声明:
ALTER TABLE CUSTOMERS MODIFY SALARY DECIMAL (18, 2) NOT NULL;
DEFAULT约束
默认(DEFAULT)约束提供一个默认值,以当INSERT INTO语句不提供特定值的列。
例如,下面的SQL创建一个新的表名为CUSTOMERS,并添加了五列。在这里,SALARY列被设置为5000.00默认情况下,这样的情况下INSERT INTO语句不此列提供一个值,则在默认情况下此列可以设置为5000.00。
CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25) , SALARY DECIMAL (18, 2) DEFAULT 5000.00, PRIMARY KEY (ID) );
如果CUSTOMERS表已经创建,当添加一个DEFAULT约束SALARY列,类似如下的声明:
ALTER TABLE CUSTOMERS MODIFY SALARY DECIMAL (18, 2) DEFAULT 5000.00;
删除默认约束:
要删除DEFAULT约束,使用下面的SQL语句:
ALTER TABLE CUSTOMERS ALTER COLUMN SALARY DROP DEFAULT;
UNIQUE约束
唯一约束防止在特定的列有相同的两个纪录值。 在CUSTOMERS表,例如,可能希望以防止两个或更多的人有相同的年龄。
例如,下面的SQL创建一个新的表名为CUSTOMERS,并添加了五列。在这里,AGE列设置为唯一的,所以不能有两个记录使用相同的年龄:
CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL UNIQUE, ADDRESS CHAR (25) , SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
如果CUSTOMERS表已经创建,然后要将唯一约束添加到AGE列,类似如下的声明:
ALTER TABLE CUSTOMERS MODIFY AGE INT NOT NULL UNIQUE;
还可以使用下面的语法,它支持命名的多个列的约束:
ALTER TABLE CUSTOMERS ADD CONSTRAINT myUniqueConstraint UNIQUE(AGE, SALARY);
要删除UNIQUE约束,请使用以下SQL:
ALTER TABLE CUSTOMERS DROP CONSTRAINT myUniqueConstraint;
如果正在使用MySQL,那么可以使用下面的语法:
ALTER TABLE CUSTOMERS DROP INDEX myUniqueConstraint;
PRIMARY键
在本教程中,将介绍主键以及如何使用SQLPRIMARY KEY约束向表中添加主键。
1. SQL中的主键是什么?
表由列和行组成。 通常,表具有一列或多列,列的值唯一地标识表中的每一行。 此列或多列称为主键。
由两列或更多列组成的主键也称为复合主键。
请参阅以下课程(courses)表。

由于course_id列中的值唯一标识courses表中的第一行,因此course_id列是courses表的主键。
每个表都有一个且只有一个主键。 主键不接受NULL或重复值。如果主键由两列或更多列组成,则值可能在一列中重复,但主键中所有列的值组合必须是唯一的。

training表的主键包含employee_id和course_id列。course_id列中的值是重复的,但employee_id和course_id中的值组合不是重复的。
2. 使用PRIMARY KEY创建表
通常,在创建表时定义主键。 如果主键由一列组成,则可以使用PRIMARY KEY约束作为列或表约束。 如果主键由两列或更多列组成,则必须使用PRIMARY KEY约束作为表约束。
假设要在数据库中管理公司的项目和项目分配。 则需要创建两个表:projects和project_assignments。
以下语句创建项目(projects)表:
CREATE TABLE projects ( project_id INT PRIMARY KEY, project_name VARCHAR(255), start_date DATE NOT NULL, end_date DATE NOT NULL );
可以在列定义中添加PRIMARY KEY,以使project_id列成为projects表的主键。以下语句等效于上述语句,但它不使用PRIMARY KEY约束作为列约束,而是使用表约束。
CREATE TABLE projects ( project_id INT, project_name VARCHAR(255), start_date DATE NOT NULL, end_date DATE NOT NULL, CONSTRAINT pk_id PRIMARY KEY (project_id) );
可以使用CREATE TABLE语句末尾的CONSTRAINT子句将project_id列指定为主键。
要存储表示分配给哪个项目的项目分配,需要使用以下语句创建project_assignments表:
CREATE TABLE project_assignments ( project_id INT, employee_id INT, join_date DATE NOT NULL, CONSTRAINT pk_assgn PRIMARY KEY (project_id , employee_id) );
由于主键由两列组成:project_id和employee_id,因此必须使用PRIMARY KEY作为表约束。
3. 使用ALTER TABLE语句添加主键
首先,使用CREATE TABLE语句定义没有主键的表,尽管这不是一个好习惯。 然后,使用ALTER TABLE语句将主键添加到表中。
例如,以下语句创建没有主键的project_milestones表。project_milesones存储项目的进度。
CREATE TABLE project_milestones( milestone_id INT, project_id INT, milestone_name VARCHAR(100) );
现在,可以使用以下ALTER TABLE语句将milestone_id列设置为主键。
ALTER TABLE project_milestones ADD CONSTRAINT pk_milestone_id PRIMARY KEY (milestone_id);
可以跳过CONSTRAINT子句,如下所示:
ALTER TABLE project_milestones ADD PRIMARY KEY (milestone_id);
4. 删除主键约束
一般很少删除表的主键。 但是,如果必须这样做,可以使用ALTER TABLE语句,如下所示:
ALTER TABLE table_name DROP CONSTRAINT primary_key_constraint;
如果使用的是MySQL,则删除主键的语法更简单,如下所示:
ALTER TABLE table_name DROP PRIMARY KEY;
例如,要删除project_milestones表的主键约束,请使用以下语句。
ALTER TABLE project_milestones DROP CONSTRAINT pk_milestone_id;
在本教程中,我们介绍了主键概念,并向展示了如何管理表的主键,包括添加和删除主键。
外键
在本教程中,将学习SQL外键以及如何创建FOREIGN KEY约束以强制表之间的关系。
1. SQL外键约束简介
外键是一列或一组列,用于强制两个表中的数据之间的链接。 在外键引用中,第一个表的主键列(或多个列)由第二个表的列(或列)引用。 第二个表的列(或列)成为外键。
在创建或更改表时,可以使用FOREIGN KEY约束创建外键。 下面来看一个简单的例子以更好地理解。
2. SQL FOREIGN KEY约束示例
请参阅以下project表和project_assignments表:
CREATE TABLE projects ( project_id INT AUTO_INCREMENT PRIMARY KEY, project_name VARCHAR(255), start_date DATE NOT NULL, end_date DATE NOT NULL ); CREATE TABLE project_milestones( milestone_id INT AUTO_INCREMENT PRIMARY KEY, project_id INT, milestone_name VARCHAR(100) );
每个项目可能有零个或多个里程碑,而一个里程碑必须属于一个且只有一个项目。 使用这些表的应用程序必须确保project_milestones表中的每一行都在projects表中存在相应的行。 换句话说,没有项目就不可能存在里程碑。
不幸的是,用户可能使用客户端工具编辑数据库,或者如果应用程序中存在错误,则可能会在project_milestones表中添加一行,该行不对应于项目表中的任何行。 或者用户可以删除项目表中的行,在project_milestones表中留下孤立的行。 这会导致应用程序无法正常工作。
解决方案是向project_milestones表添加SQLFOREIGN KEY约束,以强制执行project表和project_milestones表之间的关系。
可以在创建表时创建FOREIGN KEY约束,如下所示:
CREATE TABLE project_milestones ( milestone_id INT AUTO_INCREMENT PRIMARY KEY, project_id INT, milestone_name VARCHAR(100), FOREIGN KEY (project_id) REFERENCES projects (project_id) );
FOREIGN KEY子句将project_milestones表的project_id设置为引用project表的project_id列的外键。
FOREIGN KEY (project_id) REFERENCES projects (project_id)
可以为FOREIGN KEY约束指定名称,如下所示:
CREATE TABLE project_milestones ( milestone_id INT AUTO_INCREMENT PRIMARY KEY, project_id INT, milestone_name VARCHAR(100), CONSTRAINT fk_project FOREIGN KEY (project_id) REFERENCES projects (project_id) );
hk_project是FOREIGN KEY约束的名称。将FOREIGN KEY约束添加到现有表
,要向现有表添加FOREIGN KEY约束,请使用ALTER TABLE语句。
ALTER TABLE table_1 ADD CONSTRAINT fk_name FOREIGN KEY (fk_key_column) REFERENCES table_2(pk_key_column)
假设project_milestones列已经存在,但是没有任何预定义的外键,如果想要为project_id列定义FOREIGN KEY约束。 为此,请使用以下ALTER TABLE语句:
ALTER TABLE project_milestones ADD CONSTRAINT fk_project FOREIGN KEY(project_id) REFERENCES projects(project_id);
3. 删除外键约束
要删除外键约束,还要使用ALTER TABLE语句,如下所示:
ALTER TABLE table_name DROP CONSTRAINT fk_name;
如果使用的是MySQL,则可以使用更清晰的语法,如下所示:
ALTER TABLE table_name DROP FOREIGN KEY fk_name;
例如,要删除fk_project外键约束,请使用以下语句:
ALTER TABLE project_milestones DROP CONSTRAINT fk_project;
在本教程中,我们介绍了外键概念,并演示了如何使用SQLFOREIGN KEY约束创建和删除外键。
检查约束
检查(CHECK)约束允许条件来检查被输入到一个记录的值。如果条件计算结果为false,记录违反了约束,则不会被存储进入到表中。
例如,下面的SQL创建一个新的表名为CUSTOMERS,并添加了五列。在这里,我们添加使用AGE列的检查,这样就不能有18岁以下的任何客户:
CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL CHECK (AGE >= 18), ADDRESS CHAR (25) , SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
如果CUSTOMERS表已经创建, 然后将CHECK约束添加到AGE列,使用类似如下的声明:
ALTER TABLE CUSTOMERS MODIFY AGE INT NOT NULL CHECK (AGE >= 18 );
还可以使用下面的语法,它支持命名的多个列的约束:
ALTER TABLE CUSTOMERS ADD CONSTRAINT myCheckConstraint CHECK(AGE >= 18);
删除CHECK约束:
要删除CHECK约束,使用下面的SQL语法。此语法不在MySQL中使用:
ALTER TABLE CUSTOMERS DROP CONSTRAINT myCheckConstraint;
索引
索引是用来快速创建并从数据库中检索数据。索引可以通过使用单个或一组的列在一个表中创建。 当创建索引时,它被分配一个ROWID在每一行进行排序出来的数据之前。
适当的索引对于大型数据库的性能有不错的提升, 但在创建索引时要小心。选择字段取决于使用的是什么SQL查询。
例如,下面的SQL创建一个新的表名为CUSTOMERS,并增加了五列:
CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25) , SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
现在,您可以创建单个或多个列索引使用以下语法:
CREATE INDEX index_name ON table_name ( column1, column2.....);
要在AGE列上创建一个索引, 来优化客户搜索一个特定的年龄,以下是SQL语法:
CREATE INDEX idx_age ON CUSTOMERS ( AGE );
删除索引约束:
要删除索引的约束,使用下面的SQL:
ALTER TABLE CUSTOMERS DROP INDEX idx_age;
7. 数据的完整性
每个RDBMS都存在以下类别的数据完整性 -
- 实体完整性 - 表中没有重复的行。
- 域完整性 - 通过限制值的类型,格式或范围,为给定列强制执行有效条目。
- 参照完整性 - 其他记录使用(引用)导致这些行无法删除。
- 用户定义的完整性 - 实施一些不属于实体,域或参照完整性的特定业务规则。
8. 数据库范式
数据库范式是在数据库中有效组织数据的过程。主要有两个原因 -
- 消除冗余数据,例如,将相同数据存储在多个表中。
- 确保数据依赖性是有意义的。
这两个原因都是值得的,因为它们减少了数据库消耗的空间量并确保了数据的逻辑存储。 范式包含一系列指南,可帮助指导您创建良好的数据库结构。
可将表单视为数据库结构的格式或方式。 这样的目的是组织数据库结构,使其符合第一范式的规则,然后是第二范式,最后是第三范式。
可以选择进一步采用它并转到第四范式,第五范式等等,但总的来说,第三范式是够用了。
- 第一范式(1NF)
- 第二范式(2NF)
- 第三范式(3NF)
数据库
当前有许多流行的关系数据库管理系统(RDBMS)可供使用。 本教程简要概述了一些最流行的RDBMS,这有助于读者比较它们的基本功能。
1. MySQL数据库
MySQL是一个开源SQL数据库,由瑞典公司MySQL AB开发。 MySQL支持许多不同的平台,包括Microsoft Windows,主要Linux发行版,UNIX和Mac OS X。
MySQL有免费和付费版本,具体取决于其用途(非商业/商业)和功能。 MySQL带有一个非常快速,多线程,多用户和强大的SQL数据库服务器。
1.1. MySQL历史
- MySQL由Michael Widenius和David Axmark于1994年开发。
- MySQL于1995年5月23日首次内部发布。
- Windows版本于1998年1月8日针对Windows 95和NT发布。
- MySQL 3.23:2000年6月发布测试版,2001年1月发布。
- MySQL 4.0:2002年8月发布测试版,2003年3月发布生产版(联盟)。
- MySQL 4.01:从2003年8月开始测试,Jyoti采用MySQL进行数据库跟踪。
- MySQL 4.1:2004年6月发布测试版,2004年10月发布。
- MySQL5.0:2005年3月发布测试版,2005年10月发布。
- Sun Microsystems于2008年2月26日收购了MySQL AB。
- MySQL5.1:2008年11月27日发布了生产版本。
1.2. MySQL特性
- 高性能。
- 高可用性。
- 可扩展性和灵活性运行任何东西。
- 强大的事务支持。
- Web和数据仓库的优势。
- 强大的数据保护。
- 综合应用开发。
- 管理轻松。
- 开源自由和24 x 7支持。
- 最低的总拥有成本。
2. MS SQL Server
MS SQL Server是由Microsoft公司开发的关系数据库管理系统。它的主要查询语言是 -
- T-SQL
- ANSI SQL
2.1. MS SQL Server历史
1987年 - Sybase发布用于UNIX的SQL Server。
1988年 - 微软,Sybase和Aston-Tate将SQL Server移植到OS / 2。
1989年 - 微软,Sybase和Aston-Tate发布用于OS/2的SQL Server 1.0。
1990年 - 发布SQL Server 1.1,支持Windows 3.0客户端。Aston - Tate退出SQL Server开发。
2000年 - 微软发布SQL Server 2000。
2001年 - Microsoft发布用于SQL Server Web Release 1的XML(下载)。
2002年 - Microsoft发布SQLXML 2.0(从XML for SQL Server重命名)。
2002年 - 微软发布SQLXML 3.0。
2005年 - Microsoft于2005年11月7日发布了SQL Server 2005。
2.2. 特性
- 高性能
- 高可用性
- 数据库镜像
- 数据库快照
- CLR集成
- 服务代理
- DDL触发器
- 排名功能
- 基于行版本的隔离级别
- XML集成
- TRY…CATCH
- 数据库邮件
3. ORACLE
Oracle是一个非常大的基于多用户的数据库管理系统。Oracle是由“Oracle Corporation”开发的关系数据库管理系统。
Oracle致力于高效管理其资源,它是在网络中请求和发送数据的多个客户端之间的信息数据库。
它是客户端/服务器计算的优秀数据库服务器选择。 Oracle支持客户端和服务器的所有主要操作系统,包括MSDOS,NetWare,UnixWare,OS/2和大多数UNIX风格。
3.1. 历史
Oracle始于1977年,它在数据库行业已经有42个辉煌岁月(从1977年到2019年)。
- 1977年 - Larry Ellison,Bob Miner和Ed Oates成立了软件开发实验室,负责开发工作。
- 1979年 - Oracle 2.0版本发布,它成为第一个商业关系数据库和第一个SQL数据库。 该公司更名为Relational Software Inc.(RSI)。
- 1981年 - RSI开始为Oracle开发工具。
- 1982年 - RSI更名为Oracle Corporation。
- 1983年 - Oracle发布了3.0版本,用C语言重写并在多个平台上运行。
- 1984年 - Oracle 4.0发布。 它包含并发控制等功能 - 多版本读取一致性等。
- 1985年 - Oracle 4.0发布。 它包含并发控制等功能 - 多版本读取一致性等。
- 2007年 - Oracle发布了Oracle11g。 新版本专注于更好的分区,轻松迁移等。
- 2013年 - Oracle 12c版本正式发布。
3.2. 特征
- 并发
- 读一致性
- 锁定机制
- 静默数据库
- 可移植性
- 自我管理数据库
- 在SQL * Plus
- ASM
- 调度
- 资源管理
- 数据仓库
- 物化视图
- 位图索引
- 表压缩
- 并行执行
- 分析SQL
- 数据挖掘
- 分区
4. MS ACCESS数据库
MS ACCESS数据库是最受欢迎的Microsoft产品之一。 Microsoft Access是一种入门级数据库管理软件。 Access数据库不仅价格低廉,而且是小型项目的强大数据库。MS Access使用Jet数据库引擎,该引擎使用特定的SQL语言方言(有时称为Jet SQL)。MS Access附带专业版的MS Office软件包。 MS Access具有易于使用的直观图形界面。它的发展历程如下 -
- 1992年 - Access 1.0版发布。
- 1993年 - 发布Access 1.1以提高与包含Access Basic编程语言的兼容性。
- 最重要的转变是从Access 97到Access 2000。
- 2007年 - Access 2007,它引入了一种新的数据库格式ACCDB,支持复杂的数据类型,如多值和附件字段。
4.1. 特征
- 用户可以创建表,查询,表单和报表,并使用宏将它们连接在一起。
- 可选择将数据导入和导出为多种格式,包括Excel,Outlook,ASCII,dBase,Paradox,FoxPro,SQL Server,Oracle,ODBC等。
- 还有Jet数据库格式(Access 2007中的MDB或ACCDB),它可以将应用程序和数据包含在一个文件中。 这使得将整个应用程序分发给另一个可以在断开连接的环境中运行的用户非常方便。
- Microsoft Access提供参数化查询。 可以通过DAO或ADO从其他程序(如VB6和.NET)引用这些查询和Access表。
- Microsoft SQL Server的桌面版可以与Access一起使用,作为Jet数据库引擎的替代方案。
- Microsoft Access是基于文件服务器的数据库。 与客户端 - 服务器关系数据库管理系统(RDBMS)不同,Microsoft Access不实现数据库触发器,存储过程或事务日志记录。
SQL语法
SQL是一组语法的独特规则和准则。 本教程通过列出所有基本SQL语法,为读者提供SQL快速入门。
所有SQL语句都以:SELECT,INSERT,UPDATE,DELETE,ALTER,DROP,CREATE,USE,SHOW等任何关键字开头,所有语句都以分号(;)结尾。
SELECT
SQL SELECT语句用来从数据库表获取数据返回表形式数据的结果。这些结果表被称为结果集。
语法
SELECT语句的基本语法如下:
SELECT column1, column2, columnN FROM table_name;
这里, column1, column2...是要获取其值的表的字段。 如果你想获取所有可用字段,那么可以使用下面的语法:
SELECT * FROM table_name;
例子:
考虑CUSTOMERS表具有以下记录:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
下面是一个例子,这将获取CUSTOMERS表中可用的客户的ID, Name 和 Salary:
SQL> SELECT ID, NAME, SALARY FROM CUSTOMERS;
这将产生以下结果:
+----+----------+----------+ | ID | NAME | SALARY | +----+----------+----------+ | 1 | Ramesh | 2000.00 | | 2 | Khilan | 1500.00 | | 3 | kaushik | 2000.00 | | 4 | Chaitali | 6500.00 | | 5 | Hardik | 8500.00 | | 6 | Komal | 4500.00 | | 7 | Muffy | 10000.00 | +----+----------+----------+
如果你想获取CUSTOMERS表中的所有字段,那么可使用以下查询:
(adsbygoogle = window.adsbygoogle || []).push({});
(adsbygoogle = window.adsbygoogle || []).push({});
SQL> SELECT * FROM CUSTOMERS;
这将产生以下结果:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
INSERT
SQL INSERT INTO语句用于在数据库中的数据的新行添加到表中。
语法
INSERT INTO有两个基本语法声明如下:
INSERT INTO TABLE_NAME (column1, column2, column3,...columnN)] VALUES (value1, value2, value3,...valueN);
这里, column1, column2,...columnN 是到要插入表中的数据列的名称。
你可能不会需要在SQL查询中指定的列的名称,如果要添加表中的所有列的值。但要确保的值的顺序与列名称有相同的顺序,在表中的列。SQL INSERT INTO语法将如下所示:
INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN);
例子:
下面的语句将创建六个记录在CUSTOMERS表中:
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Ramesh', 32, 'Ahmedabad', 2000.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (2, 'Khilan', 25, 'Delhi', 1500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (3, 'kaushik', 23, 'Kota', 2000.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (4, 'Chaitali', 25, 'Mumbai', 6500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (5, 'Hardik', 27, 'Bhopal', 8500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (6, 'Komal', 22, 'MP', 4500.00 );
可以使用第二个语法如下创建CUSTOMERS表中的记录:
INSERT INTO CUSTOMERS VALUES (7, 'Muffy', 24, 'Indore', 10000.00 );
以上所有的语句会在CUSTOMERS表中产生如下记录:
(adsbygoogle = window.adsbygoogle || []).push({});
(adsbygoogle = window.adsbygoogle || []).push({});
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
用一个表填充另一个表:
可以通过使用select语句填充一个表的数据到另一个表中的字段,这是必需的,以填充第一个表。下面是语法:
INSERT INTO first_table_name [(column1, column2, ... columnN)] SELECT column1, column2, ...columnN FROM second_table_name [WHERE condition];
UPDATE
SQL UPDATE查询用来修改在表格中的现有记录。
可以使用WHERE与UPDATE查询子句来更新所选行,否则所有的行会受到影响。
语法
UPDATE查询使用WHERE子句的基本语法如下:
UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];
可以使用AND或OR运算符组合N多个条件。
例子:
考虑CUSTOMERS表具有以下记录:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
下面是一个例子,这将用于更新ID为6的客户的地址:
SQL> UPDATE CUSTOMERS SET ADDRESS = 'Pune' WHERE ID = 6;
现在,CUSTOMERS表中有以下记录:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | Pune | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
如果要修改CUSTOMERS表中所有的地址和SALARY列值;那么不需要使用WHERE子句,UPDATE查询将如下所示:
(adsbygoogle = window.adsbygoogle || []).push({});
(adsbygoogle = window.adsbygoogle || []).push({});
SQL> UPDATE CUSTOMERS SET ADDRESS = 'Pune', SALARY = 1000.00;
现在,CUSTOMERS表中有以下记录:
+----+----------+-----+---------+---------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+---------+---------+ | 1 | Ramesh | 32 | Pune | 1000.00 | | 2 | Khilan | 25 | Pune | 1000.00 | | 3 | kaushik | 23 | Pune | 1000.00 | | 4 | Chaitali | 25 | Pune | 1000.00 | | 5 | Hardik | 27 | Pune | 1000.00 | | 6 | Komal | 22 | Pune | 1000.00 | | 7 | Muffy | 24 | Pune | 1000.00 | +----+----------+-----+---------+---------+
DELETE
SQL DELETE查询用来从表中删除现有的记录。
您可以使用WHERE子句限定DELETE查询删除所选行,否则,所有的记录将被删除。
语法
DELETE查询使用WHERE子句的基本语法如下:
DELETE FROM table_name WHERE [condition];
您可以使用AND或OR运算符组合N多个条件。
例子:
考虑CUSTOMERS表具有以下记录:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
下面是一个例子,它会删除一个ID是6的客户:
SQL> DELETE FROM CUSTOMERS WHERE ID = 6;
现在,CUSTOMERS表中有以下记录(ID=6的记录已经被删除了):
(adsbygoogle = window.adsbygoogle || []).push({});
(adsbygoogle = window.adsbygoogle || []).push({});
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
如果你希望CUSTOMERS表中所有的记录删除,你不需要使用WHERE子句,完整的DELETE查询如下:
SQL> DELETE FROM CUSTOMERS;
现在,CUSTOMERS表将不会有任何记录。
DROP
本教程介绍如何使用SQLDROP TABLE语句删除数据库中的一个或多个表。
1. SQL DROP TABLE语句简介
随着数据库在应用过程不断的数据增加,有时需要从数据库中删除过时的冗余表或不用的表。 要删除表,可使用DROP TABLE语句。
以下是DROP TABLE语句的语法。
DROP TABLE [IF EXISTS] table_name;
要删除现有表,可在DROP TABLE子句后指定表的名称。 如果要删除的表不存在,则数据库系统会发出错误。
为了防止删除不存在的表的错误,使用可选子句IF EXISTS。 如果使用IF EXISTS选项,如果删除一个不存在的表,数据库系统将不会抛出任何错误。 某些数据库系统会发出警告或通知。
DROP TABLE语句永久删除表的数据和结构,某些数据库系统要求表中的记录必须为空时才能从数据库中删除。 这有助于防止意外删除仍在使用的表。
要删除表中的所有数据,可以使用DELETE或TRUNCATE TABLE语句。要删除由另一个表的外键约束引用的表,必须在删除表之前禁用或删除外部约束。
2. SQL DROP TABLE示例
下面创建一个用于练习DROP TABLE语句的新表。
以下语句创建一个名为demo_contacts的新表,用于存储员工的紧急联系人。
CREATE TABLE demo_contacts ( id INT AUTO_INCREMENT PRIMARY KEY, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, relationship VARCHAR(50) NOT NULL, employee_id INT NOT NULL );
以下语句用于删除demo_contacts表:
DROP TABLE demo_contacts;
3. SQL DROP TABLE - 删除多个表
DROP TABLE语句允许同时删除多个表。 为此,需要在DROP TABLE子句之后指定逗号分隔表名称的列表,如下所示:
DROP TABLE table_name1,table_name2,...;
然后,数据库系统逐个删除指定的所有表。
在本教程中,我们已经学习了如何使用SQLDROP TABLE语句删除数据库中的一个或多个表。
CREATE
在本教程中,将学习如何使用SQLCREATE TABLE语句来创建新表。
1. SQL CREATE TABLE语句简介
到目前为止,我们已经了解了数据库中的表是什么。现在,是时候学习如何创建表了。
表是存储在数据库中的数据集合。 表由列和行组成。 要创建新表,请使用具有以下语法的CREATE TABLE语句:
CREATE TABLE table_name( column_name_1 data_type default value column_constraint, column_name_2 data_type default value column_constraint, ..., table_constraint );
创建新表所需的最低信息是表名和列名。由table_name指定的表名在数据库中必须是唯一的。 如果创建的表的名称与已存在的表相同,则数据库系统将发出错误。在CREATE TABLE语句中,指定以逗号分隔的列定义列表。每个列定义由列名,列的数据类型,默认值和一个或多个列约束组成。列的数据类型指定列可以存储的数据类型。 列的数据类型可以是数字,字符,日期等。列约束控制可以存储在列中的值的类型。 例如,NOT NULL约束确保列不包含NULL值。
列可能有多个列约束。 例如,users表的username列可以同时具有NOT NULL和UNIQUE约束。
如果约束包含多个列,则使用表约束。 例如,如果表的主键包含两列,则在这种情况下,必须使用PRIMARY KEY表约束。
SQL CREATE TABLE示例
假设需要将员工的培训数据存储在数据库中,并要求每个员工可以接受零或多个培训课程,并且每个培训课程可以由零个或多个员工进行。
在查看了当前数据库后,发现没有地方存储此信息,因此创建一个新的表。
以下语句创建课程表:
CREATE TABLE courses ( course_id INT AUTO_INCREMENT PRIMARY KEY, course_name VARCHAR(50) NOT NULL );
courses表有两列:course_id和course_name。course_id是课程表的主键列。 每个表都有一个且只有一个主键,用于唯一标识表中的每一行。
course_id的数据类型是整数,由INT关键字表示。 此外,course_id列的值为AUTO_INCREMENT。表示当在courses表中插入新行而不提供course_id列的值时,数据库系统将为该列生成一个整数值。course_name存储课程名称。 其数据类型是最大长度为50的字符串(VARCHAR)。NOT NULL约束确保course_name列中不存储NULL值。
现在有了存储课程数据的表。 要存储训练数据,请按如下方式创建名为training的新表。
CREATE TABLE trainings ( employee_id INT, course_id INT, taken_date DATE, PRIMARY KEY (employee_id , course_id) );
trainings表包含三列:
employee_id列存储参加课程的员工的ID。course_id列存储员工所采用的课程。taken_date列存储员工参加课程的日期。
因为trainings表的主键由两列组成:employee_id和course_id,所以必须使用PRIMARY KEY表约束。
在本教程中,您学习了如何使用SQLCREATE TABLE语句在数据库中创建新表。
- SQL不区分大小写。通常SQL关键字以大写形式编写。
- SQL语句依赖于文本行,可以在一个或多个文本行上放置一个SQL语句。
- 使用SQL语句可以在数据库中执行大多数操作。
- SQL依赖于关系代数和元组关系演算。
这里要注意的最重要的一点是SQL不区分大小写,所以语句:SELECT和select在SQL语句中具有相同的含义。 然而,MySQL在表名称是区分大小写的。 因此,如果使用MySQL,那么表命名时需要注意。
SQL常用语法
SQL SELECT语句
SELECT column1, column2....columnN FROM table_name;
SQL DISTINCT子句
SELECT DISTINCT column1, column2....columnN FROM table_name;
SQL WHERE子句
SELECT column1, column2....columnN FROM table_name WHERE CONDITION;
SQL AND/OR子句
SELECT column1, column2....columnN
FROM table_name
WHERE CONDITION-1 {AND|OR} CONDITION-2;
SQL IN子句
SELECT column1, column2....columnN FROM table_name WHERE column_name IN (val-1, val-2,...val-N);
SQL BETWEEN子句
SELECT column1, column2....columnN FROM table_name WHERE column_name BETWEEN val-1 AND val-2;
SQL Like子句
SELECT column1, column2....columnN
FROM table_name
WHERE column_name LIKE { PATTERN };
SQL ORDER BY子句
SELECT column1, column2....columnN
FROM table_name
WHERE CONDITION
ORDER BY column_name {ASC|DESC};
SQL GROUP BY子句
SELECT SUM(column_name) FROM table_name WHERE CONDITION GROUP BY column_name;
SQL COUNT子句
SELECT COUNT(column_name) FROM table_name WHERE CONDITION;
SQL HAVING子句
SELECT SUM(column_name) FROM table_name WHERE CONDITION GROUP BY column_name HAVING (arithematic function condition);
SQL CREATE TABLE语句
CREATE TABLE table_name( column1 datatype, column2 datatype, column3 datatype, ..... columnN datatype, PRIMARY KEY( one or more columns ) );
SQL DROP TABLE语句
DROP TABLE table_name;
SQL CREATE INDEX语句
CREATE UNIQUE INDEX index_name ON table_name ( column1, column2,...columnN);
SQL DROP INDEX语句
ALTER TABLE table_name DROP INDEX index_name;
SQL DESC语句
DESC table_name;
SQL TRUNCATE TABLE语句
TRUNCATE TABLE table_name;
SQL ALTER TABLE语句
ALTER TABLE table_name {ADD|DROP|MODIFY} column_name {data_ype};
SQL ALTER TABLE(rename)语句
ALTER TABLE table_name RENAME TO new_table_name;
SQL INSERT INTO语句
INSERT INTO table_name( column1, column2....columnN) VALUES ( value1, value2....valueN);
SQL UPDATE语句
UPDATE table_name SET column1 = value1, column2 = value2....columnN=valueN [ WHERE CONDITION ];
SQL DELETE语句
DELETE FROM table_name
WHERE {CONDITION};
SQL CREATE DATABASE语句
CREATE DATABASE database_name;
SQL DROP DATABASE语句
DROP DATABASE database_name;
SQL USE语句
USE database_name;
SQL COMMIT语句
COMMIT;
SQL ROLLBACK语句
ROLLBACK;
数据类型
SQL数据类型是指定任何对象的数据类型的属性。 每列,变量和表达式在SQL中都有相关的数据类型。 在创建表时可以使用这些数据类型。 也可以根据需要为表的列(字段)选择合适的数据类型。在数据库中,表的每列都具有特定的数据类型。 数据类型指定列(字段)可以容纳的数据类型,例如字符串,数值和日期时间值。
以SQL Server为例,它提供了六种类型的数据类型,如下所示 -
精确的数字数据类型
| 数据类型 | 开始值 | 结束值 |
|---|---|---|
bigint |
-9,223,372,036,854,775,808 |
9,223,372,036,854,775,807 |
int |
-2,147,483,648 |
2,147,483,647 |
smallint |
-32,768 |
32,767 |
tinyint |
0 |
255 |
bit |
0 |
1 |
decimal |
-10^38 +1 |
10^38 -1 |
numeric |
-10^38 +1 |
10^38 -1 |
money |
-922,337,203,685,477.5808 |
+922,337,203,685,477.5807 |
smallmoney |
-214,748.3648 |
+214,748.3647 |
近似数字数据类型
| 数据类型 | 开始值 | 结束值 |
|---|---|---|
float |
-1.79E + 308 |
1.79E + 308 |
real |
-3.40E + 38 |
3.40E + 38 |
日期和时间数据类型
| 数据类型 | 开始值 | 结束值 |
|---|---|---|
datetime |
-1.79E + 308 |
1.79E + 308 |
smalldatetime |
Jan 1, 1900 |
Jun 6, 2079 |
date |
存储日期,如1991年6月30日 | |
time |
存储时间。如,下午12:30 |
字符串数据类型
| 序号 | 数据类型 | 描述 |
|---|---|---|
| 1 | char |
最大长度为8,000个字符,非Unicode字符固定长度。 |
| 2 | varchar |
最多8,000个字符,非Unicode数据可变长度。 |
| 3 | varchar(max) |
最大长度为2E + 31个字符,可变长度非Unicode数据(仅限SQL Server 2005)。 |
| 4 | text |
非Unicode数据的可变长度,最大长度为2,147,483,647个字符。 |
Unicode字符串数据类型
| 序号 | 类型 | 描述 |
|---|---|---|
| 1 | nchar |
最大长度为4,000个字符,Unicode字符固定长度。 |
| 2 | nvarchar |
最大长度为4,000个字符,Unicode字符可变长度。 |
| 3 | nvarchar(max) |
最大长度为2E + 31个字符(仅限SQL Server 2005),Unicode字符可变长度。 |
| 4 | ntext |
最大长度为1,073,741,823个字符,可变长度。 |
二进制数据类型
| 序号 | 类型 | 描述 |
|---|---|---|
| 1 | binary |
最大长度为8,000字节,固定长度的二进制数据。 |
| 2 | varbinary |
最大长度为8,000字节,可变长度二进制数据。 |
| 3 | varbinary(max) |
最大长度为2E + 31个字节(仅限SQL Server 2005),可变长度二进制数据。 |
| 4 | image |
最大长度为2,147,483,647字节,可变长度二进制数据) |
其它数据类型
| 序号 | 类型 | 描述 |
|---|---|---|
| 1 | sql_variant |
存储各种SQL Server支持的数据类型的值,text,ntext和timestamp类型除外。 |
| 2 | timestamp |
存储数据库范围的唯一编号,每次更新行时都会更新该编号。 |
| 3 | uniqueidentifier |
存储全局唯一标识符(GUID) |
| 4 | xml |
存储XML数据,可以将xml实例存储在列或变量中(仅限SQL Server 2005)。 |
| 5 | cursor |
引用游标对象 |
| 6 | table |
存储结果集以供以后处理 |
SQL运算符
运算符是保留字或主要用于SQL语句的WHERE子句中的字符,用于执行操作,例如:比较和算术运算。 这些运算符用于指定SQL语句中的条件,并用作语句中多个条件的连词。常见运算符有以下几种 -
- 算术运算符
- 比较运算符
- 逻辑运算符
- 否定条件运算符
1. SQL算术运算符
假设变量a的值是:10,变量b的值是:20,则 -
| 操作符 | 描述 | 示例 |
|---|---|---|
+ |
加法,执行加法运算。 | a + b = 30 |
- |
减法,执行减法运算。 | a + b = -10 |
* |
除法,执行除法运算。 | a * b = 200 |
/ |
用左操作数除右手操作数。 | b / a = 2 |
% |
用左手操作数除左手操作数并返回余数。 | b % a = 0 |
SQL算术运算符示例
SQL算术运算符示例
以下是一些SQL算术运算符用法的简单示例 -
示例1 - 加法运算 -
mysql> select 10 + 20; +-------+ | 10 + 20 | +-------+ | 30 | +-------+ 1 row in set
示例2 - 乘法运算-
mysql> select 10 * 20; +---------+ | 10 * 20 | +---------+ | 200 | +---------+ 1 row in set
示例3 - 除法运算-
mysql> select 10 / 5; +--------+ | 10 / 5 | +--------+ | 2 | +--------+ 1 row in set
示例4 - 求余运算-
mysql> select 14 % 5; +---------+ | 14 % 5 | +---------+ | 4 | +---------+ 1 row in set
2. SQL比较运算符
变量a的值是:10,变量b的值是:20,则 -
| 操作符 | 描述 | 示例 | |
|---|---|---|---|
= |
检查两个操作数的值是否相等,如果是,则条件为真(true)。 |
(a = b)结果为false。 |
|
!= |
检查两个操作数的值是否相等,如果值不相等则条件为真(true)。 |
(a != b)结果为:true |
|
<> |
检查两个操作数的值是否相等,如果值不相等则条件为真(true)。 |
(a <> b)结果为:true |
|
> |
检查左操作数的值是否大于右操作数的值,如果是,则条件为真(true)。 |
(a > b)结果为:false |
|
< |
检查左操作数的值是否小于右操作数的值,如果是,则条件为真(true)。 |
(a < b)结果为:true |
|
>= |
检查左操作数的值是否大于或等于右操作数的值,如果是,则条件为真(true)。 |
(a >= b)结果为:false |
|
<= |
检查左操作数的值是否小于或等于右操作数的值,如果是,则条件为真(true)。 |
(a <= b)结果为:true |
|
!< |
检查左操作数的值是否不小于右操作数的值,如果是,则条件变为真(true)。 |
(a !< b)结果为:false |
|
!> |
检查左操作数的值是否不大于右操作数的值,如果是,则条件变为真(true)。 |
(a !> b)结果为:true |
SQL比较运算符示例
SQL比较运算符示例
在本教程中,您将了解SQL比较运算符以及如何使用它们来组成过滤数据的条件。SQL比较运算符用于测试两个表达式是否相同,下表说明了SQL中的比较运算符:
| 编号 | 运算符 | 描述/含意 |
|---|---|---|
| 1 | = |
等于 |
| 2 | <> |
不等于 |
| 3 | > |
大于 |
| 4 | >= |
大于或等于 |
| 5 | < |
小于 |
| 6 | <= |
小于或等于 |
| 7 | != |
不等于 |
比较运算符的结果只能是三个值:true,false和unknown的其中一个。
1. 等于(=)运算符
等于(=)运算符用于比较两个表达式的相等性:
expression1 = expression2
如果左表达式的值等于右表达式的值,则返回true; 否则返回false。
例如,以下语句查找姓氏(last_name)为Lee的员工信息:
SELECT employee_id, first_name, last_name FROM employees WHERE last_name = 'Lee';
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+ | employee_id | first_name | last_name | +-------------+------------+-----------+ | 100 | Steven | Lee | | 103 | Alexander | Lee | +-------------+------------+-----------+ 2 rows in set
在此示例中,查询在employees表的last_name列中搜索字符串:Lee。
请注意,等于(=)运算符不能用于比较NULL值。 例如,以下查询是查找没有电话号码的所有员工信息:
SELECT employee_id, first_name, last_name, phone_number FROM employees WHERE phone_number = NULL;
但是,上面查询语句返回一个空结果集,因为以下表达式始终返回false。
phone_number = NULL
要比较空(null)值,请改用IS NULL运算符,重写上面查询语句 -
SELECT employee_id, first_name, last_name, phone_number FROM employees WHERE phone_number IS NULL;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+--------------+ | employee_id | first_name | last_name | phone_number | +-------------+------------+-----------+--------------+ | 145 | John | Liu | NULL | | 146 | Karen | Liu | NULL | | 176 | Jonathon | Yang | NULL | | 177 | Jack | Yang | NULL | | 178 | Kimberely | Yang | NULL | | 179 | Charles | Yang | NULL | +-------------+------------+-----------+--------------+ 6 rows in set
2. 不等于(<>)运算符
不等于(<>)运算符用于比较两个非空表达式,如果左表达式的值不等于右表达式,则返回true; 否则返回false。
expression1 <> expression2
例如,以下语句将返回部门ID不是8的所有员工信息。
SELECT employee_id, first_name, last_name, department_id FROM employees WHERE department_id <> 8 ORDER BY first_name , last_name;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+---------------+ | employee_id | first_name | last_name | department_id | +-------------+------------+-----------+---------------+ | 103 | Alexander | Lee | 6 | | 115 | Alexander | Su | 3 | | 114 | Avg | Su | 3 | | 193 | Britney | Zhao | 5 | | 104 | Bruce | Wong | 6 | | 109 | Daniel | Chen | 10 | ... ... | 100 | Steven | Lee | 9 | | 203 | Susan | Zhou | 4 | | 106 | Valli | Chen | 6 | | 206 | William | Wu | 11 | +-------------+------------+-----------+---------------+ 34 rows in set
可以使用AND运算符组合使用不等于(<>)运算符的多个表达式。 例如,以下语句查找部门ID不是8和10的所有员工信息。
SELECT employee_id, first_name, last_name, department_id FROM employees WHERE department_id <> 8 AND department_id <> 10 ORDER BY first_name , last_name;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+---------------+ | employee_id | first_name | last_name | department_id | +-------------+------------+-----------+---------------+ | 103 | Alexander | Lee | 6 | | 115 | Alexander | Su | 3 | | 114 | Avg | Su | 3 | | 193 | Britney | Zhao | 5 | | 104 | Bruce | Wong | 6 | | 105 | David | Liang | 6 | | 107 | Diana | Chen | 6 | | 118 | Guy | Zhang | 3 | ... ... | 117 | Sigal | Zhang | 3 | | 100 | Steven | Lee | 9 | | 203 | Susan | Zhou | 4 | | 106 | Valli | Chen | 6 | | 206 | William | Wu | 11 | +-------------+------------+-----------+---------------+ 28 rows in set
3. 大于(>)运算符
大于运算符(>)比较两个非空表达式,如果左操作数大于右操作数,则返回true; 否则返回false。
expression1 > expression2
例如,要查找薪水大于12000的员工信息,那么可在WHERE子句中使用大于运算符,如下所示:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary > 12000 ORDER BY salary DESC;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+--------+ | employee_id | first_name | last_name | salary | +-------------+------------+-----------+--------+ | 100 | Steven | Lee | 24000 | | 101 | Neena | Wong | 17000 | | 102 | Lex | Liang | 17000 | | 145 | John | Liu | 14000 | | 146 | Karen | Liu | 13500 | | 201 | Michael | Zhou | 13000 | +-------------+------------+-----------+--------+
可以使用AND或OR运算符组合成比较运算符的表达式。 例如,以下语句查找部门ID是8并且薪水大于12000的员工信息:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary > 12000 AND department_id = 8 ORDER BY salary DESC;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+--------+ | employee_id | first_name | last_name | salary | +-------------+------------+-----------+--------+ | 145 | John | Liu | 14000 | | 146 | Karen | Liu | 13500 | +-------------+------------+-----------+--------+ 2 rows in set
4. 大于等于(>=)运算符
大于或等于(>=)运算符用于比较两个非空表达式。 如果左表达式的计算结果大于右表达式的值,则结果为true。
以下是大于或等于运算符的语法:
expression1 >= expression2
例如,以下查询语句用于查找薪水大于或等于9999的员工信息:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary >= 9999 ORDER BY salary;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+--------+ | employee_id | first_name | last_name | salary | +-------------+------------+-----------+--------+ | 204 | Hermann | Wu | 10000 | | 114 | Avg | Su | 11000 | | 108 | Nancy | Chen | 12000 | | 205 | Shelley | Wu | 12000 | | 201 | Michael | Zhou | 13000 | | 146 | Karen | Liu | 13500 | | 145 | John | Liu | 14000 | | 101 | Neena | Wong | 17000 | | 102 | Lex | Liang | 17000 | | 100 | Steven | Lee | 24000 | +-------------+------------+-----------+--------+ 10 rows in set
5. 小于或等于(<=)运算符
小于或等于运算符用于比较两个非空表达式,如果左表达式的值小于或等于右表达式的值,则返回true; 否则返回true。
以下是小于或等于运算符的语法:
expression1 <= expression2
例如,以下语句用于查找薪水小于或等于3500的员工信息:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary <= 3500 ORDER BY salary;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+--------+ | employee_id | first_name | last_name | salary | +-------------+------------+-----------+--------+ | 119 | Karen | Zhang | 2500 | | 118 | Guy | Zhang | 2600 | | 126 | Irene | Liu | 2700 | | 117 | Sigal | Zhang | 2800 | | 116 | Shelli | Zhang | 2900 | | 115 | Alexander | Su | 3100 | +-------------+------------+-----------+--------+ 6 rows in set
在本教程中,您学习了如何使用比较运算符来组成比较表达式,以便根据指定的条件过滤数据。
3. SQL逻辑运算符
以下是SQL中可用的所有逻辑运算符的列表。
| 序号 | 操作符 | 描述 |
|---|---|---|
| 1 | ALL | ALL运算符用于将值与另一个值集中的所有值进行比较。 |
| 2 | AND | AND运算符允许在SQL语句的WHERE子句中指定多个条件。 |
| 3 | ANY | ANY运算符用于根据条件将值与列表中的任何适用值进行比较。 |
| 4 | BETWEEN | BETWEEN运算符用于搜索在给定最小值和最大值内的值。 |
| 5 | EXISTS | EXISTS运算符用于搜索指定表中是否存在满足特定条件的行。 |
| 6 | IN | IN运算符用于将值与已指定的文字值列表进行比较。 |
| 7 | LIKE | LIKE运算符用于使用通配符运算符将值与类似值进行比较。 |
| 8 | NOT | NOT运算符反转使用它的逻辑运算符的含义。 例如:NOT EXISTS, NOT BETWEEN, NOT IN等等,这是一个否定运算符。 |
| 9 | OR | OR运算符用于组合SQL语句的WHERE子句中的多个条件。 |
| 10 | IS NULL | NULL运算符用于将值与NULL值进行比较。 |
| 11 | UNIQUE | UNIQUE运算符搜索指定表的每一行的唯一性(无重复项)。 |
SQL逻辑运算符示例
SQL逻辑运算符示例
在本教程中,您将了解SQL逻辑运算符以及如何使用它们来测试条件是否为:true。
逻辑运算符用于测试条件是否为:true。 与比较运算符类似,逻辑运算符返回值为三个:true,false或unknown的其中一个。
下表说明了SQL逻辑运算符:
| 编号 | 运算符 | 描述 |
|---|---|---|
| 1 | ALL | 如果所有比较都为真,则返回true。 |
| 2 | AND | 如果两个表达式都为真,则返回true。 |
| 3 | ANY | 如果任何一个比较为真,则返回true。 |
| 4 | BETWEEN | 如果操作数在一个指定范围内,则返回true。 |
| 5 | EXISTS | 如果子查询有结果集,则返回true。 |
| 6 | IN | 如果操作数等于列表中的值之一,则返回true。 |
| 7 | LIKE | 如果操作数与模式匹配,则返回true。 |
| 8 | NOT | 反转其他布尔运算符的结果。 |
| 9 | OR | 如果任一表达式为真,则返回true。 |
| 10 | SOME | 如果某些表达式为真,则返回true。 |
1. AND运算符
AND运算符用于在SQL语句的WHERE子句中构造多个条件,例如:SELECT,UPDATE和DELETE语句中:
expression1 AND expression2
如果两个表达式的计算结果为true,则AND运算符返回true。以下示例中,将查询薪水大于5000且小于7000的所有员工信息:
SELECT first_name, last_name, salary FROM employees WHERE salary > 5000 AND salary < 7000 ORDER BY salary;
执行上面查询语句,得到以下结果 -
+------------+-----------+--------+ | first_name | last_name | salary | +------------+-----------+--------+ | Bruce | Wong | 6000 | | Pat | Zhou | 6000 | | Charles | Yang | 6200 | | Shanta | Liu | 6500 | | Susan | Zhou | 6500 | | Min | Su | 6900 | +------------+-----------+--------+ 6 rows in set
2. OR运算符
与AND运算符类似,OR运算符用于在SQL语句的WHERE子句中组合多个条件:
expression1 OR expression2
只要有一个表达式的计算结果为true,则OR运算符返回true。
例如,以下语句查找薪水为8000或9000的员工信息:
SELECT first_name, last_name, salary FROM employees WHERE salary = 8000 OR salary = 9000 ORDER BY salary;
执行上面查询语句,得到以下结果 -
+------------+-----------+--------+ | first_name | last_name | salary | +------------+-----------+--------+ | Matthew | Han | 8000 | | Alexander | Lee | 9000 | | Daniel | Chen | 9000 | +------------+-----------+--------+ 3 rows in set
3. IS NULL运算符
IS NULL运算符将列的值与null值进行比较,如果比较的值为null,则返回true; 否则,它返回false。 例如,以下语句查找没有电话号码的所有员工信息:
SELECT first_name, last_name, phone_number FROM employees WHERE phone_number IS NULL ORDER BY first_name , last_name;
执行上面查询语句,得到以下结果 -
+------------+-----------+--------------+ | first_name | last_name | phone_number | +------------+-----------+--------------+ | Charles | Yang | NULL | | Jack | Yang | NULL | | John | Liu | NULL | | Jonathon | Yang | NULL | | Karen | Liu | NULL | | Kimberely | Yang | NULL | +------------+-----------+--------------+ 6 rows in set
4. BETWEEN运算符
BETWEEN运算符用于搜索在给定最小值和最大值范围内的值。 请注意,最小值和最大值包含在条件集合中。
例如,以下语句查找薪水在8000到10000之间的所有员工信息。
SELECT first_name, last_name, salary FROM employees WHERE salary BETWEEN 8000 AND 10000 ORDER BY salary;
执行上面查询语句,得到以下结果 -
+------------+-----------+--------+ | first_name | last_name | salary | +------------+-----------+--------+ | Matthew | Han | 8000 | | John | Chen | 8200 | | Max | Han | 8200 | | William | Wu | 8300 | | Jack | Yang | 8400 | | Jonathon | Yang | 8600 | | Alexander | Lee | 9000 | | Daniel | Chen | 9000 | | Hermann | Wu | 10000 | +------------+-----------+--------+ 9 rows in set
5. IN运算符
IN运算符将值与指定值列表进行比较。 如果比较值与列表中的其中一个值匹配,则IN运算符返回true; 否则返回false。
以下语句查找在部门ID为1或9的所有员工信息。
SELECT first_name, last_name, department_id FROM employees WHERE department_id IN (1 , 9) ORDER BY department_id;
执行上面查询语句,得到以下结果 -
+------------+-----------+---------------+ | first_name | last_name | department_id | +------------+-----------+---------------+ | Jennifer | Zhao | 1 | | Steven | Lee | 9 | | Neena | Wong | 9 | | Lex | Liang | 9 | +------------+-----------+---------------+ 4 rows in set
6. LIKE运算符
LIKE运算符使用通配符运算符将值与类似值进行比较。 SQL提供了两个与LIKE运算符一起使用的通配符:
- 百分号(
%)表示零个,一个或多个字符。 - 下划线符号(
_)表示单个字符。
以下语句查找名字以字符串Ma开头的员工信息:
SELECT employee_id, first_name, last_name FROM employees WHERE first_name LIKE 'Ma%' ORDER BY first_name;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+ | employee_id | first_name | last_name | +-------------+------------+-----------+ | 120 | Matthew | Han | | 112 | Max | Su | | 121 | Max | Han | +-------------+------------+-----------+ 3 rows in set
以下示例查找那些名字的第二个字符为i的所有员工信息:
SELECT employee_id, first_name, last_name FROM employees WHERE first_name LIKE '_i%' ORDER BY first_name;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+ | employee_id | first_name | last_name | +-------------+------------+-----------+ | 107 | Diana | Chen | | 178 | Kimberely | Yang | | 201 | Michael | Zhou | | 113 | Min | Su | | 122 | Min | Liu | | 117 | Sigal | Zhang | | 206 | William | Wu | +-------------+------------+-----------+ 7 rows in set
7. ALL运算符
ALL运算符将值与另一个值集中的所有值进行比较。ALL运算符必须以比较运算符开头,后跟子查询。
以下是ALL运算符的语法:
comparison_operator ALL (subquery)
以下示例查找薪水大于部门ID为8中所有员工工资的员工信息:
SELECT first_name, last_name, salary FROM employees WHERE salary >= ALL (SELECT salary FROM employees WHERE department_id = 8) ORDER BY salary DESC;
执行上面查询语句,得到以下结果 -
+------------+-----------+--------+ | first_name | last_name | salary | +------------+-----------+--------+ | Steven | Lee | 24000 | | Neena | Wong | 17000 | | Lex | Liang | 17000 | | John | Liu | 14000 | +------------+-----------+--------+ 4 rows in set
8. ANY运算符
ANY运算符根据条件将值与集合中的任何值进行比较,如下所示:
comparison_operator ANY(subquery)
与ALL运算符类似,ANY运算符必须以比较运算符开头,后跟子查询。
例如,以下语句查找薪水大于每个部门平均薪水的所有员工:
SELECT first_name, last_name, salary FROM employees WHERE salary > ANY(SELECT AVG(salary) FROM employees GROUP BY department_id) ORDER BY first_name , last_name;
执行上面查询语句,得到以下结果 -
+------------+-----------+--------+ | first_name | last_name | salary | +------------+-----------+--------+ | Alexander | Lee | 9000 | | Avg | Su | 11000 | | Bruce | Wong | 6000 | | Charles | Yang | 6200 | | Daniel | Chen | 9000 | ... ... | Shelley | Wu | 12000 | | Steven | Lee | 24000 | | Susan | Zhou | 6500 | | Valli | Chen | 4800 | | William | Wu | 8300 | +------------+-----------+--------+ 32 rows in set
请注意,SOME是ANY的别名,因此,可以互换使用它们。
9. EXISTS运算符
EXISTS运算符测试子查询是否包含任何行:
EXISTS (subquery)
如果子查询返回一行或多行,则EXISTS的结果为true; 否则结果是false。
例如,以下语句查找所有具有受抚养人的员工信息:
SELECT first_name, last_name FROM employees e WHERE EXISTS( SELECT 1 FROM dependents d WHERE d.employee_id = e.employee_id);
执行上面查询语句,得到以下结果 -
+------------+-----------+ | first_name | last_name | +------------+-----------+ | Steven | Lee | | Neena | Wong | | Lex | Liang | | Alexander | Lee | | Bruce | Wong | | David | Liang | | Valli | Chen | | Diana | Chen | ... ... | Shelley | Wu | | William | Wu | +------------+-----------+ 30 rows in set
通过上面的学习,现在,您应该了解所有SQL逻辑运算符以及如何使用它们来测试条件。
示例数据库
在本教程中,我们将向您介绍在整个教程中使用的SQL示例数据库。以下数据库关系图 -HR示例数据库:

在这个HR示例数据库有7个表:
employees表存储员工的数据信息。jobs表存储工作数据信息,包括职位和工资范围。departments表存储部门数据信息。dependents表存储员工的家属信息。locations表存储公司各部门的所在位置信息。countries表存储公司开展业务的国家/地区的数据。regions表存储亚洲,欧洲,美洲,中东和非洲等地区的数据。 这些国家分为不同的地区。
下图显示了表名称及其记录数据数量。
| 编号 | 表名称 | 行数 |
|---|---|---|
| 1 | employees |
40 |
| 2 | dependents |
30 |
| 3 | departments |
11 |
| 4 | jobs |
19 |
| 5 | locations |
7 |
| 6 | countries |
25 |
| 7 | regions |
4 |
通常,要使用SQL,需要安装关系数据库管理系统(RDBMS)。 如果您使用过MySQL,PostgreSQL,Oracle数据库,SQL Server或SQLite等关系数据库管理系统(RDBMS),则可以使用以下对应脚本创建示例数据库。
SQLite
SQLite是嵌入式关系数据库管理系统。 它是独立的,无服务器的,零配置和事务性SQL数据库引擎。
这篇SQLite教程提供了SQLite的基本和高级概念。此SQLite教程是为初学者和专业人士设计的。
此SQLite教程包括SQLite的所有主题,如SQLite,具有历史,功能,优点,安装,命令,语法,数据类型,操作符,表达式,数据库,表,操作,子句,glob,limit和子句,高级sqlite等等
SQLite官方网站是:http://www.sqlite.org/,有关所有SQLite的资料都可以从这个网站上找到。
为什么要用SQLite?
- SQLite不需要一个单独的服务器进程或系统操作(服务器)。
- SQLite 不需要配置,这意味着它不需要安装或管理。
- 一个完整的SQLite数据库可存储在跨平台的磁盘文件中。
- SQLite是非常小,重量轻,小于400KB完全配置或小于250KB的省略可选功能。
- SQLite是自配置的,独立的,这意味着它不需要任何外部的依赖。
- SQLite的交易是完全符合ACID,允许多个进程或线程安全访问。
- SQLite支持大多数(SQL2)符合SQL92标准的查询语言功能。
- SQLite是在ANSI-C编写的,并提供了简单和易于使用的API。
- SQLite可在UNIX(在Linux,Mac OS-X,Android,IOS)和Windows(Win32中,WINCE,WinRT的)中运行。
前提条件
在学习SQLite之前,您必须具备基础数据库知识,如SQL,MySQL等。
面向读者
此SQLite教程旨在帮助初学者和专业人士。
问题与反馈
我们不能保证您在此SQLite教程中不会遇到任何问题。本教程中的讲解,示例和代码等只是根据作者的理解来概括写出。由于作者水平和能力有限,因此不保正所有编写的文章都准确无误。但是如果有遇到任何错误或问题,请随时反馈,我们将及时纠正以方便后继读者阅读,在此对您的支持表示衷心的感谢!
1. MySQL
以下SQL脚本是用于在MySQL中创建HR示例数据库。
CREATE TABLE regions ( region_id INT (11) AUTO_INCREMENT PRIMARY KEY, region_name VARCHAR (25) DEFAULT NULL ); CREATE TABLE countries ( country_id CHAR (2) PRIMARY KEY, country_name VARCHAR (40) DEFAULT NULL, region_id INT (11) NOT NULL, FOREIGN KEY (region_id) REFERENCES regions (region_id) ON DELETE CASCADE ON UPDATE CASCADE ); CREATE TABLE locations ( location_id INT (11) AUTO_INCREMENT PRIMARY KEY, street_address VARCHAR (40) DEFAULT NULL, postal_code VARCHAR (12) DEFAULT NULL, city VARCHAR (30) NOT NULL, state_province VARCHAR (25) DEFAULT NULL, country_id CHAR (2) NOT NULL, FOREIGN KEY (country_id) REFERENCES countries (country_id) ON DELETE CASCADE ON UPDATE CASCADE ); CREATE TABLE jobs ( job_id INT (11) AUTO_INCREMENT PRIMARY KEY, job_title VARCHAR (35) NOT NULL, min_salary DECIMAL (8, 2) DEFAULT NULL, max_salary DECIMAL (8, 2) DEFAULT NULL ); CREATE TABLE departments ( department_id INT (11) AUTO_INCREMENT PRIMARY KEY, department_name VARCHAR (30) NOT NULL, location_id INT (11) DEFAULT NULL, FOREIGN KEY (location_id) REFERENCES locations (location_id) ON DELETE CASCADE ON UPDATE CASCADE ); CREATE TABLE employees ( employee_id INT (11) AUTO_INCREMENT PRIMARY KEY, first_name VARCHAR (20) DEFAULT NULL, last_name VARCHAR (25) NOT NULL, email VARCHAR (100) NOT NULL, phone_number VARCHAR (20) DEFAULT NULL, hire_date DATE NOT NULL, job_id INT (11) NOT NULL, salary DECIMAL (8, 2) NOT NULL, manager_id INT (11) DEFAULT NULL, department_id INT (11) DEFAULT NULL, FOREIGN KEY (job_id) REFERENCES jobs (job_id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (department_id) REFERENCES departments (department_id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (manager_id) REFERENCES employees (employee_id) ); CREATE TABLE dependents ( dependent_id INT (11) AUTO_INCREMENT PRIMARY KEY, first_name VARCHAR (50) NOT NULL, last_name VARCHAR (50) NOT NULL, relationship VARCHAR (25) NOT NULL, employee_id INT (11) NOT NULL, FOREIGN KEY (employee_id) REFERENCES employees (employee_id) ON DELETE CASCADE ON UPDATE CASCADE );
2. PostgreSQL
以下脚本用于在PostgreSQL中创建HR示例数据库结构。
CREATE TABLE regions ( region_id SERIAL PRIMARY KEY, region_name CHARACTER VARYING (25) ); CREATE TABLE countries ( country_id CHARACTER (2) PRIMARY KEY, country_name CHARACTER VARYING (40), region_id INTEGER NOT NULL, FOREIGN KEY (region_id) REFERENCES regions (region_id) ON UPDATE CASCADE ON DELETE CASCADE ); CREATE TABLE locations ( location_id SERIAL PRIMARY KEY, street_address CHARACTER VARYING (40), postal_code CHARACTER VARYING (12), city CHARACTER VARYING (30) NOT NULL, state_province CHARACTER VARYING (25), country_id CHARACTER (2) NOT NULL, FOREIGN KEY (country_id) REFERENCES countries (country_id) ON UPDATE CASCADE ON DELETE CASCADE ); CREATE TABLE departments ( department_id SERIAL PRIMARY KEY, department_name CHARACTER VARYING (30) NOT NULL, location_id INTEGER, FOREIGN KEY (location_id) REFERENCES locations (location_id) ON UPDATE CASCADE ON DELETE CASCADE ); CREATE TABLE jobs ( job_id SERIAL PRIMARY KEY, job_title CHARACTER VARYING (35) NOT NULL, min_salary NUMERIC (8, 2), max_salary NUMERIC (8, 2) ); CREATE TABLE employees ( employee_id SERIAL PRIMARY KEY, first_name CHARACTER VARYING (20), last_name CHARACTER VARYING (25) NOT NULL, email CHARACTER VARYING (100) NOT NULL, phone_number CHARACTER VARYING (20), hire_date DATE NOT NULL, job_id INTEGER NOT NULL, salary NUMERIC (8, 2) NOT NULL, manager_id INTEGER, department_id INTEGER, FOREIGN KEY (job_id) REFERENCES jobs (job_id) ON UPDATE CASCADE ON DELETE CASCADE, FOREIGN KEY (department_id) REFERENCES departments (department_id) ON UPDATE CASCADE ON DELETE CASCADE, FOREIGN KEY (manager_id) REFERENCES employees (employee_id) ON UPDATE CASCADE ON DELETE CASCADE ); CREATE TABLE dependents ( dependent_id SERIAL PRIMARY KEY, first_name CHARACTER VARYING (50) NOT NULL, last_name CHARACTER VARYING (50) NOT NULL, relationship CHARACTER VARYING (25) NOT NULL, employee_id INTEGER NOT NULL, FOREIGN KEY (employee_id) REFERENCES employees (employee_id) ON DELETE CASCADE ON UPDATE CASCADE );
3. Microsoft SQL Server
以下脚本用于在Microsoft SQL Server中创建HR示例数据库结构。
CREATE TABLE regions ( region_id INT IDENTITY(1,1) PRIMARY KEY, region_name VARCHAR (25) DEFAULT NULL ); CREATE TABLE countries ( country_id CHAR (2) PRIMARY KEY, country_name VARCHAR (40) DEFAULT NULL, region_id INT NOT NULL, FOREIGN KEY (region_id) REFERENCES regions (region_id) ON DELETE CASCADE ON UPDATE CASCADE ); CREATE TABLE locations ( location_id INT IDENTITY(1,1) PRIMARY KEY, street_address VARCHAR (40) DEFAULT NULL, postal_code VARCHAR (12) DEFAULT NULL, city VARCHAR (30) NOT NULL, state_province VARCHAR (25) DEFAULT NULL, country_id CHAR (2) NOT NULL, FOREIGN KEY (country_id) REFERENCES countries (country_id) ON DELETE CASCADE ON UPDATE CASCADE ); CREATE TABLE jobs ( job_id INT IDENTITY(1,1) PRIMARY KEY, job_title VARCHAR (35) NOT NULL, min_salary DECIMAL (8, 2) DEFAULT NULL, max_salary DECIMAL (8, 2) DEFAULT NULL ); CREATE TABLE departments ( department_id INT IDENTITY(1,1) PRIMARY KEY, department_name VARCHAR (30) NOT NULL, location_id INT DEFAULT NULL, FOREIGN KEY (location_id) REFERENCES locations (location_id) ON DELETE CASCADE ON UPDATE CASCADE ); CREATE TABLE employees ( employee_id INT IDENTITY(1,1) PRIMARY KEY, first_name VARCHAR (20) DEFAULT NULL, last_name VARCHAR (25) NOT NULL, email VARCHAR (100) NOT NULL, phone_number VARCHAR (20) DEFAULT NULL, hire_date DATE NOT NULL, job_id INT NOT NULL, salary DECIMAL (8, 2) NOT NULL, manager_id INT DEFAULT NULL, department_id INT DEFAULT NULL, FOREIGN KEY (job_id) REFERENCES jobs (job_id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (department_id) REFERENCES departments (department_id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (manager_id) REFERENCES employees (employee_id) ); CREATE TABLE dependents ( dependent_id INT IDENTITY(1,1) PRIMARY KEY, first_name VARCHAR (50) NOT NULL, last_name VARCHAR (50) NOT NULL, relationship VARCHAR (25) NOT NULL, employee_id INT NOT NULL, FOREIGN KEY (employee_id) REFERENCES employees (employee_id) ON DELETE CASCADE ON UPDATE CASCADE );
4. Oracle数据库(> 12c)
以下脚本用于在Oracle Database 12c中创建HR示例数据库结构。
CREATE TABLE regions ( region_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, region_name VARCHAR2 (25) DEFAULT NULL ); CREATE TABLE countries ( country_id CHAR (2) PRIMARY KEY, country_name VARCHAR2 (40) DEFAULT NULL, region_id NUMBER NOT NULL, FOREIGN KEY (region_id) REFERENCES regions (region_id) ON DELETE CASCADE ); CREATE TABLE locations ( location_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, street_address VARCHAR2 (40) DEFAULT NULL, postal_code VARCHAR2 (12) DEFAULT NULL, city VARCHAR2 (30) NOT NULL, state_province VARCHAR2 (25) DEFAULT NULL, country_id CHAR (2) NOT NULL, FOREIGN KEY (country_id) REFERENCES countries (country_id) ON DELETE CASCADE ); CREATE TABLE jobs ( job_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, job_title VARCHAR2 (35) NOT NULL, min_salary NUMBER (8, 2) DEFAULT NULL, max_salary NUMBER (8, 2) DEFAULT NULL ); CREATE TABLE departments ( department_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, department_name VARCHAR2 (30) NOT NULL, location_id NUMBER DEFAULT NULL, FOREIGN KEY (location_id) REFERENCES locations (location_id) ON DELETE CASCADE ); CREATE TABLE employees ( employee_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, first_name VARCHAR2 (20) DEFAULT NULL, last_name VARCHAR2 (25) NOT NULL, email VARCHAR2 (100) NOT NULL, phone_number VARCHAR2 (20) DEFAULT NULL, hire_date DATE NOT NULL, job_id NUMBER NOT NULL, salary NUMBER (8, 2) NOT NULL, manager_id NUMBER DEFAULT NULL, department_id NUMBER DEFAULT NULL, FOREIGN KEY (job_id) REFERENCES jobs (job_id) ON DELETE CASCADE, FOREIGN KEY (department_id) REFERENCES departments (department_id) ON DELETE CASCADE, FOREIGN KEY (manager_id) REFERENCES employees (employee_id) ); CREATE TABLE dependents ( dependent_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, first_name VARCHAR2 (50) NOT NULL, last_name VARCHAR2 (50) NOT NULL, relationship VARCHAR2 (25) NOT NULL, employee_id NUMBER NOT NULL, FOREIGN KEY (employee_id) REFERENCES employees (employee_id) ON DELETE CASCADE );
5. SQLite
以下脚本用于在SQLite中创建HR示例数据库结构。
CREATE TABLE regions ( region_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, region_name text NOT NULL ); CREATE TABLE countries ( country_id text NOT NULL, country_name text NOT NULL, region_id INTEGER NOT NULL, PRIMARY KEY (country_id ASC), FOREIGN KEY (region_id) REFERENCES regions (region_id) ON DELETE CASCADE ON UPDATE CASCADE ); CREATE TABLE locations ( location_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, street_address text, postal_code text, city text NOT NULL, state_province text, country_id INTEGER NOT NULL, FOREIGN KEY (country_id) REFERENCES countries (country_id) ON DELETE CASCADE ON UPDATE CASCADE ); CREATE TABLE departments ( department_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, department_name text NOT NULL, location_id INTEGER NOT NULL, FOREIGN KEY (location_id) REFERENCES locations (location_id) ON DELETE CASCADE ON UPDATE CASCADE ); CREATE TABLE jobs ( job_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, job_title text NOT NULL, min_salary double NOT NULL, max_salary double NOT NULL ); CREATE TABLE employees ( employee_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, first_name text, last_name text NOT NULL, email text NOT NULL, phone_number text, hire_date text NOT NULL, job_id INTEGER NOT NULL, salary double NOT NULL, manager_id INTEGER, department_id INTEGER NOT NULL, FOREIGN KEY (job_id) REFERENCES jobs (job_id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (department_id) REFERENCES departments (department_id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (manager_id) REFERENCES employees (employee_id) ON DELETE CASCADE ON UPDATE CASCADE ); CREATE TABLE dependents ( dependent_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, first_name text NOT NULL, last_name text NOT NULL, relationship text NOT NULL, employee_id INTEGER NOT NULL, FOREIGN KEY (employee_id) REFERENCES employees (employee_id) ON DELETE CASCADE ON UPDATE CASCADE );
6. 导入数据
以下脚本用于将数据加载到上面HR示例数据库创建的表中。
/*Data for the table regions */
INSERT INTO regions(region_id,region_name) VALUES (1,'欧洲');
INSERT INTO regions(region_id,region_name) VALUES (2,'美洲');
INSERT INTO regions(region_id,region_name) VALUES (3,'亚洲');
INSERT INTO regions(region_id,region_name) VALUES (4,'中东和非洲');
/*Data for the table countries */
INSERT INTO countries(country_id,country_name,region_id) VALUES ('AR','阿根廷',2);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('AU','澳大利亚',3);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('BE','比利时',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('BR','巴西',2);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('CA','加拿大',2);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('CH','瑞士',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('CN','中国',3);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('DE','德国',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('DK','丹麦',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('EG','埃及',4);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('FR','法国',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('HK','香港',3);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('IL','以色列',4);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('IN','印度',3);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('IT','意大利',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('JP','日本',3);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('KW','科威特',4);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('MX','墨西哥',2);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('NG','尼日利亚',4);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('NL','荷兰',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('SG','新加坡',3);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('UK','英国',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('US','美国',2);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('ZM','赞比亚',4);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('ZW','津巴布韦',4);
/*Data for the table locations */
INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (1400,'2014 Jabberwocky Rd','26192','Southlake','Texas','US');
INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (1500,'2011 Interiors Blvd','99236','South San Francisco','California','US');
INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (1700,'2004 Charade Rd','98199','Seattle','Washington','US');
INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (1800,'147 Spadina Ave','M5V 2L7','Toronto','Ontario','CA');
INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (2400,'8204 Arthur St',NULL,'London',NULL,'UK');
INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (2500,'Magdalen Centre, The Oxford Science Park','OX9 9ZB','Oxford','Oxford','UK');
INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (2700,'Schwanthalerstr. 7031','80925','Munich','Bavaria','DE');
/*Data for the table jobs */
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (1,'会计师',4200.00,9000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (2,'会计经理',8200.00,16000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (3,'行政助理',3000.00,6000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (4,'主席',20000.00,40000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (5,'行政副主席',15000.00,30000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (6,'会计',4200.00,9000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (7,'财务经理',8200.00,16000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (8,'人力资源代表',4000.00,9000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (9,'程序员',4000.00,10000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (10,'市场经理',9000.00,15000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (11,'市场代表',4000.00,9000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (12,'公关代表',4500.00,10500.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (13,'采购职员',2500.00,5500.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (14,'采购经理',8000.00,15000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (15,'销售经理',10000.00,20000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (16,'销售代表',6000.00,12000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (17,'运输职员',2500.00,5500.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (18,'库存职员',2000.00,5000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (19,'库存管理',5500.00,8500.00);
/*Data for the table departments */
INSERT INTO departments(department_id,department_name,location_id) VALUES (1,'管理',1700);
INSERT INTO departments(department_id,department_name,location_id) VALUES (2,'市场营销',1800);
INSERT INTO departments(department_id,department_name,location_id) VALUES (3,'采购',1700);
INSERT INTO departments(department_id,department_name,location_id) VALUES (4,'人力资源',2400);
INSERT INTO departments(department_id,department_name,location_id) VALUES (5,'运输',1500);
INSERT INTO departments(department_id,department_name,location_id) VALUES (6,'IT',1400);
INSERT INTO departments(department_id,department_name,location_id) VALUES (7,'公共关系',2700);
INSERT INTO departments(department_id,department_name,location_id) VALUES (8,'销售',2500);
INSERT INTO departments(department_id,department_name,location_id) VALUES (9,'行政人员',1700);
INSERT INTO departments(department_id,department_name,location_id) VALUES (10,'财务',1700);
INSERT INTO departments(department_id,department_name,location_id) VALUES (11,'会计',1700);
/*Data for the table employees */
INSERT INTO `employees` VALUES ('100', 'Steven', 'Lee', 'steven.lee@yiibai.com', '0532-86011111', '1987-06-17', '4', '24000.00', null, '9');
INSERT INTO `employees` VALUES ('101', 'Neena', 'Wong', 'neena.wong@kaops.com', '0551-4243311', '1989-09-21', '5', '17000.00', '100', '9');
INSERT INTO `employees` VALUES ('102', 'Lex', 'Liang', 'lex.liang@kaops.com', '0571-87622362', '1993-01-13', '5', '17000.00', '100', '9');
INSERT INTO `employees` VALUES ('103', 'Alexander', 'Lee', 'alexander.lee@kaops.com', '020-95105105', '1990-01-03', '9', '9000.00', '102', '6');
INSERT INTO `employees` VALUES ('104', 'Bruce', 'Wong', 'bruce.wong@yiibai.com', '0371-68356666', '1991-05-21', '9', '6000.00', '103', '6');
INSERT INTO `employees` VALUES ('105', 'David', 'Liang', 'david.liang@kaops.com', '0512-67513131', '1997-06-25', '9', '4800.00', '103', '6');
INSERT INTO `employees` VALUES ('106', 'Valli', 'Chen', 'valli.chen@yiibai.com', '0535-95105175', '1998-02-05', '9', '4800.00', '103', '6');
INSERT INTO `employees` VALUES ('107', 'Diana', 'Chen', 'diana.chen@yiibai.com', '025-95105105', '1999-02-07', '9', '4200.00', '103', '6');
INSERT INTO `employees` VALUES ('108', 'Nancy', 'Chen', 'nancy.chen@yiibai.com', '0531-86012520', '1994-08-17', '7', '12000.00', '101', '10');
INSERT INTO `employees` VALUES ('109', 'Daniel', 'Chen', 'daniel.chen@yiibai.com', '021-8008207890', '1994-08-16', '6', '9000.00', '108', '10');
INSERT INTO `employees` VALUES ('110', 'John', 'Chen', 'john.chen@yiibai.com', '0592-2088888', '1997-09-28', '6', '8200.00', '108', '10');
INSERT INTO `employees` VALUES ('111', 'Ismael', 'Su', 'ismael.su@yiibai.com', '029-95105688', '1997-09-30', '6', '7700.00', '108', '10');
INSERT INTO `employees` VALUES ('112', 'Max', 'Su', 'max.su@yiibai.com', '021-95105105', '1998-03-07', '6', '7800.00', '108', '10');
INSERT INTO `employees` VALUES ('113', 'Min', 'Su', 'min.su@yiibai.com', '027-88068888', '1999-12-07', '6', '6900.00', '108', '10');
INSERT INTO `employees` VALUES ('114', 'Avg', 'Su', 'avg.su@yiibai.com', '0755-82328647', '1994-12-07', '14', '11000.00', '100', '3');
INSERT INTO `employees` VALUES ('115', 'Alexander', 'Su', 'alexander.su@yiibai.com', '0431-86122222', '1995-05-18', '13', '3100.00', '114', '3');
INSERT INTO `employees` VALUES ('116', 'Shelli', 'Zhang', 'shelli.zhang@kaops.com', '0771-2222222', '1997-12-24', '13', '2900.00', '114', '3');
INSERT INTO `employees` VALUES ('117', 'Sigal', 'Zhang', 'sigal.zhang@yiibai.com', '0791-6101074', '1997-07-24', '13', '2800.00', '114', '3');
INSERT INTO `employees` VALUES ('118', 'Guy', 'Zhang', 'guy.zhang@kaops.com', '0411-82603331', '1998-11-15', '13', '2600.00', '114', '3');
INSERT INTO `employees` VALUES ('119', 'Karen', 'Zhang', 'karen.zhang@yiibai.com', '010-51019999', '1999-08-10', '13', '2500.00', '114', '3');
INSERT INTO `employees` VALUES ('120', 'Matthew', 'Han', 'matthew.Han@yiibai.com', '0574-56163111', '1996-07-18', '19', '8000.00', '100', '5');
INSERT INTO `employees` VALUES ('121', 'Max', 'Han', 'Max.han@yiibai.com', '0731-2637122', '1997-04-10', '19', '8200.00', '100', '5');
INSERT INTO `employees` VALUES ('122', 'Min', 'Liu', 'Min.liu@yiibai.com', '023-63862607', '1995-05-01', '19', '7900.00', '100', '5');
INSERT INTO `employees` VALUES ('123', 'Shanta', 'Liu', 'shanta.liu@yiibai.com', '311-87600111', '1997-10-10', '19', '6500.00', '100', '5');
INSERT INTO `employees` VALUES ('126', 'Irene', 'Liu', 'irene.liu@kaops.com', '0752-95105688', '1998-09-28', '18', '2700.00', '120', '5');
INSERT INTO `employees` VALUES ('145', 'John', 'Liu', 'john.liu@yiibai.com', null, '1996-10-01', '15', '14000.00', '100', '8');
INSERT INTO `employees` VALUES ('146', 'Karen', 'Liu', 'karen.liu@yiibai.com', null, '1997-01-05', '15', '13500.00', '100', '8');
INSERT INTO `employees` VALUES ('176', 'Jonathon', 'Yang', 'jonathon.yang@yiibai.com', null, '1998-03-24', '16', '8600.00', '100', '8');
INSERT INTO `employees` VALUES ('177', 'Jack', 'Yang', 'jack.yang@yiibai.com', null, '1998-04-23', '16', '8400.00', '100', '8');
INSERT INTO `employees` VALUES ('178', 'Kimberely', 'Yang', 'kimberely.yang@yiibai.com', null, '1999-05-24', '16', '7000.00', '100', '8');
INSERT INTO `employees` VALUES ('179', 'Charles', 'Yang', 'charles.yang@yiibai.com', null, '2000-01-04', '16', '6200.00', '100', '8');
INSERT INTO `employees` VALUES ('192', 'Sarah', 'Yang', 'sarah.yang@kaops.com', '0351-2233611', '1996-02-04', '17', '4000.00', '123', '5');
INSERT INTO `employees` VALUES ('193', 'Britney', 'Zhao', 'britney.zhao@yiibai.com', '0351-2233611', '1997-03-03', '17', '3900.00', '123', '5');
INSERT INTO `employees` VALUES ('200', 'Jennifer', 'Zhao', 'jennifer.zhao@yiibai.com', '021-66050000', '1987-09-17', '3', '4400.00', '101', '1');
INSERT INTO `employees` VALUES ('201', 'Michael', 'Zhou', 'michael.zhou@yiibai.com', '010-67237328', '1996-02-17', '10', '13000.00', '100', '2');
INSERT INTO `employees` VALUES ('202', 'Pat', 'Zhou', 'pat.zhou@yiibai.com', '0755-28114518', '1997-08-17', '11', '6000.00', '201', '2');
INSERT INTO `employees` VALUES ('203', 'Susan', 'Zhou', 'susan.zhou@yiibai.com', '0755-83587526', '1994-06-07', '8', '6500.00', '101', '4');
INSERT INTO `employees` VALUES ('204', 'Hermann', 'Wu', 'hermann.wu@yiibai.com', '0513-83512816', '1994-06-07', '12', '10000.00', '101', '7');
INSERT INTO `employees` VALUES ('205', 'Shelley', 'Wu', 'shelley.wu@yiibai.com', '0898-31686222', '1994-06-07', '2', '12000.00', '101', '11');
INSERT INTO `employees` VALUES ('206', 'William', 'Wu', 'william.wu@yiibai.com', '022-26144822', '1994-06-07', '1', '8300.00', '205', '11');
/*Data for the table dependents */
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (1,'Penelope','Wu','Child',206);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (2,'Nick','Wu','Child',205);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (3,'Ed','Zhao','Child',200);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (4,'Jennifer','Lee','Child',100);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (5,'Johnny','Wong','Child',101);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (6,'Bette','Liang','Child',102);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (7,'Grace','Chen','Child',109);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (8,'Matthew','Chen','Child',110);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (9,'Joe','Su','Child',111);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (10,'Christian','Su','Child',112);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (11,'Zero','Su','Child',113);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (12,'Karl','Chen','Child',108);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (13,'Uma','Zhou','Child',203);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (14,'Vivien','Lee','Child',103);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (15,'Cuba','Wong','Child',104);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (16,'Fred','Liang','Child',105);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (17,'Helen','Chen','Child',106);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (18,'Dan','Chen','Child',107);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (19,'Bob','Zhou','Child',201);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (20,'Lucille','Zhou','Child',202);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (21,'Kirsten','Wu','Child',204);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (22,'Elvis','Su','Child',115);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (23,'Sandra','Zhang','Child',116);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (24,'Cameron','Zhang','Child',117);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (25,'Kevin','Zhang','Child',118);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (26,'Rip','Zhang','Child',119);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (27,'Julia','Su','Child',114);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (28,'Woody','Liu','Child',145);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (29,'Alec','Liu','Child',146);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (30,'Sandra','Yang','Child',176);
7. 删除表
以下是用于刷新示例数据库时,删除所有表的脚本。
DROP TABLE employees; DROP TABLE dependents; DROP TABLE departments; DROP TABLE locations; DROP TABLE countries; DROP TABLE regions; DROP TABLE jobs;
SQL表达式
表达式是一个或多个值,运算符和SQL函数的组合,它们计算结果为确定的值。 这些SQL 表达式就像公式,它们是用查询语言编写的。还可以使用它们在数据库中查询特定的数据集。
语法
SELECT语句的基本语法如下 -
SELECT column1, column2, columnN FROM table_name WHERE [CONDITION|EXPRESSION];
有三种不同类型的SQL表达式,如下所述 -
- 布尔表达式
- 数字表达式
- 日期表达式
1. 布尔表达式
SQL布尔表达式基于匹配单个值来获取数据。 以下是语法 -
SELECT column1, column2, columnN FROM table_name WHERE SINGLE VALUE MATCHING EXPRESSION;
下面是一个简单的示例,显示了SQL布尔表达式的用法 -
SELECT employee_id, first_name, last_name, salary FROM employees e WHERE salary=12000;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+--------+ | employee_id | first_name | last_name | salary | +-------------+------------+-----------+--------+ | 108 | Nancy | Chen | 12000 | | 205 | Shelley | Wu | 12000 | +-------------+------------+-----------+--------+ 2 rows in set
2. 数字表达式
数字表达式用于在任何查询中执行数学运算。 以下是语法 -
SELECT numerical_expression as OPERATION_NAME [FROM table_name WHERE CONDITION] ;
这里,numeric_expression用于数学表达式或任何公式。 以下是一个显示SQL数字表达式用法的简单示例 -
sql> SELECT (150 + 55) AS ADDITION; +----------+ | ADDITION | +----------+ | 205 | +----------+ 1 row in set
有几个内置函数,如:avg(),sum(),count()等,可以执行所谓的针对表或特定表列的聚合数据计算。
SELECT COUNT(*) AS "total_rows" FROM employees; +------------+ | total_rows | +------------+ | 40 | +------------+ 1 row in set
3. 日期表达式
日期表达式返回当前系统日期和时间值 -
SELECT CURRENT_TIMESTAMP; +---------------------+ | CURRENT_TIMESTAMP | +---------------------+ | 2019-01-15 09:11:05 | +---------------------+ 1 row in set
另一个日期表达式如下所示 -
SELECT GETDATE(); +-------------------------+ | GETDATE | +-------------------------+ | 2019-10-12 11:17:11.141 | +-------------------------+ 1 row in set (0.00 sec)
Create Database语句
SQLCREATE DATABASE语句用于创建新的SQL数据库。
语法
CREATE DATABASE语句的基本语法如下 -
CREATE DATABASE database_name;
数据库名称(database_name)在RDBMS中必须是唯一的。如果要在此数据库中创建新表,可以使用CREATE TABLE语句。
示例
如果要创建一个新数据库 -testdb,则可使用CREATE DATABASE语句如下所示 -
CREATE DATABASE testdb;
在创建任何数据库之前,请确保您有管理员权限。 创建数据库后,可以在数据库列表中进行查看,如下所示 -
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sqldemo | | sys | | testdb | +--------------------+ 6 rows in set
还可以重命名,删除和选择数据库,这些将在下一小节中介绍。
Drop Database语句
SQLDROP DATABASE语句用于删除SQL模式中已存在的数据库。
语法
DROP DATABASE语句的基本语法如下 -
DROP DATABASE database_name;
示例
如果要删除现有数据库 -testdb,则DROP DATABASE语句如下所示 -
DROP DATABASE testdb;
删除任何数据库之前,请确保您具有管理员权限。 删除数据库后,可以在数据库列表中查看是否删除成功,如下所示 -
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sqldemo | | sys | +--------------------+ 5 rows in set
Rename Database语句
当需要更改数据库的名称时,将使用SQLRENAME DATABASE。 有时使用它是因为原始名称与数据库不相关,或者想将数据库修改为一个临时的名称。
下面我们来看看如何重命名MySql和SQL Server数据库。
1. 重命名MySQL数据库
要重命名mysql数据库,需要遵循以下语法:
RENAME DATABASE old_db_name TO new_db_name;
2. 使用T-SQL重命名SQL Server数据库
此命令对SQL Server 2005,2008,2008R2和2012非常有用。
ALTER DATABASE old_name MODIFY NAME = new_name
如果您使用的是SQL Server 2000,则还可以使用此命令重命名数据库。 但是,微软淘汰了它。
EXEC sp_renamedb 'old_name' , 'new_name'
USE语句(选择数据库)
如果SQL模式中有多个数据库,那么在开始操作之前,需要选择一个将执行操作的数据库。
SQLUSE语句用于选择SQL模式中的任何现有数据库。
语法
USE语句的基本语法如下所示 -
USE database_name;
数据库名称在RDBMS中必须是唯一的。
示例
可以查看可用的数据库,如下所示 -
mysql> SHOW DATABASES; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sqldemo | | sys | +--------------------+ 7 rows in set
现在,如果要使用sqldemo数据库,则可以执行以下SQL命令并开始使用sqldemo数据库。
USE sqldemo;
表是什么?
在学习SQL语言的过程中,表的概念非常重要。表是关系数据库的核心,那么数据库中的表是什么?表是按行和列组织的数据集合。 在DBMS术语中,表称为关系,行称为元组。
表是数据存储的简单形式,表也被视为关系的便捷表示方式。
下面来看一个员工表的示例:
- Employee
| ID | EMP_NAME | CITY | SALARY |
|---|---|---|---|
| 10010 | Maxsu | 海口 | 12000 |
| 10011 | 张三 | 北京 | 18000 |
| 10090 | 李程 | 北京 | 25000 |
| 2019 | 陈楠 | 上海 | 23800 |
在上表中,“Employee”是表名,而“ID”,“EMP_NAME”,“CITY”和“SALARY”是列名(也叫字段),多个列数据的组合形成一行,例如,在上面中,“Maxsu”,“海口”和12000组成一行数据。
Create Table
在本教程中,将学习如何使用SQLCREATE TABLE语句来创建新表。
1. SQL CREATE TABLE语句简介
到目前为止,我们已经了解了数据库中的表是什么。现在,是时候学习如何创建表了。
表是存储在数据库中的数据集合。 表由列和行组成。 要创建新表,请使用具有以下语法的CREATE TABLE语句:
CREATE TABLE table_name( column_name_1 data_type default value column_constraint, column_name_2 data_type default value column_constraint, ..., table_constraint );
创建新表所需的最低信息是表名和列名。由table_name指定的表名在数据库中必须是唯一的。 如果创建的表的名称与已存在的表相同,则数据库系统将发出错误。在CREATE TABLE语句中,指定以逗号分隔的列定义列表。每个列定义由列名,列的数据类型,默认值和一个或多个列约束组成。列的数据类型指定列可以存储的数据类型。 列的数据类型可以是数字,字符,日期等。列约束控制可以存储在列中的值的类型。 例如,NOT NULL约束确保列不包含NULL值。
数据类型
SQL数据类型是指定任何对象的数据类型的属性。 每列,变量和表达式在SQL中都有相关的数据类型。 在创建表时可以使用这些数据类型。 也可以根据需要为表的列(字段)选择合适的数据类型。在数据库中,表的每列都具有特定的数据类型。 数据类型指定列(字段)可以容纳的数据类型,例如字符串,数值和日期时间值。
以SQL Server为例,它提供了六种类型的数据类型,如下所示 -
精确的数字数据类型
| 数据类型 | 开始值 | 结束值 |
|---|---|---|
bigint |
-9,223,372,036,854,775,808 |
9,223,372,036,854,775,807 |
int |
-2,147,483,648 |
2,147,483,647 |
smallint |
-32,768 |
32,767 |
tinyint |
0 |
255 |
bit |
0 |
1 |
decimal |
-10^38 +1 |
10^38 -1 |
numeric |
-10^38 +1 |
10^38 -1 |
money |
-922,337,203,685,477.5808 |
+922,337,203,685,477.5807 |
smallmoney |
-214,748.3648 |
+214,748.3647 |
近似数字数据类型
| 数据类型 | 开始值 | 结束值 |
|---|---|---|
float |
-1.79E + 308 |
1.79E + 308 |
real |
-3.40E + 38 |
3.40E + 38 |
日期和时间数据类型
| 数据类型 | 开始值 | 结束值 |
|---|---|---|
datetime |
-1.79E + 308 |
1.79E + 308 |
smalldatetime |
Jan 1, 1900 |
Jun 6, 2079 |
date |
存储日期,如1991年6月30日 | |
time |
存储时间。如,下午12:30 |
字符串数据类型
| 序号 | 数据类型 | 描述 |
|---|---|---|
| 1 | char |
最大长度为8,000个字符,非Unicode字符固定长度。 |
| 2 | varchar |
最多8,000个字符,非Unicode数据可变长度。 |
| 3 | varchar(max) |
最大长度为2E + 31个字符,可变长度非Unicode数据(仅限SQL Server 2005)。 |
| 4 | text |
非Unicode数据的可变长度,最大长度为2,147,483,647个字符。 |
Unicode字符串数据类型
| 序号 | 类型 | 描述 |
|---|---|---|
| 1 | nchar |
最大长度为4,000个字符,Unicode字符固定长度。 |
| 2 | nvarchar |
最大长度为4,000个字符,Unicode字符可变长度。 |
| 3 | nvarchar(max) |
最大长度为2E + 31个字符(仅限SQL Server 2005),Unicode字符可变长度。 |
| 4 | ntext |
最大长度为1,073,741,823个字符,可变长度。 |
二进制数据类型
| 序号 | 类型 | 描述 |
|---|---|---|
| 1 | binary |
最大长度为8,000字节,固定长度的二进制数据。 |
| 2 | varbinary |
最大长度为8,000字节,可变长度二进制数据。 |
| 3 | varbinary(max) |
最大长度为2E + 31个字节(仅限SQL Server 2005),可变长度二进制数据。 |
| 4 | image |
最大长度为2,147,483,647字节,可变长度二进制数据) |
其它数据类型
| 序号 | 类型 | 描述 |
|---|---|---|
| 1 | sql_variant |
存储各种SQL Server支持的数据类型的值,text,ntext和timestamp类型除外。 |
| 2 | timestamp |
存储数据库范围的唯一编号,每次更新行时都会更新该编号。 |
| 3 | uniqueidentifier |
存储全局唯一标识符(GUID) |
| 4 | xml |
存储XML数据,可以将xml实例存储在列或变量中(仅限SQL Server 2005)。 |
| 5 | cursor |
引用游标对象 |
| 6 | table |
存储结果集以供以后处理 |
列可能有多个列约束。 例如,users表的username列可以同时具有NOT NULL和UNIQUE约束。
如果约束包含多个列,则使用表约束。 例如,如果表的主键包含两列,则在这种情况下,必须使用PRIMARY KEY表约束。
SQL CREATE TABLE示例
假设需要将员工的培训数据存储在数据库中,并要求每个员工可以接受零或多个培训课程,并且每个培训课程可以由零个或多个员工进行。
在查看了当前数据库后,发现没有地方存储此信息,因此创建一个新的表。
以下语句创建课程表:
CREATE TABLE courses ( course_id INT AUTO_INCREMENT PRIMARY KEY, course_name VARCHAR(50) NOT NULL );
courses表有两列:course_id和course_name。course_id是课程表的主键列。 每个表都有一个且只有一个主键,用于唯一标识表中的每一行。
course_id的数据类型是整数,由INT关键字表示。 此外,course_id列的值为AUTO_INCREMENT。表示当在courses表中插入新行而不提供course_id列的值时,数据库系统将为该列生成一个整数值。course_name存储课程名称。 其数据类型是最大长度为50的字符串(VARCHAR)。NOT NULL约束确保course_name列中不存储NULL值。
现在有了存储课程数据的表。 要存储训练数据,请按如下方式创建名为training的新表。
CREATE TABLE trainings ( employee_id INT, course_id INT, taken_date DATE, PRIMARY KEY (employee_id , course_id) );
trainings表包含三列:
employee_id列存储参加课程的员工的ID。course_id列存储员工所采用的课程。taken_date列存储员工参加课程的日期。
因为trainings表的主键由两列组成:employee_id和course_id,所以必须使用PRIMARY KEY表约束。
在本教程中,您学习了如何使用SQLCREATE TABLE语句在数据库中创建新表。
After Table
本教程介绍如何使用SQLALTER TABLE更改数据库中现有表的结构。
创建新表后,您可能希望更改其结构,因为业务需求会发生变化。 要修改表的结构,请使用ALTER TABLE语句。ALTER TABLE语句用于对现有表执行以下操作:
- 使用
ADD子句添加新列。 - 使用
MODIFY子句修改列的属性,例如:约束,默认值等。 - 使用
DROP子句删除列。
我们将在以下部分详细学习每个操作。
1. SQL ALTER TABLE ADD列
以下语句说明了带有ADD子句的ALTER TABLE,该子句用于向表中添加一个或多个列。
ALTER TABLE table_name ADD new_colum data_type column_constraint [AFTER existing_column];
要向表中添加一个或多个列,需要执行以下步骤:
- 首先,在
ALTER TABLE子句之后指定要添加table_name,表示列所在的表。 - 其次,将新列定义放在
ADD子句之后。 如果要在表中指定新列的顺序,可以使用可选子句AFTER existing_column。
下面来看看如何将一些新列添加到在create table教程中创建的courses表的示例。
以下语句将一个名称为credit_hours的新列添加到courses表中。
ALTER TABLE courses ADD credit_hours INT NOT NULL;
使用单个ALTER TABLE语句向表中添加多个列。 例如,以下语句一次将fee和max_limit列添加到courses表中,并将这些列放在course_name列之后。
ALTER TABLE courses ADD fee NUMERIC (10, 2) AFTER course_name, ADD max_limit INT AFTER course_name;
2. SQL ALTER TABLE MODIFY列
MODIFY子句用于更改现有列的某些属性,例如,NOT NULL,UNIQUE和数据类型。
UNIQUE
在本教程中,将学习如何使用SQLUNIQUE约束强制列或一组列中值的唯一性。
1. 什么是SQL UNIQUE约束
有时,希望确保一列或多列中的值不重复。 例如,employees表中不能接受的重复电子邮件。由于电子邮件列不是主键的一部分,因此防止电子邮件列中重复值的唯一方法是使用UNIQUE约束。
根据定义,SQLUNIQUE约束定义了一个规则,该规则可防止存储在不参与主键的特定列中有重复值。
UNIQUE与PRIMARY KEY约束比较
PRIMARY KEY约束最多只能有一个,而表中可以有多个UNIQUE约束。 如果表中有多个UNIQUE约束,则所有UNIQUE约束必须在不同的列集。
与PRIMARY KEY约束不同,UNIQUE约束允许NULL值。 这取决于RDBMS要考虑NULL值是否唯一。
例如,MySQL将NULL值视为不同的值,因此,可以在参与UNIQUE约束的列中存储多个NULL值。 但是,Microsoft SQL Server或Oracle数据库不是这种情况。
下表说明了UNIQUE约束和PRIMARY KEY约束之间的区别:
| 比较项 | PRIMARY KEY约束 | UNIQUE约束 |
|---|---|---|
| 约束的数量 | 一个 | 多个 |
| NULL值 | 不允许 | 允许 |
2. 创建UNIQUE约束
通常,在创建表时创建UNIQUE约束。 以下CREATE TABLE语句定义users表,其中username列是唯一的。
CREATE TABLE users ( user_id INT AUTO_INCREMENT PRIMARY KEY, username VARCHAR(255) NOT NULL UNIQUE, password VARCHAR(255) NOT NULL );
要为列创建UNIQUE约束,需要在列定义中添加UNIQUE关键字。 在这个示例中,创建了UNIQUE约束作为列约束。
如果插入或更新与username列中已存在的值相同的值,则RDBMS将拒绝更改并返回错误。以下语句等效于使用表约束语法创建的UNIQUE约束的上述语句。
CREATE TABLE users ( user_id INT AUTO_INCREMENT PRIMARY KEY, username VARCHAR(255) NOT NULL, password VARCHAR(255) NOT NULL, CONSTRAINT uc_username UNIQUE (username) );
在这个示例中,将CONSTRAINT子句放在CREATE TABLE语句的末尾。
3. 将UNIQUE约束添加到现有表
如果表已存在,则可以为列添加UNIQUE约束,前提条件是参与UNIQUE约束的列或列组合必须包含唯一值。
假设创建的users表没有为username列定义UNIQUE约束。 要将UNIQUE约束添加到username列,请使用ALTER TABLE语句,如下所示:
ALTER TABLE users ADD CONSTRAINT uc_username UNIQUE(username);
如果要添加新列并为创建UNIQUE约束,请使用以下形式的ALTER TABLE语句。
ALTER TABLE users ADD new_column data_type UNIQUE;
例如,以下语句将带有UNIQUE约束的email列添加到users表。
ALTER TABLE users ADD email VARCHAR(255) UNIQUE;
4. 删除UNIQUE约束
要删除UNIQUE约束,请使用ALTER TABLE语句,如下所示:
ALTER TABLE table_name DROP CONSTRAINT unique_constraint_name;
例如,要删除users表中的uc_username唯一约束,请使用以下语句。
ALTER TABLE users DROP CONSTRAINT uc_username;
在本教程中,我们学习了UNIQUE约束以及如何应用它来强制一列或多列中值的唯一性。
以下语句显示带有MODIFY子句的ALTER TABLE语句的语法。
ALTER TABLE table_name MODIFY column_definition;
请注意,应该修改没有数据的表的列的属性。 因为更改已包含数据的表中列的属性可能会导致永久性数据丢失。
例如,如果列的数据类型为VARCHAR,并且将其更改为INT,则数据库系统必须将数据从VARCHAR转换为INT。 如果转换失败,数据库系统可能会使用列的默认值,这可能与预期不符。
以下ALTER TABLE MODIFY语句将fee列的属性更改为NOT NULL。
ALTER TABLE courses MODIFY fee NUMERIC (10, 2) NOT NULL;
3. SQL ALTER TABLE DROP列
当表的列已过时且未被任何其他数据库对象(如触发器,视图,存储过程和存储过程)使用时,需要将其从表中删除。
要删除一个或多个列,请使用以下语法:
ALTER TABLE table_name DROP column_name, DROP colum_name, ...
例如,要删除courses表中的fee列,请使用以下语句。
ALTER TABLE courses DROP COLUMN fee;
若要同时删除多个列,请使用以逗号(,)分隔的多个DROP COLUMN子句。
例如,以下语句删除courses表中的max_limit和credit_hours。
ALTER TABLE courses DROP COLUMN max_limit, DROP COLUMN credit_hours;
在本教程中,我们逐步学习了如何使用SQLALTER TABLE语句在表中添加,修改和删除一个或多个列。
Drop Table
本教程介绍如何使用SQLDROP TABLE语句删除数据库中的一个或多个表。
1. SQL DROP TABLE语句简介
随着数据库在应用过程不断的数据增加,有时需要从数据库中删除过时的冗余表或不用的表。 要删除表,可使用DROP TABLE语句。
以下是DROP TABLE语句的语法。
DROP TABLE [IF EXISTS] table_name;
要删除现有表,可在DROP TABLE子句后指定表的名称。 如果要删除的表不存在,则数据库系统会发出错误。
为了防止删除不存在的表的错误,使用可选子句IF EXISTS。 如果使用IF EXISTS选项,如果删除一个不存在的表,数据库系统将不会抛出任何错误。 某些数据库系统会发出警告或通知。
DROP TABLE语句永久删除表的数据和结构,某些数据库系统要求表中的记录必须为空时才能从数据库中删除。 这有助于防止意外删除仍在使用的表。
要删除表中的所有数据,可以使用DELETE或TRUNCATE TABLE语句。要删除由另一个表的外键约束引用的表,必须在删除表之前禁用或删除外部约束。
TRUNCATE TABLE
在本教程中,我们来学习如何使用SQLTRUNCATE TABLE语句高效,快速地删除表中的所有数据。
1. SQL TRUNCATE TABLE语句简介
要删除表中的所有数据,可使用不带WHERE子句的DELETE语句。 但是对于具有几百万行的大表,DELETE语句很慢且效率不高。
要快速删除大表中的所有行,使用以下TRUNCATE TABLE语句:
TRUNCATE TABLE table_name;
在此语法中,指定要在TRUNCATE TABLE子句后删除数据的table_name。
某些数据库系统(如MySQL和PostgreSQL)允许直接省略TABLE关键字,因此TRUNCATE TABLE语句如下所示:
TRUNCATE table_name;
发出TRUNCATE TABLE语句时,数据库系统通过取消分配表分配的数据页来删除表中的所有行。 通过这样做,RDBMS可以减少日志记录的资源和需要获取的锁的数量。
如果要一次截断多个表,可以在TRUNCATE TABLE子句后使用逗号分隔的表名列表,如下所示:
TRUNCATE TABLE table_name1, table_name2, ...;
并非所有数据库系统都支持这种使用TRUNCATE TABLE语句来一次删除多个表。 如果不使用,则要发出多个TRUNCATE TABLE语句来截断多个表。
2. SQL TRUNCATE TABLE与DELETE
逻辑上,TRUNCATE TABLE语句和不带WHERE子句的DELETE语句提供了从表中删除所有数据的相同效果。 但是,它们确实存在一些差别:
- 使用
DELETE语句时,数据库系统会记录操作。 通过一些努力,可以回滚已删除的数据。 但是,当使用TRUNCATE TABLE语句时,除非在尚未提交的事务中使用它,否则无法回滚。 - 要从外键约束引用的表中删除数据,不能使用
TRUNCATE TABLE语句。 在这种情况下,必须使用DELETE语句。 - 如果表具有与之关联的触发器,则
TRUNCATE TABLE语句不会触发delete触发器。 - 执行
TRUNCATE TABLE语句后,某些数据库系统会将自动增量列(或标识,序列等)的值重置为其起始值。DELETE语句不是这种情况。 - 带有
WHERE子句的DELETE语句从表中删除部分数据,而TRUNCATE TABLE语句始终从表中删除所有数据。
3. SQL TRUNCATE TABLE示例
下面我们来看一个截断表的例子。
首先,创建一个名为big_table的新表,如下所示:
CREATE TABLE big_table ( id INT AUTO_INCREMENT PRIMARY KEY, val INT );
其次,如果要将样本数据插入big_table表,请多次执行以下语句:
INSERT INTO big_table (val) VALUES (RAND(100000));
请注意,如果使用支持存储过程的数据库系统,则可以将此语句放在循环中。 例如,MySQL中的以下存储过程将数据加载到big_table表中,其中包含num参数指定的行数。
DELIMITER $ CREATE PROCEDURE load_big_table_data(IN num int) BEGIN DECLARE counter int default 0; WHILE counter < num DO INSERT INTO big_table(val) VALUES(RAND(1000000)); END WHILE; END$
以下语句调用load_big_table_data存储过程将999999行数据插入到big_table表。
CALL load_big_table_data(999999)
第三,要删除big_table中所有数据,请使用以下语句:
TRUNCATE TABLE big_table;
如上所见,TRUNCATE TABLE语句的速度有多快。
现在我们已经学习了如何使用TRUNCATE TABLE语句来快速删除大表中的所有数据,并理解TRUNCATE TABLE和DELETE语句之间的差异。
2. SQL DROP TABLE示例
下面创建一个用于练习DROP TABLE语句的新表。
以下语句创建一个名为demo_contacts的新表,用于存储员工的紧急联系人。
CREATE TABLE demo_contacts ( id INT AUTO_INCREMENT PRIMARY KEY, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, relationship VARCHAR(50) NOT NULL, employee_id INT NOT NULL );
以下语句用于删除demo_contacts表:
DROP TABLE demo_contacts;
3. SQL DROP TABLE - 删除多个表
DROP TABLE语句允许同时删除多个表。 为此,需要在DROP TABLE子句之后指定逗号分隔表名称的列表,如下所示:
DROP TABLE table_name1,table_name2,...;
然后,数据库系统逐个删除指定的所有表。
在本教程中,我们已经学习了如何使用SQLDROP TABLE语句删除数据库中的一个或多个表。
Truncate Table
在本教程中,我们来学习如何使用SQLTRUNCATE TABLE语句高效,快速地删除表中的所有数据。
1. SQL TRUNCATE TABLE语句简介
要删除表中的所有数据,可使用不带WHERE子句的DELETE语句。 但是对于具有几百万行的大表,DELETE语句很慢且效率不高。
要快速删除大表中的所有行,使用以下TRUNCATE TABLE语句:
TRUNCATE TABLE table_name;
在此语法中,指定要在TRUNCATE TABLE子句后删除数据的table_name。
某些数据库系统(如MySQL和PostgreSQL)允许直接省略TABLE关键字,因此TRUNCATE TABLE语句如下所示:
TRUNCATE table_name;
发出TRUNCATE TABLE语句时,数据库系统通过取消分配表分配的数据页来删除表中的所有行。 通过这样做,RDBMS可以减少日志记录的资源和需要获取的锁的数量。
如果要一次截断多个表,可以在TRUNCATE TABLE子句后使用逗号分隔的表名列表,如下所示:
TRUNCATE TABLE table_name1, table_name2, ...;
并非所有数据库系统都支持这种使用TRUNCATE TABLE语句来一次删除多个表。 如果不使用,则要发出多个TRUNCATE TABLE语句来截断多个表。
2. SQL TRUNCATE TABLE与DELETE
逻辑上,TRUNCATE TABLE语句和不带WHERE子句的DELETE语句提供了从表中删除所有数据的相同效果。 但是,它们确实存在一些差别:
- 使用
DELETE语句时,数据库系统会记录操作。 通过一些努力,可以回滚已删除的数据。 但是,当使用TRUNCATE TABLE语句时,除非在尚未提交的事务中使用它,否则无法回滚。 - 要从外键约束引用的表中删除数据,不能使用
TRUNCATE TABLE语句。 在这种情况下,必须使用DELETE语句。 - 如果表具有与之关联的触发器,则
TRUNCATE TABLE语句不会触发delete触发器。 - 执行
TRUNCATE TABLE语句后,某些数据库系统会将自动增量列(或标识,序列等)的值重置为其起始值。DELETE语句不是这种情况。 - 带有
WHERE子句的DELETE语句从表中删除部分数据,而TRUNCATE TABLE语句始终从表中删除所有数据。
3. SQL TRUNCATE TABLE示例
下面我们来看一个截断表的例子。
首先,创建一个名为big_table的新表,如下所示:
CREATE TABLE big_table ( id INT AUTO_INCREMENT PRIMARY KEY, val INT );
其次,如果要将样本数据插入big_table表,请多次执行以下语句:
INSERT INTO big_table (val) VALUES (RAND(100000));
请注意,如果使用支持存储过程的数据库系统,则可以将此语句放在循环中。 例如,MySQL中的以下存储过程将数据加载到big_table表中,其中包含num参数指定的行数。
DELIMITER $ CREATE PROCEDURE load_big_table_data(IN num int) BEGIN DECLARE counter int default 0; WHILE counter < num DO INSERT INTO big_table(val) VALUES(RAND(1000000)); END WHILE; END$
以下语句调用load_big_table_data存储过程将999999行数据插入到big_table表。
CALL load_big_table_data(999999)
第三,要删除big_table中所有数据,请使用以下语句:
TRUNCATE TABLE big_table;
如上所见,TRUNCATE TABLE语句的速度有多快。
现在我们已经学习了如何使用TRUNCATE TABLE语句来快速删除大表中的所有数据,并理解TRUNCATE TABLE和DELETE语句之间的差异。
Rename Table
SQLRENAME TABLE用于更改表的名称。 有时,表的名称没有意义或因为一些其它原因需要更改。
重命名数据库中表的语法。
ALTER TABLE table_name RENAME TO new_table_name;
可以编写以下命令来重命名表(可选)。
RENAME old_table _name To new_table_name;
假设有一个名为Students的表,现在由于某种原因想把它改成表名Student_bak。
那么可使用以下任何一种语法来重命名表名:
ALTER TABLE Students RENAME TO Student_bak;
或者 -
RENAME Students TO Student_bak;
之后,表Students将更改为名称为:Student_bak。
复制表
如果要将SQL表复制到同一数据库中的另一个表中,可以使用select语句。
从一个表复制到另一个表的语法如下:
SELECT * INTO <destination_table> FROM <source_table>
例如,可以使用以下语句将hr_employee表的记录复制到employee表中。
SELECT * INTO employee FROM hr_employee;
临时表
临时表的概念由SQL服务器引入的,它以多种方式帮助开发人员。
临时表可以在运行时创建,并且可以像普通表一样执行各种操作。 这些临时表是在tempdb数据库中创建的。
根据行为和范围,有两种类型的临时表。
- 局部临时变量
- 全局临时变量
1. 局部临时变量
局部临时变量表仅在当前连接时可用。 当用户与实例断开连接时,它会自动删除。 它以哈希(#)符号开头。
CREATE TABLE #local temp table ( User_id int, User_name varchar (50), User_address varchar (150) )
2. 全局临时变量
全局临时表名称以双哈希(##)开头。 创建此表后,它就像一个永久表。 它始终为所有用户准备好,并且在撤消总连接之前不会被删除。
CREATE TABLE ##new global temp table ( User_id int, User_name varchar (50), User_address varchar (150) )
Add Column
在本教程中,我们来学习如何使用ALTER TABLE语句的SQLADD COLUMN子句将一个或多个列添加到现有表中。
1. SQL ADD COLUMN子句简介
要向表中添加新列,可使用ALTER TABLE ADD COLUMN语句,如下所示:
ALTER TABLE table_name ADD [COLUMN] column_definition;
在这个声明中,
- 首先,指定要添加新列的表名称。
- 其次,在
ADD COLUMN子句后指定列定义。
列定义的典型语法如下:
column_name data_type constraint;
如果要使用单个语句将多个列添加到现有表,请使用以下语法:
ALTER TABLE table_name ADD [COLUMN] column_definition, ADD [COLUMN] column_definition, ...;
不同的数据库系统支持ALTER TABLE ADD COLUMN语句以及一些小的差异。 请在下一节中查看参考资料。
2. SQL ADD COLUMN示例
以下语句创建一个名为candidate的新表:
CREATE TABLE candidates ( id INT PRIMARY KEY, first_name VARCHAR(100) NOT NULL, last_name VARCHAR(100) NOT NULL, email VARCHAR(255) NOT NULL UNIQUE );
要将phone列添加到candidates表,请使用以下语句:
ALTER TABLE candidates ADD COLUMN phone VARCHAR(50);
要在candidates表中添加三列:home_address,dob和linkedin帐户,请使用以下语句:
ALTER TABLE candidates ADD COLUMN home_address VARCHAR(255), ADD COLUMN dob DATE, ADD COLUMN linkedin_account VARCHAR(255);
3. 一些常见数据库系统中的SQL ADD COLUMN语句
以下部分提供了一些常见数据库系统中ALTER TABLE ADD COLUMN语句的语法。
PostgreSQL
在PostgreSQL中向表中添加一列:
ALTER TABLE table_name ADD COLUMN column_definition;
在PostgreSQL中向表中添加多列:
ALTER TABLE table_name ADD COLUMN column_definition, ADD COLUMN column_definition, ... ADD COLUMN column_definition;
MySQL
在MySQL中的表中添加一列:
ALTER TABLE table_name ADD [COLUMN] column_definition;
在MySQL中向表中添加多列:
ALTER TABLE table_name ADD [COLUMN] column_definition, ADD [COLUMN] column_definition, ... ADD [COLUMN] column_definition;
Oracle
在Oracle中的表中添加一列:
ALTER TABLE table_name ADD column_definition;
在Oracle中向表中添加多列:
ALTER TABLE table_name ADD ( column_definition, column_definition, ... );
SQL Server
在SQL Server中的表中添加一列:
ALTER TABLE table_name ADD column_definition;
在SQL Server中向表中添加多列:
ALTER TABLE table_name ADD column_definition, column_definition, ...;
DB2
在DB2中的表中添加一列:
ALTER TABLE table_name ADD column_definition;
在DB2中向表中添加多列:
ALTER TABLE table_name ADD column_definition column_definition ...;
请注意,列之间没有逗号。
在本教程中,我们学习了如何使用ALTER TABLE语句的SQLADD COLUMN子句,以将一个或多个列添加到现有表中。
Drop Column
在本教程中,我们将学习如何使用SQLDROP COLUMN子句从现有表中删除一个或多个列。
1. SQL DROP COLUMN语句简介
有时,想要从现有表中删除一个或多个未使用的列。 为此,请使用ALTER TABLE,如下所示:
ALTER TABLE table_name DROP COLUMN column_name1, [DROP COLUMN column_name2];
在上面语法中,
table_name是包含要删除列的表名称。column_name1,column_name2是将要删除的列。
MySQL和PostgreSQL支持上述语法。
Oracle和SQL Server的语法略有不同:
ALTER TABLE table_name DROP COLUMN column_name1, [column_name2];
2. SQL DROP COLUMN示例
以下语句为演示创建一个名为persons的新表:
CREATE TABLE persons ( person_id INT PRIMARY KEY, first_name VARCHAR(255) NOT NULL, last_name VARCHAR(255) NOT NULL, date_of_birth DATE NOT NULL, phone VARCHAR(25), email VARCHAR(255) );
2.1. 删除一列示例
以下语句从persons表中删除email列:
ALTER TABLE persons DROP COLUMN email;
2.2. 删除多列示例
以下语句从persons表中删除ate_of_birth和phone列:
ALTER TABLE persons DROP COLUMN date_of_birth, DROP COLUMN phone;
上面语句适用于MySQL和PostgreSQL。对于Oracle和SQL Server,需要使用以下语句:
ALTER TABLE persons DROP COLUMN date_of_birth, phone;
在本教程中,您学习了如何使用SQLDROP COLUMN语句从表中删除一个或多个列。
Insert语句
在本教程中,我们将学习如何使用SQLINSERT语句来将数据插入表中。
1. SQL INSERT语句简介
SQL提供了INSERT语句,用于将一行或多行插入表中。INSERT语句用于:
- 向表中插入一行
- 向表中插入多行
- 将行从一个表复制到另一个表中。
我们将在以下部分中来看看INSERT语句的每个用法。
2.向表中插入一行
要向表中插入一行,请使用INSERT语句的以下语法。
INSERT INTO table1 (column1, column2,...) VALUES (value1, value2,...);
在表中插入新行时,应注意以下几点:
- 首先,值的数量必须与列数相同。 此外,列和值必须是对应的,因为数据库系统将通过它们在列表中的相对位置来匹配它们。
- 其次,在添加新行之前,数据库系统检查所有完整性约束,例如,外键约束,主键约束,检查约束和非空约束。如果违反了其中一个约束,数据库系统将发出错误并终止语句,而不向表中插入任何新行。
我们将使用示例数据库中的employees和dependents表来演示如何向表中插入一行。

要在dependents表中插入新行。参考以下语句 -
INSERT INTO dependents (
first_name,
last_name,
relationship,
employee_id
)VALUES('Max','Su','Child',176);
我们没有在INSERT语句中使用department_id列,因为dependent_id列是自动增量列,因此,当插入新行时,数据库系统使用下一个整数作为默认值。
employee_id列是将dependents表链接到employees表的外键。 在添加新行之前,数据库系统会检查employees表的employee_id列中是否存在值:176,以确保不违反外键约束。
如果成功插入行,则数据库系统返回受影响的行数。
可以使用以下SELECT语句检查是否已成功插入行。
SELECT * FROM dependents WHERE employee_id = 176;
执行上面查询语句,得到以下结果 -
+--------------+------------+-----------+--------------+-------------+ | dependent_id | first_name | last_name | relationship | employee_id | +--------------+------------+-----------+--------------+-------------+ | 31 | Max | Su | Child | 176 | +--------------+------------+-----------+--------------+-------------+ 1 rows in set
3. 向表中插入多行记录
要使用单个INSERT语句插入多行,请使用以下构造:
INSERT INTO table1 VALUES (value1, value2,...), (value1, value2,...), (value1, value2,...), ...;
例如,要在dependents表中插入两行,请使用以下查询。
INSERT INTO dependents ( first_name, last_name, relationship, employee_id ) VALUES ( 'Avg', 'Lee', 'Child', 192 ), ( 'Michelle', 'Lee', 'Child', 192 );
数据库系统返回2行受影响,可以使用以下语句验证结果。
SELECT * FROM dependents WHERE employee_id = 192;
4. 从其他表复制行记录
可以使用INSERT语句查询来自一个或多个表的数据,并将其插入另一个表中,如下所示:
INSERT INTO table1 (column1, column2) SELECT column1, column2 FROM table2 WHERE condition1;
在此语法中,使用SELECT(称为子选择)而不是VALUES子句。 子选择可以包含连接,以便可以组合来自多个表的数据。 执行语句时,数据库系统在插入数据之前首先评估子选择。
假设有一个名为dependents_archive的表,其结构与dependents表具有相同的结构。 以下语句将dependents表中的所有行复制到dependents_archive表中。
INSERT INTO dependents_archive SELECT * FROM dependents;
您可以使用以下语句验证插入操作是否成功 -
SELECT * FROM dependents_archive;
通过上面的示例学习,我们已经知道如何使用SQLINSERT语句将一行或多行插入表中。
insert into Value
有两种方法可以向表中插入值。
第一种方法不需要指定要插入数据的列名,只需要它们的值。
语法
INSERT INTO table_name VALUES (value1, value2, value3....);
第二种方法指定要插入的列名称和值。
语法
INSERT INTO table_name (column1, column2, column3....) VALUES (value1, value2, value3.....);
假设有一个学生表,其结构如下所示:
CREATE TABLE STUDENTS ( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), PRIMARY KEY (ID) );
下面要向这个表中插入五条记录,参考以下语句 -
INSERT INTO STUDENTS (ROLL_NO, NAME, AGE, CITY) VALUES (1, 'ABHIRAM', 22, 'ALLAHABAD'); INSERT INTO STUDENTS (ROLL_NO, NAME, AGE, CITY) VALUES (2, 'ALKA', 20, 'GHAZIABAD'); INSERT INTO STUDENTS (ROLL_NO, NAME, AGE, CITY) VALUES (3, 'DISHA', 21, 'VARANASI'); INSERT INTO STUDENTS (ROLL_NO, NAME, AGE, CITY) VALUES (4, 'ESHA', 21, 'DELHI'); INSERT INTO STUDENTS (ROLL_NO, NAME, AGE, CITY) VALUES (5, 'MANMEET', 23, 'JALANDHAR');
不需要指定列名称,如下所示 -
INSERT INTO STUDENTS VALUES (1, 'ABHIRAM', 22, 'ALLAHABAD'); INSERT INTO STUDENTS VALUES (2, 'ALKA', 20, 'GHAZIABAD'); INSERT INTO STUDENTS VALUES (3, 'DISHA', 21, 'VARANASI'); INSERT INTO STUDENTS VALUES (4, 'ESHA', 21, 'DELHI'); INSERT INTO STUDENTS VALUES (5, 'MANMEET', 23, 'JALANDHAR');
insert into select
通过前面的学习,我们已经知道如何向表中插入单行或单个数据,但是如果要在表中插入多行。 除INSERT INTO外,还将Insert与select语句结合使用。
在此命令中,假设一个表需要使用另一个表中的数据信息来插入。
下面来看看sqlinsert的select语法:
INSERT INTO "table 1" ("column1", "column2",....)
SELECT "column3", "column4",....
FROM "table2";
INSERT INTO语句还可以包含许多子句,如:SELECT,GROUP BY,HAVING以及JOIN和ALIAS。 因此,insert into select语句可能会有些复杂。
示例
假设在数据库中有一个名为sales_data的表,而表store_information包含每天从商店销售的数据记录。 如果要将数据从sales_data移动到store_information怎么做?
应该使用以下语法:
INSERT INTO store (store_name, sales, transaction_date) SELECT store_name, sum (sales), transaction_date FROM sales_information GROUP BY store_name, transaction_date;
插入多行
很多时候开发人员都会问,是否可以在单个语句中将多行插入到一个表中。 目前,开发人员在表中插入值时必须编写多个insert语句。 它不仅枯燥乏味,而且耗时。 要摆脱这一点,应该尝试这种语法。 实际上,有三种不同的方法可以将多个值插入到单个表中。
- 传统方法(简单插入)
- SQL insert select
- SQL server 2008+ 行构建
在SQL Server中插入多个值 -
CREATE TABLE student (ID INT VALUE VARCHAR (100));
SQL INSERT :(传统插入)
INSERT INTO student (ID, NAME) VALUES (1, 'ARMAAN'); INSERT INTO student (ID, NAME) VALUES (2, 'BILLY'); INSERT INTO student (ID, NAME) VALUES (3, 'CHARLIE');
清理表:
TRUNCATE TABLE student;
INSERT SELECT 🙁 SELECT UNION INSERT)
INSERT INTO student (ID, NAME) SELECT 1, 'ARMAAN' UNION ALL SELECT 2, 'BILLY' UNION ALL SELECT 3, 'CHARLIE';
清理表:
TRUNCATE TABLE student;
SQL Server 2008+行构建
INSERT INTO student (ID, NAME) VALUES (1, 'ARMAAN'), (2, 'BILLY'), (3, 'CHARLIE');
Update语句
在本教程中,您将学习如何使用SQLUPDATE语句来修改表中现有行的数据。
1. SQL UPDATE语句简介
要更改表中的现有数据,请使用UPDATE语句。 以下是UPDATE语句的语法:
UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition;
在上面的语法中 -
- 首先,在
UPDATE子句中指明要更新的表。 - 其次,在
SET子句中指定要修改的列。SET子句中未列出的列的值不会被修改。 - 第三,指定
WHERE子句中要更新的行。
UPDATE语句根据WHERE子句中的条件影响表中的一行或多行。 例如,如果WHERE子句包含主键表达式,则UPDATE语句仅更改一行。
但是,将修改WHERE条件评估为true的任何行。 因为WHERE子句是可选的,所以,如果省略它,表中的所有行都将受到影响。
2. SQL UPDATE语句示例
我们将使用employees和dependents表来演示如何使用UPDATE语句。

SQL UPDATE更新一行示例
假设有一个员工编号(employee_id)的值为:192,在employees表中查询数据记录,如下所示 -
mysql> select first_name,last_name from employees where employee_id=192; +------------+-----------+ | first_name | last_name | +------------+-----------+ | Sarah | Yang | +------------+-----------+ 1 row in set
要将last_name字段的值从Yang改为Zhang,请使用以下UPDATE语句:
UPDATE employees SET last_name = 'Zhang' WHERE employee_id = 192;
数据库系统更新了employee_id为192的记录last_name列的值。可以使用以下SELECT语句对其进行验证。
SELECT employee_id, first_name, last_name FROM employees WHERE employee_id = 192;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+ | employee_id | first_name | last_name | +-------------+------------+-----------+ | 192 | Sarah | Zhang | +-------------+------------+-----------+ 1 row in set
SQL UPDATE多行示例
现在,要把所有工资低于2500的员工全部提高到3000,在更新数据之前,让我们先来看看有有哪些工资低于2500的员工。
SELECT employee_id, first_name, last_name,salary FROM employees WHERE salary<3000; +-------------+------------+-----------+--------+ | employee_id | first_name | last_name | salary | +-------------+------------+-----------+--------+ | 116 | Shelli | Zhang | 2900 | | 117 | Sigal | Zhang | 2800 | | 118 | Guy | Zhang | 2600 | | 119 | Karen | Zhang | 2500 | | 126 | Irene | Liu | 2700 | +-------------+------------+-----------+--------+ 5 rows in set
执行以下UPDATE语句,以更新工资为:3000。
UPDATE employees SET salary=3000 WHERE salary<3000;
带有子查询示例的SQL UPDATE
有时,当员工更改姓氏(last_name)时,只更新employees表而不更新dependents表。
要确保子项的姓氏(last_name)始终与employees表中父项的姓氏(last_name)匹配,请使用以下语句:
UPDATE dependents SET last_name = ( SELECT last_name FROM employees WHERE employee_id = dependents.employee_id );
由于省略了WHERE子句,因此UPDATE语句更新了dependents表中的所有行。在SET子句中,我们使用子查询而不是使用文字值来从employees表中获取相应的last_name值。
在本教程中,我们演示了如何使用SQLUPDATE语句来修改表中的现有数据。
Update与Join
SQLUPDATE JOIN可使用一个表和连接条件来更新另一个表。
假设有一个客户表,更新包含来自其他系统的最新客户详细信息的客户表。比如要用最新数据来更新客户表。 在这种情况下,将使用客户ID上的连接在目标表和源表之间执行连接。
下面来看看SQLUPDATE和JOIN语句的查询语法。
UPDATE customer_table INNER JOIN Customer_table ON customer_table.rel_cust_name = customer_table.cust_id SET customer_table.rel_cust_name = customer_table.cust_name
如何在SQL UPDATE语句中使用JOIN使用多个表?
这里使用两个表:table1和table2。
创建table1表 -
CREATE TABLE table1 (column1 INT, column2 INT, column3 VARCHAR (100)); INSERT INTO table1 (column1, column2, column3) SELECT 1, 11, 'FIRST' UNION ALL SELECT 11,12, 'SECOND' UNION ALL SELECT 21, 13, 'THIRD' UNION ALL SELECT 31, 14, 'FOURTH';
创建table2表 -
CREATE TABLE table2 (column1 INT, column2 INT, column3 VARCHAR (100)); INSERT INTO table2 (column1, column2, column3) SELECT 1, 21, 'TWO-ONE' UNION ALL SELECT 11, 22, 'TWO-TWO' UNION ALL SELECT 21, 23, 'TWO-THREE' UNION ALL SELECT 31, 24, 'TWO-FOUR';
接下来,查看表中的内容 -
SELECT * FROM table1;
执行上面示例代码,得到以下结果 -
mysql> SELECT * FROM table1; +---------+---------+---------+ | column1 | column2 | column3 | +---------+---------+---------+ | 1 | 11 | FIRST | | 11 | 12 | SECOND | | 21 | 13 | THIRD | | 31 | 14 | FOURTH | +---------+---------+---------+ 4 rows in set
SELECT * FROM table2;
执行上面示例代码,得到以下结果 -
mysql> SELECT * FROM table2; +---------+---------+-----------+ | column1 | column2 | column3 | +---------+---------+-----------+ | 1 | 21 | TWO-ONE | | 11 | 22 | TWO-TWO | | 21 | 23 | TWO-THREE | | 31 | 24 | TWO-FOUR | +---------+---------+-----------+ 4 rows in set
在table2中有两行:column1的值是21和31,假设想要将table1中的值更新为table2中column1为21和31行的值。
仅更新column2和column3的值。
最简单和最常用的方法是在update语句中使用join子句并在update语句中使用多个表。
UPDATE table1 t1 LEFT JOIN table2 t2 ON t1.column1 = t2.column1 SET t1.column2 = t2.column2, t1.column3 = t2.column3 where t1.column1 in(21,31);
执行以下语句,查看更新结果 -
mysql> select * from table1; +---------+---------+-----------+ | column1 | column2 | column3 | +---------+---------+-----------+ | 1 | 11 | FIRST | | 11 | 12 | SECOND | | 21 | 23 | TWO-THREE | | 31 | 24 | TWO-FOUR | +---------+---------+-----------+ 4 rows in set
更新日期数据
如何在SQL中更新日期和时间字段的值?
如果要在SQL中更新日期和时间字段,则应使用以下查询。下面来看看SQL更新日期的语法。
UPDATE table SET Column_Name = 'YYYY-MM-DD HH:MM:SS' WHERE Id = value
下面来看看一个示例:
首先,使用一个表来演示更新日期和时间字段。如果要更改id为1的行记录,则应编写以下语法:
UPDATE table SET EndDate = '2019-03-16 00:00:00.000' WHERE Id = 1
此查询将更改上面假设表中第一行的日期和时间字段。
Delete语句
在本教程中,您将学习如何使用SQLDELETE语句删除表中的一行或多行。
1. SQL DELETE语句简介
要从表中删除一行或多行,请使用DELETE语句。DELETE语句的一般语法如下:
DELETE FROM table_name WHERE condition;
- 首先,提供要删除行的表名称(
table_name)。 - 其次,在
WHERE子句中指定条件以标识需要删除的行记录。 如果省略WHERE子句,则将删除表中的所有行记录。 因此,应始终谨慎使用DELETE语句。
一般来说,DELETE语句不会将结果集。 但是,它只返回已删除的行数。
2. SQL DELETE语句示例
我们将使用employees和dependents表来演示DELETE语句。

2. SQL删除表中的一行
使用以下DELETE语句从dependents表中删除ID为:16的行记录。
DELETE FROM dependents WHERE dependent_id = 16;
由于WHERE子句包含主键表达式,因此DELETE语句只删除一行。可以使用以下语句验证是否已删除dependents中ID为:16的行记录:
SELECT COUNT(*) FROM dependents WHERE dependent_id = 16;
3. SQL DELETE多行示例
要删除表中的多个行记录,请使用WHERE子句中的条件来选择要删除的行记录。 例如,以下语句使用IN运算符来删除dependents表中id为100,101或102的信息。
DELETE FROM dependents WHERE employee_id IN (100 , 101, 102);
4. SQL DELETE来自相关表的行
一名员工可能有零个或多个家属,而一个受抚养人只属于一名员工。dependents表中的employee_id列链接到employees表中的employee_id列。
员工与家属表之间的关系是一对多的。
从逻辑上讲,如果不引用员工,就不能存在依赖关系。 换句话说,当删除员工信息时,他/她的家属也必须要删除。
例如,要删除员工ID为199和所有员工的依赖项,需要执行两个DELETE语句,如下所示:
DELETE FROM employees WHERE employee_id = 199; DELETE FROM dependents WHERE employee_id = 199;
大多数数据库系统都支持外键约束,因此当删除表中的一行时,外键表中的行也会自动删除。
因此,执行以下DELETE语句时:
DELETE FROM employees WHERE employee_id = 199;
在执行上面语句后,employee_id为199的所有行也会自动删除。
要更有效地从表中删除所有行,可以使用TRUNCATE TABLE语句,而不是使用不带WHERE子句的DELETE语句。
通过上面的示例和学习,您应该了解SQLDELETE语句用法,以及如何应用它来删除表中的一行或多行。
Select语句
在本教程中,您将学习如何使用SQLSELECT语句从单个表中查询数据。
1. SQL SELECT语句简介
要查询表中的数据,请使用SQL SELECT语句。 SELECT语句包含用于选择列,选择行,分组数据,连接表以及执行简单计算的语法。
SELECT语句是SQL中最复杂的命令之一,因此,在本教程中,我们将仅介绍基础知识。
下面说明了从单个表中检索数据的SELECT语句的基本语法。
SELECT column1, column2, column3, ... FROM table_name;
在此语法中,指定查询SELECT子句中的数据是使用逗号分隔列的列表,并在FROM子句中指定表名。 在评估SELECT语句时,数据库系统首先计算FROM子句,然后再计算SELECT子句。
分号(;)不是查询的一部分。 通常,数据库系统使用分号分隔两个SQL查询。 有关更多信息,请查看SQL语法。
如果要查询表的所有列中的数据,可以使用星号(*)运算符而不是列列表,如下所示。
SELECT * FROM table_name;
除了SELECT和FROM子句之外,SELECT语句还可以包含许多其他子句,例如 -
- WHERE - 用于根据指定条件过滤数据
ORDER BY- 用于对结果集进行排序LIMIT- 用于限制返回的行JOIN- 用于查询来自多个相关表的数据GROUP BY- 用于根据一列或多列对数据进行分组HAVING- 用于过滤分组
您将在后续教程中了解这些子句的使用。
2. SQL SELECT语句示例
我们将使用示例数据库中的employees表进行演示。

3. SQL SELECT - 查询所有列示例
要查询表中的所有列,请使用星号(*)而不是指定每列。 例如,以下语句从employees表中检索所有数据:
SELECT * FROM employees;
执行上面示例代码,得到以下结果 -
+-------------+------------+-----------+---------------------------+----------------+------------+--------+--------+------------+---------------+ | employee_id | first_name | last_name | email | phone_number | hire_date | job_id | salary | manager_id | department_id | +-------------+------------+-----------+---------------------------+----------------+------------+--------+--------+------------+---------------+ | 100 | Steven | Lee | steven.lee@yiibai.com | 0532-86011111 | 1987-06-17 | 4 | 24000 | NULL | 9 | | 101 | Neena | Wong | neena.wong@kaops.com | 0551-4243311 | 1989-09-21 | 5 | 17000 | 100 | 9 | | 102 | Lex | Liang | lex.liang@kaops.com | 0571-87622362 | 1993-01-13 | 5 | 17000 | 100 | 9 | | 103 | Alexander | Lee | alexander.lee@kaops.com | 020-95105105 | 1990-01-03 | 9 | 9000 | 102 | 6 | ... ... | 201 | Michael | Zhou | michael.zhou@yiibai.com | 010-67237328 | 1996-02-17 | 10 | 13000 | 100 | 2 | | 202 | Pat | Zhou | pat.zhou@yiibai.com | 0755-28114518 | 1997-08-17 | 11 | 6000 | 201 | 2 | | 203 | Susan | Zhou | susan.zhou@yiibai.com | 0755-83587526 | 1994-06-07 | 8 | 6500 | 101 | 4 | | 204 | Hermann | Wu | hermann.wu@yiibai.com | 0513-83512816 | 1994-06-07 | 12 | 10000 | 101 | 7 | | 205 | Shelley | Wu | shelley.wu@yiibai.com | 0898-31686222 | 1994-06-07 | 2 | 12000 | 101 | 11 | | 206 | William | Wu | william.wu@yiibai.com | 022-26144822 | 1994-06-07 | 1 | 8300 | 205 | 11 | +-------------+------------+-----------+---------------------------+----------------+------------+--------+--------+------------+---------------+ 40 rows in set
使用星号(*)运算符只能方便地通过SQL客户端应用程序以交互方式查询数据。 但是,如果在应用程序的嵌入语句中使用星号(*)运算符,则可能存在一些潜在问题。
首先,因为表的结构将发展以适应新的业务需求,例如,可以添加新列并删除现有列。 如果使用星号(*)运算符并且未更改应用程序代码以使其与新表结构一起使用,则应用程序可能无法正常运行。
星号(*)运算符的另一个问题是它可能会增加数据库服务器和应用程序之间传输的不必要数据,因为应用程序可能只需要表的部分数据。
4. SQL SELECT - 查询特定列
SELECT语句用于准确指定要以任何顺序检索数据的列,它不必按表中定义的顺序排列。
例如,如果想要查看所有员工的员工ID,名字,姓氏和雇用日期,则使用以下查询:
SELECT employee_id, first_name, last_name, hire_date FROM employees;
请注意,结果集仅包含SELECT子句中指定的四列。如下所示 -
+-------------+------------+-----------+------------+ | employee_id | first_name | last_name | hire_date | +-------------+------------+-----------+------------+ | 100 | Steven | Lee | 1987-06-17 | | 101 | Neena | Wong | 1989-09-21 | | 102 | Lex | Liang | 1993-01-13 | | 103 | Alexander | Lee | 1990-01-03 | ... ... | 202 | Pat | Zhou | 1997-08-17 | | 203 | Susan | Zhou | 1994-06-07 | | 204 | Hermann | Wu | 1994-06-07 | | 205 | Shelley | Wu | 1994-06-07 | | 206 | William | Wu | 1994-06-07 | +-------------+------------+-----------+------------+ 40 rows in set
5. SQL SELECT - 执行简单的计算
如前所述,SELECT语句用于执行简单的计算。 例如,以下查询使用FLOOR(),DATEDIFF()和CURRENT_DATE函数计算员工的服务年份。要计算服务年份,将DATEDIFF()函数的结果除以365。FLOOR()函数返回小于或等于数值表达式结果的最大整数。YoS是下面表达式的列别名,用于在返回的结果集中显示用户友好的标题。
FLOOR(DATEDIFF(NOW(), hire_date) / 365)
完整的写法如下所示 -
SELECT employee_id, first_name, last_name, FLOOR(DATEDIFF(NOW(), hire_date) / 365) AS YoS FROM employees;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+-----+ | employee_id | first_name | last_name | YoS | +-------------+------------+-----------+-----+ | 100 | Steven | Lee | 31 | | 101 | Neena | Wong | 29 | | 102 | Lex | Liang | 26 | | 103 | Alexander | Lee | 29 | | 104 | Bruce | Wong | 27 | | 105 | David | Liang | 21 | | 106 | Valli | Chen | 20 | | 107 | Diana | Chen | 19 | | 108 | Nancy | Chen | 24 | ... ... | 203 | Susan | Zhou | 24 | | 204 | Hermann | Wu | 24 | | 205 | Shelley | Wu | 24 | | 206 | William | Wu | 24 | +-------------+------------+-----------+-----+ 40 rows in set
此查询适用于MySQL。 如果使用SQL Server,则可以使用以下查询:
SELECT employee_id, first_name, last_name, DATEDIFF(year, hire_date,CURRENT_TIMESTAMP) FROM employees;
通过上面示例和学习,您应该知道如何使用SQLSELECT语句从单个表中查询数据。
Order By排序
本教程将演示如何使用SQLORDER BY子句根据指定的标准按升序或降序对结果集进行排序。
1. SQL ORDER BY子句简介
当使用SELECT语句查询表中的数据时,结果集中显示的行的顺序可能与您的预期不符。
在某些情况下,结果集中显示的行按其物理存储在表中的顺序排列。 但是,如果查询优化器使用索引来处理查询,则行记录将显示为它们以索引键顺序存储。 因此,结果集中的行顺序未确定或不可预测。
查询优化器是数据库系统中的内置软件组件,用于确定SQL语句查询请求数据的最有效方式。
要准确指定结果集中的行顺序,请在SELECT语句中添加使用ORDER BY子句,如下所示:
SELECT column1, column2 FROM table_name ORDER BY column1 ASC , column2 DESC;
在此语法中,ORDER BY子句放在FROM子句之后。 如果SELECT语句包含WHERE子句,则ORDER BY子句必须放在WHERE子句之后。
要对结果集进行排序,请指定要排序的列以及排序顺序的类型:
- 升序(使用:
ASC表示) - 降序(使用:
DESC表示)
如果未指定排序顺序,则数据库系统通常默认按升序(ASC)对结果集进行排序。
当在ORDER BY子句中包含多个列时,数据库系统首先根据第一列对结果集进行排序,然后根据第二列对排序的结果集进行排序,依此类推。
2. SQL ORDER BY子句示例
我们将使用示例数据库中的employees表进行演示。
SELECT employee_id, first_name, last_name, hire_date, salary FROM employees;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+------------+--------+ | employee_id | first_name | last_name | hire_date | salary | +-------------+------------+-----------+------------+--------+ | 100 | Steven | Lee | 1987-06-17 | 24000 | | 101 | Neena | Wong | 1989-09-21 | 17000 | | 102 | Lex | Liang | 1993-01-13 | 17000 | | 103 | Alexander | Lee | 1990-01-03 | 9000 | | 104 | Bruce | Wong | 1991-05-21 | 6000 | | 105 | David | Liang | 1997-06-25 | 4800 | | 106 | Valli | Chen | 1998-02-05 | 4800 | | 107 | Diana | Chen | 1999-02-07 | 4200 | ... ... | 200 | Jennifer | Zhao | 1987-09-17 | 4400 | | 201 | Michael | Zhou | 1996-02-17 | 13000 | | 202 | Pat | Zhou | 1997-08-17 | 6000 | | 203 | Susan | Zhou | 1994-06-07 | 6500 | | 204 | Hermann | Wu | 1994-06-07 | 10000 | | 205 | Shelley | Wu | 1994-06-07 | 12000 | | 206 | William | Wu | 1994-06-07 | 8300 | +-------------+------------+-----------+------------+--------+ 40 rows in set
似乎行记录显示为存储在employees表中顺序。 要按字母顺序按名字对员工进行排序,请按如下方式添加ORDER BY子句进行查询:
SELECT employee_id, first_name, last_name, hire_date, salary FROM employees ORDER BY first_name;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+------------+--------+ | employee_id | first_name | last_name | hire_date | salary | +-------------+------------+-----------+------------+--------+ | 103 | Alexander | Lee | 1990-01-03 | 9000 | | 115 | Alexander | Su | 1995-05-18 | 3100 | | 114 | Avg | Su | 1994-12-07 | 11000 | | 193 | Britney | Zhao | 1997-03-03 | 3900 | | 104 | Bruce | Wong | 1991-05-21 | 6000 | ... ... | 117 | Sigal | Zhang | 1997-07-24 | 3000 | | 100 | Steven | Lee | 1987-06-17 | 24000 | | 203 | Susan | Zhou | 1994-06-07 | 6500 | | 106 | Valli | Chen | 1998-02-05 | 4800 | | 206 | William | Wu | 1994-06-07 | 8300 | +-------------+------------+-----------+------------+--------+ 40 rows in set
现在,结果集按first_name列的值的字母顺序进行排序。
3. SQL ORDER BY - 按多列排序示例
要将员工按名字(first_name)列升序排列,然后再按姓氏(last_name)降序排序,请使用以下语句:
SELECT employee_id, first_name, last_name, hire_date, salary FROM employees ORDER BY first_name, last_name DESC;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+------------+--------+ | employee_id | first_name | last_name | hire_date | salary | +-------------+------------+-----------+------------+--------+ | 115 | Alexander | Su | 1995-05-18 | 3100 | | 103 | Alexander | Lee | 1990-01-03 | 9000 | | 114 | Avg | Su | 1994-12-07 | 11000 | | 193 | Britney | Zhao | 1997-03-03 | 3900 | | 104 | Bruce | Wong | 1991-05-21 | 6000 | | 179 | Charles | Yang | 2000-01-04 | 6200 | ... ... | 113 | Min | Su | 1999-12-07 | 6900 | | 122 | Min | Liu | 1995-05-01 | 7900 | | 108 | Nancy | Chen | 1994-08-17 | 12000 | | 101 | Neena | Wong | 1989-09-21 | 17000 | | 202 | Pat | Zhou | 1997-08-17 | 6000 | | 192 | Sarah | Zhang | 1996-02-04 | 4000 | | 123 | Shanta | Liu | 1997-10-10 | 6500 | | 205 | Shelley | Wu | 1994-06-07 | 12000 | | 116 | Shelli | Zhang | 1997-12-24 | 3000 | | 117 | Sigal | Zhang | 1997-07-24 | 3000 | | 100 | Steven | Lee | 1987-06-17 | 24000 | | 203 | Susan | Zhou | 1994-06-07 | 6500 | | 106 | Valli | Chen | 1998-02-05 | 4800 | | 206 | William | Wu | 1994-06-07 | 8300 | +-------------+------------+-----------+------------+--------+ 40 rows in set
首先,数据库系统按升序对第一列(first_name)的结果集进行排序,然后按降序对按姓氏(last_name)排序的排序结果进行排序。 请注意两名员工:Alexander Su和Alexander Lee的位置变化。
4. SQL ORDER BY - 按数字列示例排序
SQL用于按字母顺序对数据进行排序,如上例所示,并以数字方式对数据进行排序。 例如,以下语句选择员工数据,并按降序对薪水(salary)列结果进行排序:
SELECT employee_id, first_name, last_name, hire_date, salary FROM employees ORDER BY salary DESC;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+------------+--------+ | employee_id | first_name | last_name | hire_date | salary | +-------------+------------+-----------+------------+--------+ | 100 | Steven | Lee | 1987-06-17 | 24000 | | 101 | Neena | Wong | 1989-09-21 | 17000 | | 102 | Lex | Liang | 1993-01-13 | 17000 | | 145 | John | Liu | 1996-10-01 | 14000 | | 146 | Karen | Liu | 1997-01-05 | 13500 | | 201 | Michael | Zhou | 1996-02-17 | 13000 | | 108 | Nancy | Chen | 1994-08-17 | 12000 | | 205 | Shelley | Wu | 1994-06-07 | 12000 | ... ... | 193 | Britney | Zhao | 1997-03-03 | 3900 | | 115 | Alexander | Su | 1995-05-18 | 3100 | | 116 | Shelli | Zhang | 1997-12-24 | 2900 | | 117 | Sigal | Zhang | 1997-07-24 | 2800 | | 126 | Irene | Liu | 1998-09-28 | 2700 | | 118 | Guy | Zhang | 1998-11-15 | 2600 | | 119 | Karen | Zhang | 1999-08-10 | 2500 | +-------------+------------+-----------+------------+--------+ 40 rows in set
5. SQL ORDER BY - 按日期排序示例
除了字符和数字,SQL还可以按日期对结果集进行排序。 以下语句按hire_date列中的值按升序对员工进行排序。
SELECT employee_id, first_name, last_name, hire_date, salary FROM employees ORDER BY hire_date;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+------------+--------+ | employee_id | first_name | last_name | hire_date | salary | +-------------+------------+-----------+------------+--------+ | 100 | Steven | Lee | 1987-06-17 | 24000 | | 200 | Jennifer | Zhao | 1987-09-17 | 4400 | | 101 | Neena | Wong | 1989-09-21 | 17000 | | 103 | Alexander | Lee | 1990-01-03 | 9000 | | 104 | Bruce | Wong | 1991-05-21 | 6000 | | 102 | Lex | Liang | 1993-01-13 | 17000 | | 204 | Hermann | Wu | 1994-06-07 | 10000 | ...... | 107 | Diana | Chen | 1999-02-07 | 4200 | | 178 | Kimberely | Yang | 1999-05-24 | 7000 | | 119 | Karen | Zhang | 1999-08-10 | 2500 | | 113 | Min | Su | 1999-12-07 | 6900 | | 179 | Charles | Yang | 2000-01-04 | 6200 | +-------------+------------+-----------+------------+--------+ 40 rows in set
要查看刚刚加入公司的最新员工,可以按雇用日期(hire_date)的降序对员工进行排序,如下面的语句所示:
SELECT employee_id, first_name, last_name, hire_date, salary FROM employees ORDER BY hire_date DESC;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+------------+--------+ | employee_id | first_name | last_name | hire_date | salary | +-------------+------------+-----------+------------+--------+ | 179 | Charles | Yang | 2000-01-04 | 6200 | | 113 | Min | Su | 1999-12-07 | 6900 | | 119 | Karen | Zhang | 1999-08-10 | 2500 | | 178 | Kimberely | Yang | 1999-05-24 | 7000 | ...... | 104 | Bruce | Wong | 1991-05-21 | 6000 | | 103 | Alexander | Lee | 1990-01-03 | 9000 | | 101 | Neena | Wong | 1989-09-21 | 17000 | | 200 | Jennifer | Zhao | 1987-09-17 | 4400 | | 100 | Steven | Lee | 1987-06-17 | 24000 | +-------------+------------+-----------+------------+--------+ 40 rows in set
在本教程中,您学习了如何使用SQLORDER BY子句根据一个或多个列的升序或降序来对结果集进行排序。
DISTINCT运算符
在本教程中,我们将学习如何使用SQLDISTINCT运算符从结果集中删除重复数据项。
1. SQL DISTINCT运算符简介
主键确保表没有重复的行。 但是,当您使用SELECT语句查询表中的一部分列时,可能会得到重复数据项。
要从结果集中删除重复数据项,请在SELECT子句中插入DISTINCT运算符,如下所示:
SELECT DISTINCT column1, column2, ... FROM table1;
如果在DISTINCT运算符后使用一列,则数据库系统使用该列来计算重复。 如果使用两列或更多列,数据库系统将使用这些列的组合进行重复检查。
要删除重复项,数据库系统首先按SELECT子句中指定的每个列对结果集进行排序。 然后,它从上到下扫描表,以识别彼此相邻的重复项。 如果结果集很大,则排序和扫描操作可能会降低查询的性能。
2. SQL DISTINCT示例
我们将使用示例数据库中的employees表来演示DISTINCT运算符的工作原理。

3. SQL DISTINCT一列示例
以下语句从employees表中检索薪水数据,并按降序对其进行排序。
SELECT salary FROM employees ORDER BY salary DESC;
执行上面查询语句,得到以下结果 -
+--------+ | salary | +--------+ | 24000 | | 17000 | | 17000 | | 14000 | | 13500 | | 13000 | ... ...
如上所见,有重复的薪资数据,例如17,000,因为两个或更多员工的薪水相同。 要删除重复项,请将DISTINCT运算符添加到SELECT子句,如下所示:
SELECT DISTINCT salary FROM employees ORDER BY salary DESC;
执行上面查询语句,得到以下结果 -
+--------+ | salary | +--------+ | 24000 | | 17000 | | 14000 | | 13500 | | 13000 | | 12000 | ... ...
现在,从结果集中删除所有重复项。
4. SQL DISTINCT多列示例
以下语句从employees表中检索job_id和salary列的数据。
SELECT job_id, salary FROM employees ORDER BY job_id, salary DESC;
执行上面查询语句,得到以下结果 -
+--------+--------+ | job_id | salary | +--------+--------+ | 1 | 8300 | | 2 | 12000 | | 3 | 4400 | | 4 | 24000 | | 5 | 17000 | | 5 | 17000 | ... ...
上面查询结果集中,有两行记录相同:job_id是5和salary是17000两行记录。
现在,如果将DISTINCT运算符添加到SELECT子句,则数据库系统将使用job_id和salary列中的值来计算重复项。 它只保留一个行记录,如上面的屏幕截图所示。
SELECT DISTINCT job_id, salary FROM employees ORDER BY job_id, salary DESC;
执行上面查询语句,得到以下结果 -
+--------+--------+ | job_id | salary | +--------+--------+ | 1 | 8300 | | 2 | 12000 | | 3 | 4400 | | 4 | 24000 | | 5 | 17000 | | 6 | 9000 | | 6 | 8200 | ......
5. SQL DISTINCT和NULL值
NULL值在SQL中是一个特别的值。 它在某些情况下用作标记,比如:缺少信息或信息不适用。 因此,NULL无法与任何值进行比较。 即使NULL也不等于它自己。 如果列中有两个或多个NULL值,数据库系统是否将它们视为相同或不同的值?
NULL
在本教程中,我们将介绍NULL概念,并演示如何使用SQLIS NULL和IS NOT NULL运算符来测试表达式是否为NULL。
1. 什么是NULL?
NULL在SQL中很特殊。NULL表示数据未知的值,可以简单理解为表示:不适用或不存在的值。 换句话说,NULL表示数据库中缺少数据。
例如,如果员工没有任何电话号码,可以将其存储为空字符串。 但是,如果在插入员工记录时不知道他的电话号码,我们将使用未知电话号码的NULL值。
NULL值是特殊的,因为任何与NULL值的比较都不会导致true或false,但在第三个逻辑结果中:未知。
以下语句返回null值。
SELECT NULL = 5;
NULL值甚至不等于自身,如以下语句所示。
SELECT NULL = NULL;
在此示例中,结果为NULL值。
不能使用比较运算符的等于(=)将值与NULL值进行比较。 例如,以下语句将不会产生正确的结果。
SELECT employee_id, first_name, last_name, phone_number FROM employees WHERE phone_number = NULL;
2. IS NULL 和 IS NOT NULL 运算符
要确定表达式或列的值是否为NULL,请使用IS NULL运算符,如下所示:
expression IS NULL;
如果表达式的结果为NULL,则IS NULL运算符返回true; 否则它返回false。要检查表达式或列是否不为NULL,请使用IS NOT运算符:
expression IS NOT NULL;
如果表达式的值为NULL,则IS NOT NULL返回false; 否则它返回true;
3. SQL IS NULL和IS NOT NULL示例
在这些示例中,我们将使用示例数据库中的employees表进行演示。
mysql> DESC employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
要查找没有电话号码的所有员工,请使用IS NULL运算符,如下所示:

要查找具有电话号码的所有员工,请使用IS NOT NULL,如以下语句所示:
SELECT employee_id, first_name, last_name, phone_number FROM employees WHERE phone_number IS NOT NULL;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+----------------+ | employee_id | first_name | last_name | phone_number | +-------------+------------+-----------+----------------+ | 100 | Steven | Lee | 0532-86011111 | | 101 | Neena | Wong | 0551-4243311 | | 102 | Lex | Liang | 0571-87622362 | | 103 | Alexander | Lee | 020-95105105 | | 104 | Bruce | Wong | 0371-68356666 | | 105 | David | Liang | 0512-67513131 | | 106 | Valli | Chen | 0535-95105175 | | 107 | Diana | Chen | 025-95105105 | | 108 | Nancy | Chen | 0531-86012520 | | 109 | Daniel | Chen | 021-8008207890 | ... ... | 201 | Michael | Zhou | 010-67237328 | | 202 | Pat | Zhou | 0755-28114518 | | 203 | Susan | Zhou | 0755-83587526 | | 204 | Hermann | Wu | 0513-83512816 | | 205 | Shelley | Wu | 0898-31686222 | | 206 | William | Wu | 022-26144822 | +-------------+------------+-----------+----------------+ 34 rows in set
通过本小节的学习,现在您应该了解NULL概念并知道如何使用SQLIS NULL运算符来检查值是否为NULL值。
通常,DISTINCT运算符将所有NULL值视为相同的值。 因此在结果集中,DISTINCT运算符只保留一个NULL值,并从结果集中删除其它的NULL值。
以下语句返回员工的不同电话号码。
SELECT DISTINCT phone_number FROM employees;
执行上面查询语句,得到以下结果 -
+----------------+ | phone_number | +----------------+ | 0532-86011111 | | 0551-4243311 | | 0571-87622362 | ...... | NULL | | 0351-2233611 | | 021-66050000 | | 010-67237328 | | 0755-28114518 | | 0755-83587526 | | 0513-83512816 | | 0898-31686222 | | 022-26144822 | +----------------+ 34 rows in set
请注意,它只返回一个NULL值。
在本教程中,您学习了如何使用DISTINCT运算符从结果集中删除重复的行。
Limit子句
本教程我们将演示如何使用SQLLIMIT子句来限制SELECT语句返回的行数。
1. SQL LIMIT子句简介
要检索查询返回的行的一部分,请使用LIMIT和OFFSET子句。 以下说明了这些子句的语法:
SELECT column_list FROM table1 ORDER BY column_list LIMIT row_count OFFSET offset;
在这个语法中,
row_count确定将返回的行数。OFFSET子句在开始返回行之前跳过偏移行。OFFSET子句是可选的。 如果同时使用LIMIT和OFFSET子句,OFFSET会在LIMIT约束行数之前先跳过偏移行。
在使用LIMIT子句时,使用ORDER BY子句确保返回的行按指定顺序非常重要。

并非所有数据库系统都支持LIMIT子句,因此,LIMIT子句仅在某些数据库系统中可用,例如MySQL,PostgreSQL,SQLite,Sybase SQL Anywhere和HSQLDB。
1. SQL LIMIT子句示例
我们将使用示例数据库中的employees表来演示LIMIT子句用法。

以下语句返回employees表中按first_name列排序的所有行。
SELECT employee_id, first_name, last_name FROM employees ORDER BY first_name;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+ | employee_id | first_name | last_name | +-------------+------------+-----------+ | 103 | Alexander | Lee | | 115 | Alexander | Su | | 114 | Avg | Su | | 193 | Britney | Zhao | | 104 | Bruce | Wong | ... ... | 100 | Steven | Lee | | 203 | Susan | Zhou | | 106 | Valli | Chen | | 206 | William | Wu | +-------------+------------+-----------+ 40 rows in set
如果要只返回前5行,请使用LIMIT子句,如以下语句。
SELECT employee_id, first_name, last_name FROM employees ORDER BY first_name LIMIT 5;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+ | employee_id | first_name | last_name | +-------------+------------+-----------+ | 115 | Alexander | Su | | 103 | Alexander | Lee | | 114 | Avg | Su | | 193 | Britney | Zhao | | 104 | Bruce | Wong | +-------------+------------+-----------+ 5 rows in set
要跳过两行并获取接下来的五行,请使用LIMIT和OFFSET子句,如以下语句所示。
SELECT employee_id, first_name, last_name FROM employees ORDER BY first_name LIMIT 5 OFFSET 3;
结果如下图所示 -

如果使用的是MySQL,则可以使用LIMIT OFFSET子句的较短形式。
SELECT employee_id, first_name, last_name FROM employees ORDER BY first_name LIMIT 3 , 5;
2. 使用SQL LIMIT获取具有最高或最低值的前N行
可以使用LIMIT子句获取具有最高或最低值的前N行。 例如,以下声明获得薪资最高的前五名员工。
SELECT employee_id, first_name, last_name, salary FROM employees ORDER BY salary DESC LIMIT 5;
执行上面示例代码,得到以下结果 -

首先,ORDER BY子句按工资按降序对员工进行排序,然后LIMIT子句限制从查询返回的五行。
ORDER BY
本教程将演示如何使用SQLORDER BY子句根据指定的标准按升序或降序对结果集进行排序。
1. SQL ORDER BY子句简介
当使用SELECT语句查询表中的数据时,结果集中显示的行的顺序可能与您的预期不符。
在某些情况下,结果集中显示的行按其物理存储在表中的顺序排列。 但是,如果查询优化器使用索引来处理查询,则行记录将显示为它们以索引键顺序存储。 因此,结果集中的行顺序未确定或不可预测。
查询优化器是数据库系统中的内置软件组件,用于确定SQL语句查询请求数据的最有效方式。
要准确指定结果集中的行顺序,请在SELECT语句中添加使用ORDER BY子句,如下所示:
SELECT column1, column2 FROM table_name ORDER BY column1 ASC , column2 DESC;
在此语法中,ORDER BY子句放在FROM子句之后。 如果SELECT语句包含WHERE子句,则ORDER BY子句必须放在WHERE子句之后。
要对结果集进行排序,请指定要排序的列以及排序顺序的类型:
- 升序(使用:
ASC表示) - 降序(使用:
DESC表示)
如果未指定排序顺序,则数据库系统通常默认按升序(ASC)对结果集进行排序。
当在ORDER BY子句中包含多个列时,数据库系统首先根据第一列对结果集进行排序,然后根据第二列对排序的结果集进行排序,依此类推。
2. SQL ORDER BY子句示例
我们将使用示例数据库中的employees表进行演示。
SELECT employee_id, first_name, last_name, hire_date, salary FROM employees;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+------------+--------+ | employee_id | first_name | last_name | hire_date | salary | +-------------+------------+-----------+------------+--------+ | 100 | Steven | Lee | 1987-06-17 | 24000 | | 101 | Neena | Wong | 1989-09-21 | 17000 | | 102 | Lex | Liang | 1993-01-13 | 17000 | | 103 | Alexander | Lee | 1990-01-03 | 9000 | | 104 | Bruce | Wong | 1991-05-21 | 6000 | | 105 | David | Liang | 1997-06-25 | 4800 | | 106 | Valli | Chen | 1998-02-05 | 4800 | | 107 | Diana | Chen | 1999-02-07 | 4200 | ... ... | 200 | Jennifer | Zhao | 1987-09-17 | 4400 | | 201 | Michael | Zhou | 1996-02-17 | 13000 | | 202 | Pat | Zhou | 1997-08-17 | 6000 | | 203 | Susan | Zhou | 1994-06-07 | 6500 | | 204 | Hermann | Wu | 1994-06-07 | 10000 | | 205 | Shelley | Wu | 1994-06-07 | 12000 | | 206 | William | Wu | 1994-06-07 | 8300 | +-------------+------------+-----------+------------+--------+ 40 rows in set
似乎行记录显示为存储在employees表中顺序。 要按字母顺序按名字对员工进行排序,请按如下方式添加ORDER BY子句进行查询:
SELECT employee_id, first_name, last_name, hire_date, salary FROM employees ORDER BY first_name;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+------------+--------+ | employee_id | first_name | last_name | hire_date | salary | +-------------+------------+-----------+------------+--------+ | 103 | Alexander | Lee | 1990-01-03 | 9000 | | 115 | Alexander | Su | 1995-05-18 | 3100 | | 114 | Avg | Su | 1994-12-07 | 11000 | | 193 | Britney | Zhao | 1997-03-03 | 3900 | | 104 | Bruce | Wong | 1991-05-21 | 6000 | ... ... | 117 | Sigal | Zhang | 1997-07-24 | 3000 | | 100 | Steven | Lee | 1987-06-17 | 24000 | | 203 | Susan | Zhou | 1994-06-07 | 6500 | | 106 | Valli | Chen | 1998-02-05 | 4800 | | 206 | William | Wu | 1994-06-07 | 8300 | +-------------+------------+-----------+------------+--------+ 40 rows in set
现在,结果集按first_name列的值的字母顺序进行排序。
3. SQL ORDER BY - 按多列排序示例
要将员工按名字(first_name)列升序排列,然后再按姓氏(last_name)降序排序,请使用以下语句:
SELECT employee_id, first_name, last_name, hire_date, salary FROM employees ORDER BY first_name, last_name DESC;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+------------+--------+ | employee_id | first_name | last_name | hire_date | salary | +-------------+------------+-----------+------------+--------+ | 115 | Alexander | Su | 1995-05-18 | 3100 | | 103 | Alexander | Lee | 1990-01-03 | 9000 | | 114 | Avg | Su | 1994-12-07 | 11000 | | 193 | Britney | Zhao | 1997-03-03 | 3900 | | 104 | Bruce | Wong | 1991-05-21 | 6000 | | 179 | Charles | Yang | 2000-01-04 | 6200 | ... ... | 113 | Min | Su | 1999-12-07 | 6900 | | 122 | Min | Liu | 1995-05-01 | 7900 | | 108 | Nancy | Chen | 1994-08-17 | 12000 | | 101 | Neena | Wong | 1989-09-21 | 17000 | | 202 | Pat | Zhou | 1997-08-17 | 6000 | | 192 | Sarah | Zhang | 1996-02-04 | 4000 | | 123 | Shanta | Liu | 1997-10-10 | 6500 | | 205 | Shelley | Wu | 1994-06-07 | 12000 | | 116 | Shelli | Zhang | 1997-12-24 | 3000 | | 117 | Sigal | Zhang | 1997-07-24 | 3000 | | 100 | Steven | Lee | 1987-06-17 | 24000 | | 203 | Susan | Zhou | 1994-06-07 | 6500 | | 106 | Valli | Chen | 1998-02-05 | 4800 | | 206 | William | Wu | 1994-06-07 | 8300 | +-------------+------------+-----------+------------+--------+ 40 rows in set
首先,数据库系统按升序对第一列(first_name)的结果集进行排序,然后按降序对按姓氏(last_name)排序的排序结果进行排序。 请注意两名员工:Alexander Su和Alexander Lee的位置变化。
4. SQL ORDER BY - 按数字列示例排序
SQL用于按字母顺序对数据进行排序,如上例所示,并以数字方式对数据进行排序。 例如,以下语句选择员工数据,并按降序对薪水(salary)列结果进行排序:
SELECT employee_id, first_name, last_name, hire_date, salary FROM employees ORDER BY salary DESC;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+------------+--------+ | employee_id | first_name | last_name | hire_date | salary | +-------------+------------+-----------+------------+--------+ | 100 | Steven | Lee | 1987-06-17 | 24000 | | 101 | Neena | Wong | 1989-09-21 | 17000 | | 102 | Lex | Liang | 1993-01-13 | 17000 | | 145 | John | Liu | 1996-10-01 | 14000 | | 146 | Karen | Liu | 1997-01-05 | 13500 | | 201 | Michael | Zhou | 1996-02-17 | 13000 | | 108 | Nancy | Chen | 1994-08-17 | 12000 | | 205 | Shelley | Wu | 1994-06-07 | 12000 | ... ... | 193 | Britney | Zhao | 1997-03-03 | 3900 | | 115 | Alexander | Su | 1995-05-18 | 3100 | | 116 | Shelli | Zhang | 1997-12-24 | 2900 | | 117 | Sigal | Zhang | 1997-07-24 | 2800 | | 126 | Irene | Liu | 1998-09-28 | 2700 | | 118 | Guy | Zhang | 1998-11-15 | 2600 | | 119 | Karen | Zhang | 1999-08-10 | 2500 | +-------------+------------+-----------+------------+--------+ 40 rows in set
5. SQL ORDER BY - 按日期排序示例
除了字符和数字,SQL还可以按日期对结果集进行排序。 以下语句按hire_date列中的值按升序对员工进行排序。
SELECT employee_id, first_name, last_name, hire_date, salary FROM employees ORDER BY hire_date;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+------------+--------+ | employee_id | first_name | last_name | hire_date | salary | +-------------+------------+-----------+------------+--------+ | 100 | Steven | Lee | 1987-06-17 | 24000 | | 200 | Jennifer | Zhao | 1987-09-17 | 4400 | | 101 | Neena | Wong | 1989-09-21 | 17000 | | 103 | Alexander | Lee | 1990-01-03 | 9000 | | 104 | Bruce | Wong | 1991-05-21 | 6000 | | 102 | Lex | Liang | 1993-01-13 | 17000 | | 204 | Hermann | Wu | 1994-06-07 | 10000 | ...... | 107 | Diana | Chen | 1999-02-07 | 4200 | | 178 | Kimberely | Yang | 1999-05-24 | 7000 | | 119 | Karen | Zhang | 1999-08-10 | 2500 | | 113 | Min | Su | 1999-12-07 | 6900 | | 179 | Charles | Yang | 2000-01-04 | 6200 | +-------------+------------+-----------+------------+--------+ 40 rows in set
要查看刚刚加入公司的最新员工,可以按雇用日期(hire_date)的降序对员工进行排序,如下面的语句所示:
SELECT employee_id, first_name, last_name, hire_date, salary FROM employees ORDER BY hire_date DESC;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+------------+--------+ | employee_id | first_name | last_name | hire_date | salary | +-------------+------------+-----------+------------+--------+ | 179 | Charles | Yang | 2000-01-04 | 6200 | | 113 | Min | Su | 1999-12-07 | 6900 | | 119 | Karen | Zhang | 1999-08-10 | 2500 | | 178 | Kimberely | Yang | 1999-05-24 | 7000 | ...... | 104 | Bruce | Wong | 1991-05-21 | 6000 | | 103 | Alexander | Lee | 1990-01-03 | 9000 | | 101 | Neena | Wong | 1989-09-21 | 17000 | | 200 | Jennifer | Zhao | 1987-09-17 | 4400 | | 100 | Steven | Lee | 1987-06-17 | 24000 | +-------------+------------+-----------+------------+--------+ 40 rows in set
在本教程中,您学习了如何使用SQLORDER BY子句根据一个或多个列的升序或降序来对结果集进行排序。
为了获得薪资最低的前五名员工,可以按升序对员工进行排序。
3. 获取具有第N个最高值的行
假设必须得到公司薪水第二高的员工。请使用LIMIT OFFSET子句,如下所示。
SELECT employee_id, first_name, last_name, salary FROM employees ORDER BY salary DESC LIMIT 1 OFFSET 1;
ORDER BY子句按工资降序对员工进行排序。LIMIT 1 OFFSET 1子句从结果集中获取第二行。
此查询的假设是每个员工都有不同的薪水。 如果有两名员工拥有相同的最高薪水,那么它将会失败。 此外,如果有两个或更多具有相同第二高薪的员工,则查询只返回第一个。
要解决此问题,可以使用以下语句首先获得第二高薪。
SELECT DISTINCT salary FROM employees ORDER BY salary DESC LIMIT 1 , 1;
执行上面示例代码,得到以下结果 -
mysql> SELECT DISTINCT salary FROM employees ORDER BY salary DESC LIMIT 1 , 1; +--------+ | salary | +--------+ | 17000 | +--------+ 1 row in set
并将结果传递给另一个查询:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary = 17000;
结果如下所示 -

如果使用子查询,则可以将两个查询组合到单个查询中,如下所示:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary = (SELECT DISTINCT salary FROM employees ORDER BY salary DESC LIMIT 1 , 1);
结果如下所示 -

在本教程中,我们向您介绍了SQLLIMIT和OFFSET子句,这些子句用于限制查询返回的行数。
Fetch语句
在本教程中,我们来学习如何使用SQLFETCH子句来限制查询返回的行数。
1. SQL FETCH子句简介
要限制查询返回的行数,请使用LIMIT子句。LIMIT子句得到了许多数据库系统的广泛支持,例如MySQL,H2和HSQLDB。 但是,LIMIT子句不是SQL标准子句。
SQL:2008引入了OFFSET FETCH子句,它具有与LIMIT子句类似的功能。OFFSET FETCH子句用于在开始返回任何行之前跳过结果集中的前N行。
以下显示了SQLFETCH子句的语法:
OFFSET offset_rows { ROW | ROWS }
FETCH { FIRST | NEXT } [ fetch_rows ] { ROW | ROWS } ONLY
在上面语法中,
ROW和ROWS,FIRST和NEXT是同义词,因此,可以互换使用它们。offset_rows是一个整数,必须为零或正数。 如果offset_rows大于结果集中的行数,则不会返回任何行。fetch_rows也是一个整数,用于确定要返回的行数。fetch_rows的值等于或大于1。
由于行以不可预测的顺序存储在表中,因此应始终将FETCH子句与ORDER BY子句一起使用以获得一致的输出。
许多数据库系统都支持OFFSET FETCH子句,包括Oracle Database 12c +,PostgreSQL 10+和Microsoft SQL Server 2012+。 但是,每个数据库系统都会以不同的方式实现OFFSET FETCH子句。
OFFSET FETCH子句通常用于需要分页的客户端或Web应用程序。 例如,如果每个页面有十行,要获取第二页的行,可以跳过前10行并返回接下来的10行。
2. SQL FETCH示例
我们将使用示例数据库中的employees表进行演示。
以下语句返回薪水最高的员工信息:
SELECT employee_id, first_name, last_name, salary FROM employees ORDER BY salary DESC OFFSET 0 ROWS FETCH NEXT 1 ROWS ONLY;
在此示例中,首先,ORDER BY子句按薪水从高到低对员工进行排序。OFFSET子句跳过0行,FETCH子句返回第一行。
以下语句按薪水对员工进行排序,跳过前五名薪水最高的员工,然后取出接下来的五名员工。
SELECT employee_id, first_name, last_name, salary FROM employees ORDER BY salary DESC OFFSET 5 ROWS FETCH NEXT 5 ROWS ONLY;
在本教程中,您已学习如何在开始返回任何行之前使用SQLFETCH子句跳过结果集中的N行。
Where子句
在本教程中,您将学习如何使用SQLWHERE子句根据指定的条件筛选表中的行记录。
1. SQL WHERE子句简介
要从表中选择某些行,请在SELECT语句中使用WHERE子句。 以下说明了SELECT语句中WHERE子句的语法:
SELECT column1, column2, ... FROM table WHERE condition;
WHERE子句紧跟在FROM子句之后出现。WHERE子句包含一个或多个逻辑表达式,用于计算表中的每一行。 如果条件计算为true,则满足条件的行记录将包含在结果集中; 否则,它将被排除在外。
请注意,SQL具有三值逻辑,即TRUE,FALSE和UNKNOWN。 这意味着如果某行导致条件计算为FALSE或NULL,则不会返回该行。
请注意,WHERE子句后面的逻辑表达式也称为谓词。 可以使用各种运算符来形成WHERE子句中使用的行选择条件。
下表显示了SQL比较运算符:
| 编号 | 运算符 | 含义 |
|---|---|---|
| 1 | = |
等于 |
| 2 | <>或!= |
不等于 |
| 3 | < |
小于 |
| 4 | > |
大于 |
| 5 | <= |
小于或等于 |
| 6 | >= |
大于或等于 |
要形成一个简单的表达式,可以使用上面的一个运算符和两个操作数,这两个操作数可以是一侧的列名,另一侧是文字值,例如:
salary > 1000
表示:“工资是否大于1000?”。或者可以在运算符的两侧使用列名称,例如:
min_salary < max_salary
这个表达式提出了另一个问题:“最低工资是否低于最高薪水?”。
在表达式中使用的文字值可以是数字,字符,日期和时间,具体取决于使用的格式:
- 数字:使用可以是整数或小数的数字而不使用任何格式,例如:
100,200.5 - 字符:使用由单引号或双引号括起的字符,例如:
'100','John Dan'。 - 日期:使用数据库存储的格式。 它取决于数据库系统,例如,MySQL使用
'yyyy-mm-dd'格式来存储日期数据。 - 时间:使用数据库系统用于存储时间的格式。 例如,MySQL使用
'HH:MM:SS'来存储时间数据。
除SELECT语句外,还可以在UPDATE或DELETE语句中使用WHERE子句指定要更新或删除的行。
2. SQL WHERE示例
我们将使用employees表来演示如何使用WHERE子句从表中选择数据。
mysql> desc employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
带有数字比较示例的SQL WHERE子句
以下查询查找薪水大于14000的员工,并根据薪水按降序对结果集进行排序。
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary > 14000 ORDER BY salary DESC;
以下查询查找在部门ID为5中工作的所有员工。
SELECT employee_id, first_name, last_name, department_id FROM employees WHERE department_id = 5 ORDER BY first_name;
带有字符示例的SQL WHERE子句
SQL不区分大小写。 但是,当涉及比较中的值时,它区分大小写。 例如,以下查询查找姓氏(last_name)为Zhang的员工。
SELECT employee_id, first_name, last_name FROM employees WHERE last_name = 'Zhang';
执行上面示例代码,得到以下结果 -
mysql> SELECT employee_id, first_name, last_name FROM employees WHERE last_name = 'Zhang'; +-------------+------------+-----------+ | employee_id | first_name | last_name | +-------------+------------+-----------+ | 116 | Shelli | Zhang | | 117 | Sigal | Zhang | | 118 | Guy | Zhang | | 119 | Karen | Zhang | +-------------+------------+-----------+ 4 rows in set
但是,如果查询值是:ZHang或zhang,则不会返回任何行记录。
带有日期示例的SQL WHERE子句
要获得1999年1月1日之后加入公司的所有员工,请使用以下查询:
SELECT employee_id, first_name, last_name, hire_date FROM employees WHERE hire_date >= '1999-01-01' ORDER BY hire_date DESC;
如果想查询1999年加入公司的员工,可以通过以下几种方式实现:
- 使用
YEAR函数从hire_date列获取年份数据,并使用等于(=)运算符来形成表达式。 - 使用AND运算符使用两个表达式。
- 使用BETWEEN运算符。
以下语句说明了如何使用第一种方式:
SELECT employee_id, first_name, last_name, hire_date FROM employees WHERE YEAR (hire_date) = 1999 ORDER BY hire_date DESC;
在本教程中,我们向您展示了如何使用SQLWHERE子句根据指定的条件过滤数据。
And运算符
本教程将介绍SQL AND运算符,并演示如何将其应用于在SQL语句的WHERE子句中形成条件。
2. SQL AND运算符简介
AND运算符是一个逻辑运算符,它在SELECT,UPDATE或DELETE语句的WHERE子句中组合了两个布尔表达式。 以下说明了AND运算符的语法:
expression1 AND expression2;
如果两个表达式的计算结果为true,则AND运算符返回true。 如果两个表达式中的一个为false,即使其中一个表达式为NULL,则AND运算符返回false。
下表说明了比较true,false和NULL值时AND运算符的结果:
| - | TRUE | FALSE | NULL |
|---|---|---|---|
| TRUE | TRUE | FALSE | NULL |
| FALSE | FALSE | FALSE | FALSE |
| NULL | NULL | FALSE | NULL |
1. SQL AND运算符示例
我们将使用示例数据库中的employees表来演示SQL AND运算符。
mysql> DESC employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
以下语句查找同时具有工作ID是9和薪水大于5000的所有员工:
SELECT first_name, last_name, job_id, salary FROM employees WHERE job_id = 9 AND salary > 5000;
执行上面查询语句,得到以下结果 -
+------------+-----------+--------+--------+ | first_name | last_name | job_id | salary | +------------+-----------+--------+--------+ | Alexander | Lee | 9 | 9000 | | Bruce | Wong | 9 | 6000 | +------------+-----------+--------+--------+ 2 rows in set
要查找1997年到1998年之间加入公司的所有员工,使用AND运算符,如下所示:
SELECT first_name, last_name, hire_date FROM employees WHERE YEAR (hire_date) >=1997 AND YEAR (hire_date) <= 1998;
SQL AND运算符和短路计算
短路功能允许数据库系统在确定结果后立即停止评估逻辑表达式的其余部分。
让我们看一个例子来更好地理解短路计算功能的工作原理。
请参阅以下条件:
1 = 0 AND 1 = 1;
数据库系统首先处理两个比较,并使用AND运算符来评估两个结果。
但是,使用短路评估功能,数据库系统只需要评估表达式的左侧部分,因为左侧部分(1 = 0)返回false,导致整个条件返回false,而不管右侧部分条件的结果如何。
因此,短路功能可以减少CPU计算时间,并且在某些情况下有助于防止运行时错误。 考虑以下情况:
1 = 0 AND 1/0;
如果数据库系统支持短路功能,则不会评估导致除零错误的表达式(1/0)的右侧部分。
现在,您应该了解SQLAND运算符的工作原理以及如何应用它以在查询中形成复杂查询条件。
Or运算符
在本教程中,您将学习如何使用SQLOR运算符组合两个布尔表达式。
1. SQL OR运算符简介
SQLOR是一个逻辑运算符,它组合两个布尔表达式。 SQLOR运算符计算结果返回true或false,具体取决于表达式的结果。
OR运算符通常用于在SELECT,UPDATE或DELETE语句的WHERE子句中,以形成灵活的条件。
以下说明了SQL OR运算符的语法:
SELECT column1, column2, ... FROM table1 WHERE expression1 OR expression2;
下表显示了比较true,false和NULL值时OR运算符的结果。
| TRUE | FALSE | NULL | |
|---|---|---|---|
| TRUE | TRUE | TRUE | TRUE |
| FALSE | TRUE | FALSE | NULL |
| NULL | TRUE | NULL | NULL |
请注意,如果任一表达式为true,则OR运算符始终返回true。
如果数据库系统支持短路功能,则只要一个表达式为真,OR运算符就会停止评估条件的其余部分。
将OR运算符与AND运算符一起使用时,数据库系统会在AND运算符之后计算OR运算符。 它叫作优先规则。 但是,可以使用括号更改评估顺序。
2. SQL OR运算符示例
我们将使用示例数据库中的employees表来演示OR运算符。
mysql> DESC employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
以下声明查找了1997年或1998年加入公司的所有员工。
SELECT first_name, last_name, hire_date FROM employees WHERE YEAR (hire_date) = 1997 OR YEAR (hire_date) = 1998 ORDER BY first_name, last_name;
要查找1997年或1998年加入公司并在部门ID为3中工作的所有员工,可以使用AND和OR运算符,如下所示:
SELECT first_name, last_name, hire_date, department_id FROM employees WHERE department_id = 3 AND ( YEAR (hire_date) = 1997 OR YEAR (hire_date) = 1998 ) ORDER BY first_name, last_name;
如果不使用括号,查询将检索1997年加入公司并在部门ID为3工作的员工或1998年加入公司的员工(不限部门是哪个)。
这是因为数据库系统在AND运算符之后计算OR运算符。
SELECT first_name, last_name, hire_date, department_id FROM employees WHERE department_id = 3 AND YEAR (hire_date) = 1997 OR YEAR (hire_date) = 1998 ORDER BY first_name, last_name;
如果查询使用许多OR运算符,则将难以阅读。 要使查询更具可读性,可以使用IN运算符。
例如,以下查询查找在1990年或1999年或2000年加入公司的所有员工。
SELECT first_name, last_name, hire_date FROM employees WHERE YEAR (hire_date) = 2000 OR YEAR (hire_date) = 1999 OR YEAR (hire_date) = 1990;
可以通过IN运算符替换OR运算符,如下所示:
SELECT first_name, last_name, hire_date FROM employees WHERE YEAR (hire_date) IN (1990, 1999, 2000) ORDER BY hire_date;
执行上面示例代码,得到以下结果 -
+------------+-----------+------------+ | first_name | last_name | hire_date | +------------+-----------+------------+ | Alexander | Lee | 1990-01-03 | | Diana | Chen | 1999-02-07 | | Kimberely | Yang | 1999-05-24 | | Karen | Zhang | 1999-08-10 | | Min | Su | 1999-12-07 | | Charles | Yang | 2000-01-04 | +------------+-----------+------------+ 6 rows in set
在本教程中,您已经学习了如何使用SQLOR运算符组合两个布尔表达式以形成灵活的条件。
Between运算符
本教程将演示如何使用SQLBETWEEN运算符选择指定范围内的值。
SQL BETWEEN运算符简介
BETWEEN运算符是逻辑运算符。 它返回true,false或unknown值。 BETWEEN运算符用于SELECT,UPDATE或DELETE语句中以查找范围内的值。
以下说明了BETWEEN运算符的语法:
expression BETWEEN low AND high;
在上面语法中,
- 表达式是在低和高定义的范围内测试的表达式。
low和high可以是表达式或文字值,要求low的值小于high的值。
如果表达式大于或等于(>=)low值且小于或等于(<=)high值,则BETWEEN运算符返回true,这相当于以下条件:
expression >= low and expression <= high
如果要指定独占范围,则必须使用小于(<)和大于(>)的比较运算符。
要否定BETWEEN运算符的结果,可以添加NOT运算符:
expression NOT BETWEEN low AND high
如果表达式小于低于或大于(>)的值,则NOT BETWEEN返回true; 否则它返回:false。
可以使用以下条件重写NOT BETWEEN:
expression < low OR expression > high
2. SQL BETWEEN运算符示例
我们将使用示例数据库中的employees表来演示BETWEEN运算符的工作原理。
mysql> DESC employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
SQL BETWEEN与数字示例
以下语句使用BETWEEN运算符查找薪水在2500和3000之间的所有员工:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary BETWEEN 2500 AND 3000;
请注意,结果集中包含薪水为2500和3000的员工。
以下查询使用大于或等于(>=)且小于或等于(<=)的比较运算符和逻辑运算符AND,返回相同的结果集:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary >= 2500 AND salary <= 3000;
要查找薪水不在2500和10000范围内的所有员工,请在WHERE子句中使用NOT BETWEEN运算符,如下所示:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary NOT BETWEEN 2500 AND 10000 ORDER BY salary;
SQL BETWEEN日期示例
要查找在1999年1月1日到2000年12月31日之间加入公司的所有员工,查询雇用日期(hire_date)是否在以下范围内:
SELECT employee_id, first_name, last_name, hire_date FROM employees WHERE hire_date BETWEEN '1999-01-01' AND '2000-12-31' ORDER BY hire_date;
执行上面示例代码,得到以下结果 -
+-------------+------------+-----------+------------+ | employee_id | first_name | last_name | hire_date | +-------------+------------+-----------+------------+ | 107 | Diana | Chen | 1999-02-07 | | 178 | Kimberely | Yang | 1999-05-24 | | 119 | Karen | Zhang | 1999-08-10 | | 113 | Min | Su | 1999-12-07 | | 179 | Charles | Yang | 2000-01-04 | +-------------+------------+-----------+------------+ 5 rows in set
要检索不在1989年1月1日到1999年12月31日这个时间内加入公司的所有员工,请使用NOT BETWEEN运算符,如下所示:
SELECT employee_id, first_name, last_name, hire_date FROM employees WHERE hire_date NOT BETWEEN '1989-01-01' AND '1999-01-30' ORDER BY hire_date;
3. SQL BETWEEN运算符使用说明
1. 低和高的值
BETWEEN运算符需要低值和高值。 当从用户那里获得输入时,在将其传递给查询之前,应始终检查低值是否小于高值。 如果低值大于高值,将得到一个空的结果集。
以下查询不返回任何行,因为低值大于高值:
SELECT first_name, last_name, salary FROM employees WHERE salary BETWEEN 5000 AND 2000;
2. 将BETWEEN运算符与DATETIME数据一起使用
考虑以下tb1表,结构和数据如下所示:

2019年9月23日至2019年9月30日期间有5行数据。如果使用BETWEEN运算符查询create_time值介于2019-09-23和2019-09-30之间的行记录,将获得所期望的内容。
SELECT id, create_time FROM tb1 WHERE create_time BETWEEN '20190920' AND '20190930';
结果显示只返回了4行。 这是因为当使用以下条件时:
create_time BETWEEN '20190920' AND '20190930';
数据库系统将其转换为:
create_time BETWEEN '20190920 00:00:00.000000' AND '20190930 00:00:00.000000';
因此,2019-09-30 14:29:55值的行记录未包含在结果集中。
在本教程中,我们学习示了如何使用SQLBETWEEN运算符根据范围选择数据,通过本教程,可以使用BETWEEN运算符来组合成为更复杂的查询语句。
In运算符
在本教程中,您将学习如何使用SQLIN运算符将列中的值与一组值进行比较。
SQL IN运算符简介
IN运算符是一个逻辑运算符,用于将值与一组值进行比较。 如果值在值集内,则IN运算符返回true。 否则,它返回false或unknown。
以下是IN运算符的语法:
expression IN (value1,value2,...)
IN运算符通常用于SELECT,UPDATE或DELETE语句的WHERE子句中。 它也广泛用于子查询中。
使用IN运算符的条件可以使用一个或多个OR运算符重写,如下所示:
expression = value1 OR expression = value2 OR ...
要否定IN运算符的结果,请使用NOT运算符:
expression NOT IN (value1, value2,...)
如果表达式与列表中的任何值都不匹配,则NOT IN运算符返回true,否则返回false。
同样,可以使用AND运算符重写NOT IN运算符,如下所示:
expression != value1 AND expression != value2 AND...
请注意,如果列表中的任何值(value1,value2,...)为null,则IN运算符不返回任何行。
1. SQL IN示例
我们将使用示例数据库中的employees表来演示IN运算符的功能。
mysql> DESC employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
要查找工作ID为8,9或10的所有员工,请使用IN运算符,如下所示:
SELECT employee_id, first_name, last_name, job_id FROM employees WHERE job_id IN (8, 9, 10) ORDER BY job_id;
要查找工作ID不是8,9或10的所有员工,请使用NOT IN运算符,如下所示:
SELECT employee_id, first_name, last_name, job_id FROM employees WHERE job_id NOT IN (8, 9, 10) ORDER BY job_id;
SQL IN带有子查询示例
子查询是嵌套在另一个查询中的查询。 以下查询查找市场营销和IT部门的部门ID:
SELECT department_id FROM departments WHERE department_name = '市场营销' OR department_name = 'IT';
执行上面示例代码,得到以下结果 -
+---------------+ | department_id | +---------------+ | 2 | | 6 | +---------------+ 2 rows in set
该查询返回两个部门的列表。 可以将此列表提供给IN运算符,以查找在市场营销和IT部门工作的所有员工。
SELECT employee_id, first_name, last_name, salary FROM employees WHERE department_id IN (2, 6);
执行上面查询语句,得到以下结果 -

要使它更简单,可以使用在第二个查询中嵌套第一个查询的子查询来实现:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE department_id IN (SELECT department_id FROM departments WHERE department_name = '市场营销' OR department_name = 'IT')
在本教程中,您已经学习了如何使用SQLIN运算符来测试值是否在值列表或子查询中的条件。
Like运算符
在本教程中,您将学习如何使用SQLLIKE运算符来测试表达式是否与模式匹配。
1. SQL LIKE运算符简介
有时,测试表达式是否与特定模式匹配很有用,例如,查找名字以Yii或Su开头的所有员工。 在这些情况下,需要使用LIKE运算符。
LIKE运算符测试表达式是否与特定模式匹配。 请参阅以下语法:
expression LIKE pattern
如果表达式与模式匹配,则LIKE运算符返回true。 否则它返回false。
LIKE运算符通常用于SELECT,UPDATE或DELETE语句的WHERE子句中。
要构造模式,请使用两个SQL通配符:
%百分号匹配零个,一个或多个字符。_下划线符号匹配单个字符。
下表说明了一些模式及其含义:
| 模式 | 含义 |
|---|---|
LIKE 'Yii%' |
匹配以Yii开始的字符串 |
LIKE '%su' |
匹配以su结尾的字符串 |
LIKE '%ch% |
匹配包含ch的字符串 |
LIKE 'Luc_' |
以Luc开始,后面只有一个字符,例如:Lucy,Lucc等 |
LIKE '_cy' |
以cy结尾,前面只有一个字符,例如:Lcy,ucy等 |
LIKE '%yiibai_' |
包含yiibai,以任意数量的字符开头,最多以一个字符结尾。 |
LIKE '_yiibai%' |
包含yiibai,最多以一个字符开头,以任意数量的字符结尾。 |
如果要匹配通配符%或_,则必须使用反斜杠字符\来对其进行转义。 如果要使用其它的转义字符而不是反斜杠,可以在LIKE表达式中使用ESCAPE子句,如下所示:
expression LIKE pattern ESCAPE escape_character
2. SQL LIKE运算符示例
我们将使用示例数据库中的employees表进行演示。
mysql> desc employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
要查找名字以Sh开头的所有员工,请使用Sh%模式,如以下语句所示:
SELECT employee_id, first_name, last_name FROM employees WHERE first_name LIKE 'Sh%';
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+ | employee_id | first_name | last_name | +-------------+------------+-----------+ | 116 | Shelli | Zhang | | 123 | Shanta | Liu | | 205 | Shelley | Wu | +-------------+------------+-----------+ 3 rows in set
执行上面查询语句,得到以下结果 -
SELECT employee_id, first_name, last_name FROM employees WHERE first_name LIKE '%na';
以下语句查找姓氏包含字符:en的所有员工:
SELECT employee_id, first_name, last_name FROM employees WHERE last_name LIKE '%en%';
以下语句检索名字以Jo开头且后跟最多2个字符的员工:
SELECT employee_id, first_name, last_name FROM employees WHERE first_name LIKE 'Jo__';
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+ | employee_id | first_name | last_name | +-------------+------------+-----------+ | 110 | John | Chen | | 145 | John | Liu | +-------------+------------+-----------+ 2 rows in set
以下语句选择名字以任意数字开头且后跟最多一个字符的员工。
SELECT employee_id, first_name, last_name FROM employees WHERE first_name LIKE '%are_';
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+ | employee_id | first_name | last_name | +-------------+------------+-----------+ | 119 | Karen | Zhang | | 146 | Karen | Liu | +-------------+------------+-----------+ 2 rows in set
3. SQL NOT LIKE运算符
要否定LIKE运算符的结果,可以使用NOT运算符,如下所示:
expression NOT LIKE pattern ESCAPE escape_character
例如,要查找名字以M开头但不以Ma开头的所有员工,请使用以下语句:
SELECT employee_id, first_name, last_name FROM employees WHERE first_name LIKE 'M%' AND first_name NOT LIKE 'Ma%' ORDER BY first_name;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+ | employee_id | first_name | last_name | +-------------+------------+-----------+ | 201 | Michael | Zhou | | 113 | Min | Su | | 122 | Min | Liu | +-------------+------------+-----------+ 3 rows in set
在本教程中,您学习了如何使用SQLLIKE运算符选择与特定模式匹配的值。
Is Null运算符
在本教程中,我们将介绍NULL概念,并演示如何使用SQLIS NULL和IS NOT NULL运算符来测试表达式是否为NULL。
1. 什么是NULL?
NULL在SQL中很特殊。NULL表示数据未知的值,可以简单理解为表示:不适用或不存在的值。 换句话说,NULL表示数据库中缺少数据。
例如,如果员工没有任何电话号码,可以将其存储为空字符串。 但是,如果在插入员工记录时不知道他的电话号码,我们将使用未知电话号码的NULL值。
NULL值是特殊的,因为任何与NULL值的比较都不会导致true或false,但在第三个逻辑结果中:未知。
以下语句返回null值。
SELECT NULL = 5;
NULL值甚至不等于自身,如以下语句所示。
SELECT NULL = NULL;
在此示例中,结果为NULL值。
不能使用比较运算符的等于(=)将值与NULL值进行比较。 例如,以下语句将不会产生正确的结果。
SELECT employee_id, first_name, last_name, phone_number FROM employees WHERE phone_number = NULL;
2. IS NULL 和 IS NOT NULL 运算符
要确定表达式或列的值是否为NULL,请使用IS NULL运算符,如下所示:
expression IS NULL;
如果表达式的结果为NULL,则IS NULL运算符返回true; 否则它返回false。要检查表达式或列是否不为NULL,请使用IS NOT运算符:
expression IS NOT NULL;
如果表达式的值为NULL,则IS NOT NULL返回false; 否则它返回true;
3. SQL IS NULL和IS NOT NULL示例
在这些示例中,我们将使用示例数据库中的employees表进行演示。
mysql> DESC employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
要查找具有电话号码的所有员工,请使用IS NOT NULL,如以下语句所示:
SELECT employee_id, first_name, last_name, phone_number FROM employees WHERE phone_number IS NOT NULL;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+----------------+ | employee_id | first_name | last_name | phone_number | +-------------+------------+-----------+----------------+ | 100 | Steven | Lee | 0532-86011111 | | 101 | Neena | Wong | 0551-4243311 | | 102 | Lex | Liang | 0571-87622362 | | 103 | Alexander | Lee | 020-95105105 | | 104 | Bruce | Wong | 0371-68356666 | | 105 | David | Liang | 0512-67513131 | | 106 | Valli | Chen | 0535-95105175 | | 107 | Diana | Chen | 025-95105105 | | 108 | Nancy | Chen | 0531-86012520 | | 109 | Daniel | Chen | 021-8008207890 | ... ... | 201 | Michael | Zhou | 010-67237328 | | 202 | Pat | Zhou | 0755-28114518 | | 203 | Susan | Zhou | 0755-83587526 | | 204 | Hermann | Wu | 0513-83512816 | | 205 | Shelley | Wu | 0898-31686222 | | 206 | William | Wu | 022-26144822 | +-------------+------------+-----------+----------------+ 34 rows in set
通过本小节的学习,现在您应该了解NULL概念并知道如何使用SQLIS NULL运算符来检查值是否为NULL值。
Not运算符
在本教程中,您将学习如何使用SQLNOT运算符来否定SELECT语句WHERE子句中的布尔表达式。
在前面已经学习了如何使用各种逻辑运算符,如:AND,OR,LIKE,BETWEEN,IN和EXISTS。 这些运算符可帮助您在WHERE子句中形成灵活的条件。
要反转任何布尔表达式的结果,请使用NOT运算符。 以下演示如何使用NOT运算符。
NOT [Boolean_expression]
下表显示了NOT运算符的结果。
| 原值 | 应用Not运算符后 |
|---|---|
| TRUE | FALSE |
| FALSE | TRUE |
| NULL | NULL |
2. SQL NOT运算符示例
我们将使用employees表来演示NOT运算符。employees表的结构如下所示 -
mysql> DESC employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
以下语句检索在部门ID为5中工作的所有员工。如下查询语句 -
SELECT employee_id, first_name, last_name, salary FROM employees WHERE department_id = 5 ORDER BY salary;
查询工作在部门ID为5且薪水不超过5000的员工。
SELECT employee_id, first_name, last_name, salary FROM employees WHERE department_id = 5 AND NOT salary > 5000 ORDER BY salary;
执行上面示例代码,得到以下结果 -
+-------------+------------+-----------+--------+ | employee_id | first_name | last_name | salary | +-------------+------------+-----------+--------+ | 126 | Irene | Liu | 2700 | | 193 | Britney | Zhao | 3900 | | 192 | Sarah | Yang | 4000 | +-------------+------------+-----------+--------+ 3 rows in set
SQL NOT IN运算符示例
要否定IN运算符,请使用NOT运算符。 例如,以下语句将获取不在部门ID为1,2或3中工作的所有员工。
SELECT employee_id, first_name, last_name, department_id FROM employees WHERE department_id NOT IN (1, 2, 3) ORDER BY first_name;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+---------------+ | employee_id | first_name | last_name | department_id | +-------------+------------+-----------+---------------+ | 103 | Alexander | Lee | 6 | | 193 | Britney | Zhao | 5 | | 104 | Bruce | Wong | 6 | | 179 | Charles | Yang | 8 | | 109 | Daniel | Chen | 10 | | 105 | David | Liang | 6 | | 107 | Diana | Chen | 6 | | 204 | Hermann | Wu | 7 | | 126 | Irene | Liu | 5 | ...... | 100 | Steven | Lee | 9 | | 203 | Susan | Zhou | 4 | | 106 | Valli | Chen | 6 | | 206 | William | Wu | 11 | +-------------+------------+-----------+---------------+ 31 rows in set
SQL NOT LIKE运算符示例
可以使用NOT LIKE来否定LIKE运算符。 例如,以下语句检索名字不以字母M开头的所有员工。
SELECT first_name, last_name FROM employees WHERE first_name NOT LIKE 'M%' ORDER BY first_name;
执行上面查询语句,得到以下结果 -
+------------+-----------+ | first_name | last_name | +------------+-----------+ | Alexander | Lee | | Alexander | Su | | Avg | Su | | Britney | Zhao | | Bruce | Wong | | Charles | Yang | ... ... | Shelley | Wu | | Shelli | Zhang | | Sigal | Zhang | | Steven | Lee | | Susan | Zhou | | Valli | Chen | | William | Wu | +------------+-----------+ 34 rows in set
SQL NOT BETWEEN示例
以下示例说明如何使用NOT来否定BETWEEN运算符,以使员工的薪水不在1000到1000之间。
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary NOT BETWEEN 3000 AND 5000 ORDER BY salary;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+--------+ | employee_id | first_name | last_name | salary | +-------------+------------+-----------+--------+ | 119 | Karen | Zhang | 2500 | | 118 | Guy | Zhang | 2600 | | 126 | Irene | Liu | 2700 | | 117 | Sigal | Zhang | 2800 | | 116 | Shelli | Zhang | 2900 | | 104 | Bruce | Wong | 6000 | | 202 | Pat | Zhou | 6000 | | 179 | Charles | Yang | 6200 | ... ... | 205 | Shelley | Wu | 12000 | | 201 | Michael | Zhou | 13000 | | 146 | Karen | Liu | 13500 | | 145 | John | Liu | 14000 | | 102 | Lex | Liang | 17000 | | 101 | Neena | Wong | 17000 | | 100 | Steven | Lee | 24000 | +-------------+------------+-----------+--------+ 33 rows in set
SQL NOT EXISTS示例
以下查询使用NOT EXISTS运算符来获取没有任何家属的员工。
SELECT employee_id, first_name, last_name FROM employees e WHERE NOT EXISTS ( SELECT employee_id FROM dependents d WHERE d.employee_id = e.employee_id );
通过上面的学习,现在您应该知道如何使用NOT运算符来否定布尔表达式了。
别名
在本教程中,您将了解SQL别名,包括表和列别名,以使查询更短,更易理解。
1. SQL别名简介

1.1. 列别名
当我们设计表时,经常将列名称保持简短或另起新名称,例如,销售订单号为:so_no,发票号码为:inv_no。在使用SELECT语句从表中查询数据返回输出时不具有描述性。
要在查询中为列指定新名称,请使用列别名。 列别名只是执行查询期间列的临时名称。
请参阅以下查询:
SELECT inv_no AS invoice_no, amount, due_date AS '截止日期', cust_no '客户编号' FROM invoices;
invoice_no是inv_no列的别名'Due date'是due_date列的列别名。 因为别名包含空格,所以必须使用单引号(')或双引号(")来包围别名。'Customer no'是cust_no列的别名。注意这里没有使用AS关键字。AS关键字是可选的,因此可以省略它。
我们经常对选择列表中的表达式使用列别名。 例如,以下查询使用headcount作为返回雇员数量的表达式的列别名:
SELECT count(employee_id) headcount FROM employees;
执行上面示例代码,得到以下结果 -
mysql> SELECT count(employee_id) headcount FROM employees; +-----------+ | headcount | +-----------+ | 40 | +-----------+ 1 row in set
可以在SELECT子句之后评估的任何子句中使用列别名,例如HAVING子句。 请参阅以下示例:
SELECT department_id, count(employee_id) headcount FROM employees GROUP BY department_id HAVING headcount >= 5;
执行上面示例代码,得到以下结果 -

在HAVING子句中,我们不是引用表达式count(employee_id),而是引用列别名headcount。
1.2. 表别名
在SELECT语句中临时为表分配一个不同的名称。这个表的新名称称为表别名。 表别名也称为相关名称。
请注意,分配别名实际上并不重命名表。 它只是在执行查询时为表提供另一个名称。
在实践中,我们保持表别名简短且易于理解。 例如,e代表员工,d代表部门,j代表职位,l代表位置。
那么为什么必须使用表别名呢?
第一个原因:使用表别名的是节省输入冗长名称的时间并使查询更容易理解。 请参阅以下查询:
SELECT d.department_name FROM departments AS d
d是departments表的表别名。AS关键字是可选的,因此可以省略它。
当departments表具有别名d时,您可以使用别名d来引用该表。
例如,d.department_name引用departments表的department_name字段。 如果不使用表别名,则必须使用departments.department_name来引用更长的department_name字段。
第二个原因:使用表别名,希望在单个查询中多次引用同一个表。例如经常在内联接,左联接和自联接中找到此类查询。
以下查询使用inner join子句从employees和departments表中选择数据。
SELECT employee_id, first_name, last_name, department_name FROM employees INNER JOIN departments ON department_id = department_id ORDER BY first_name;
执行上面查询语句后,数据库系统将发出错误:
Column 'department_id' in on clause is ambiguous
要避免这个错误,需要使用表名限定列,如下所示:
SELECT employee_id, first_name, last_name, employees.department_id, department_name FROM employees INNER JOIN departments ON departments.department_id = employees.department_id ORDER BY first_name;
要使查询更短,可以使用表别名,例如,e表示employees表,d表示departments表,如下面的查询:
SELECT employee_id, first_name, last_name, e.department_id, department_name FROM employees e INNER JOIN departments d ON d.department_id = e.department_id ORDER BY first_name;
以下查询使用self-join将employee表自联接。
SELECT e.first_name AS employee, m.first_name AS manager FROM employees e LEFT JOIN employees m ON m.employee_id = e.manager_id ORDER BY manager;
因为employees表在查询中出现两次,所以需要使用两个表别名:e和m;e代表员工,而m代表经理。
在本教程中,您学习了如何使用SQL别名(包括列别名和表别名)来使查询更短,更易理解。
Inner Join子句
在本教程中,我们将演示如何使用SQLINNER JOIN子句来查询来自两个或多个表的数据。
1. SQL INNER JOIN子句简介
到目前为止,您已经学习了如何使用SELECT语句从单个表中查询数据。 但是,SELECT语句不限于从单个表中查询数据。 SELECT语句可以将多个表链接在一起。
连接表的过程称为Join。 SQL提供了多种连接,如内连接,左连接,右连接,全外连接等。本教程重点介绍内连接。
内部连接子句通过两列之间的关系链接两个(或更多)表。 无论何时使用内连接子句,通常都要考虑交集。
通过一个简单的例子来理解内连接概念要容易得多。
假设有两个表:A和B。
表A有四行:(1,2,3,4),表B有四行:(3,4,5,6)
当表A使用内部联接与表B连接时,我们得到结果集(3,4),它是表A和表B的交集。
如下图所示 -

对于表A中的每一行,内部连接子句查找表B中的匹配行。如果匹配行,则它将包含在最终结果集中。
假设A&B表的列名是n,以下语句说明了内连接子句:
SELECT A.n FROM A INNER JOIN B ON B.n = A.n;
INNER JOIN子句出现在FROM子句之后。 在ON关键字之后指定表A和表B之间匹配的条件。这种情况称为连接条件,即B.n = A.n
INNER JOIN子句可以连接三个或更多表,只要它们具有关系,通常是外键关系。
例如,以下语句说明了如何连接3个表:A,B和C:
SELECT A.n FROM A INNER JOIN B ON B.n = A.n INNER JOIN C ON C.n = A.n;
2. SQL INNER JOIN示例
SQL INNER JOIN 2个表的示例
每个员工都属于一个且只有一个部门,而每个部门可以拥有多个员工。 员工和部门表之间的关系是一对多的。
employees表中的department_id列是将员工链接到departments表的外键列。
要获取部门ID为:1,2和3的信息,请使用以下语句。
SELECT department_id, department_name FROM departments WHERE department_id IN (1, 2, 3);
执行上面查询语句,得到以下结果 -
+---------------+-----------------+ | department_id | department_name | +---------------+-----------------+ | 1 | 管理 | | 2 | 市场营销 | | 3 | 采购 | +---------------+-----------------+ 3 rows in set
请注意,在WHERE子句中使用IN运算符来获取department_id为1,2和3的行。
要获取在部门ID为:1,2和3中工作的员工的信息,请使用以下查询:
SELECT first_name, last_name, department_id FROM employees WHERE department_id IN (1, 2, 3) ORDER BY department_id;
执行上面查询语句,得到以下结果 -
要组合这两个表中的数据,请使用内部连接子句,组成成以下查询:
SELECT first_name, last_name, employees.department_id, departments.department_id, department_name FROM employees INNER JOIN departments ON departments.department_id = employees.department_id WHERE employees.department_id IN (1 , 2, 3);
执行上面查询语句,得到以下结果 -
对于employees表中的每一行,该语句检查department_id列的值是否等于departments表中department_id列的值。
如果满足条件employees.department_id = departments.department_id,则employees和departments表中行的数据的组合行将包含在结果集中。
请注意,employees和departments表都具有相同的列名department_id,因此我们必须使用语法table_name.column_name限定department_id列。
SQL INNER JOIN 3个表的示例
每个员工都有一个工作岗位,而一个工作岗位可能会有多个员工。jobs表和employees表之间的关系是一对多的。
以下数据库图说明了employees,departments和jobs表之间的关系:

以下查询使用内部联接子句连接3个表:员工,部门和工作岗位,以获取在部门ID为:1,2和3中工作的员工的名字,姓氏,职位和部门名称。
SELECT first_name, last_name, job_title, department_name FROM employees e INNER JOIN departments d ON d.department_id = e.department_id INNER JOIN jobs j ON j.job_id = e.job_id WHERE e.department_id IN (1, 2, 3);
执行上面查询语句,得到以下结果 -

通过上面的学习,现在您应该了解SQLINNER JOIN子句如何工作,并知道如何应用它来查询来自多个表的数据。
Left Join子句
在本教程中,我们将介绍另一种称为SQLLEFT JOIN的连接,它用于从多个表中检索数据。
1. SQL LEFT JOIN子句简介
在上一个教程中我们知道,如果两个表中至少有一行与连接条件匹配,则返回行记录的内联接。 内连接子句消除了与另一个表的行不匹配的行。
但是,左连接将返回左表中的所有行,而不管右表中是否存在匹配的行。
假设有两个表A和B。表A有四行:1,2,3和4。表B还有四行:3,4,5,6。
当将表A与表B连接时,表A中的所有行(左表)都包含在结果集中,而不管无论表B中是否存在匹配的行。

在SQL中,使用以下语法将表A与表B连接起来。
SELECT A.n FROM A LEFT JOIN B ON B.n = A.n;
LEFT JOIN子句出现在FROM子句之后。ON关键字后面的条件称为连接条件B.n = A.n。
2. SQL LEFT JOIN示例
2.1. SQL LEFT JOIN两个表的例子

每个地点属于一个且仅一个国家/地区,而每个国家/地区可以具有零个或多个地点。countries和locations表之间的关系是一对多的。
locations表中的country_id列是链接到countries表中country_id列的外键。
要查询美国,英国和中国的国家/地区名称,请使用以下语句。
···
SELECT
country_id,
country_name
FROM
countries
WHERE
country_id IN ('US', 'UK', 'CN');
执行上面查询语句,得到以下结果 -
+------------+--------------+ | country_id | country_name | +------------+--------------+ | CN | 中国 | | UK | 英国 | | US | 美国 | +------------+--------------+ 3 rows in set
以下查询检索位于美国,英国和中国的地点:
SELECT
country_id,
street_address,
city
FROM
locations
WHERE
country_id IN ('US', 'UK', 'CN');
执行上面查询语句,得到以下结果 -
+------------+------------------------------------------+---------------------+ | country_id | street_address | city | +------------+------------------------------------------+---------------------+ | US | 2014 Jabberwocky Rd | Southlake | | US | 2011 Interiors Blvd | South San Francisco | | US | 2004 Charade Rd | Seattle | | UK | 8204 Arthur St | London | | UK | Magdalen Centre, The Oxford Science Park | Oxford | +------------+------------------------------------------+---------------------+ 5 rows in set
现在,使用LEFT JOIN子句将countries表与locations表连接为以下查询:
SELECT
c.country_name, c.country_id, l.country_id, l.street_address, l.city
FROM
countries c
LEFT JOIN locations l ON l.country_id = c.country_id
WHERE
c.country_id IN ('US', 'UK', 'CN')
执行上面查询语句,得到以下结果 -

应用WHERE子句中的条件,指示仅检索来自:US,UK和China行的数据。
因为使用LEFT JOIN子句,所以满足countries表的WHERE子句中的条件的所有行都包含在结果集中。
对于countries表中的每一行,LEFT JOIN子句在locations表中查找匹配的行。如果找到至少一个匹配行,则数据库引擎将两个表中匹配行的列中的数据组合在一起。
如果没有找到匹配的行,例如,使用country_id的值是:CN,则countries表中的行包含在结果集中,而locations表中的行用NULL值填充。
由于右表中的非匹配行使用NULL值填充,因此可以将LEFT JOIN子句应用于表之间的未匹配行。
例如,要查找locations表中没有任何地点的国家/地区,请使用以下查询:
SELECT country_name FROM countries c LEFT JOIN locations l ON l.country_id = c.country_id WHERE l.location_id IS NULL ORDER BY country_name;
执行以下查询语句,得到以下结果 -
+--------------+ | country_name | +--------------+ | 中国 | | 丹麦 | | 以色列 | | 印度 | | 埃及 | | 墨西哥 | | 尼日利亚 | ..... | 荷兰 | | 赞比亚 | | 阿根廷 | | 香港 | +--------------+ 21 rows in set
2.2. SQL LEFT JOIN 3个表的示例
请参阅下表:regions,countries和locations的结构和关系。

一个地区可能有零个或多个国家,而每个国家都位于一个地区。countries和regions表之间的关系是一对多的。countries表中的region_id列是国家和地区表之间的链接。
以下语句演示了如何连接3个表:regions,countries和locations:

通过上面的学习,现在您应该很好地理解SQL LEFT JOIN子句的工作原理,并知道如何应用LEFT JOIN子句来查询来自多个表的数据。
FULL OUTER JOIN子句
在本教程中,您将学习如何使用SQLFULL OUTER JOIN子句查询来自多个表的数据。
1. SQL FULL OUTER JOIN子句简介
理论上,完全外连接是左连接和右连接的组合。 完整外连接包括连接表中的所有行,无论另一个表是否具有匹配的行。
如果连接表中的行不匹配,则完整外连接的结果集包含缺少匹配行的表的每列使用NULL值。 对于匹配的行,结果集中包含从连接表填充列的行。
以下语句说明了两个表的完全外连接的语法:
SELECT column_list FROM A FULL OUTER JOIN B ON B.n = A.n;
请注意,OUTER关键字是可选的。
以下图说明了两个表的完整外连接。

2. SQL FULL OUTER JOIN示例
让我们举一个使用FULL OUTER JOIN子句来看它是如何工作的例子。
首先,创建两个新表:用于演示的baskets和fruits表。 每个篮子存储零个或多个水果,每个水果可以存储在零个或一个篮子中。
-- 创建表1 CREATE TABLE fruits ( fruit_id INTEGER PRIMARY KEY, fruit_name VARCHAR (255) NOT NULL, basket_id INTEGER ); -- 创建表2 CREATE TABLE baskets ( basket_id INTEGER PRIMARY KEY, basket_name VARCHAR (255) NOT NULL );
其次,将一些样本数据插入到baskets和fruits表中。
-- 插入数据1 INSERT INTO baskets (basket_id, basket_name) VALUES (1, 'A'), (2, 'B'), (3, 'C'); -- 插入数据2 INSERT INTO fruits ( fruit_id, fruit_name, basket_id ) VALUES (1, 'Apple', 1), (2, 'Orange', 1), (3, 'Banana', 2), (4, 'Strawberry', NULL);
第三,以下查询返回篮子中的每个水果和每个有水果的篮子,但也返回不在任何篮子中的每个水果和每个没有任何水果的篮子。
SELECT basket_name, fruit_name FROM fruits FULL OUTER JOIN baskets ON baskets.basket_id = fruits.basket_id;
执行上面示例代码,得到以下结果 -
basket_name | fruit_name -------------+------------ A | Apple A | Orange B | Banana (null) | Strawberry C | (null)
如上所见,篮子C没有任何水果,Strawberry不在任何篮子里。
您可以将WHERE子句添加到使用FULL OUTER JOIN子句的语句中以获取更具体的信息。
例如,要查找不存储任何水果的空篮子,请使用以下语句:
SELECT basket_name, fruit_name FROM fruits FULL OUTER JOIN baskets ON baskets.basket_id = fruits.basket_id WHERE fruit_name IS NULL;
执行上面示例代码,得到以下结果 -
basket_name | fruit_name -------------+------------ C | (null) (1 row)
同样,如果想查看哪个水果不在任何篮子中,请使用以下语句:
SELECT basket_name, fruit_name FROM fruits FULL OUTER JOIN baskets ON baskets.basket_id = fruits.basket_id WHERE basket_name IS NULL;
执行上面示例代码,得到以下结果 -
basket_name | fruit_name -------------+------------ (null) | Strawberry (1 row)
在本教程中,我们演示了如何使用SQLFULL OUTER JOIN子句来查询来自多个表的数据。
Cross Join子句
本教程将学习和演示如何使用SQLCROSS JOIN生成连接表的笛卡尔积。
1. SQL CROSS JOIN子句简介
交叉连接是一种连接操作,它生成两个或多个表的笛卡尔积。
在数学中,笛卡尔积是一种返回多组产品集的数学运算。
例如,有两组集合:A {x,y,z}和B {1,2,3},A x B的笛卡尔乘积是所有有序对(x,1),(x,2),(x,3),(y,1),(y,2),(y,3),(z,1),(z,2),(z,3)。
下图说明了A和B的笛卡尔积:

类似地,在SQL中,两个表A和B的笛卡尔乘积是结果集,其中第一个表(A)中的每一行与第二个表(B)中的每一行配对。 假设A表有n行,而B表有m行,那么A和B表的交叉连接结果有n x m行。
以下是CROSS JOIN子句的语法:
SELECT column_list FROM A CROSS JOIN B;
下图说明了表A和表B之间的交叉连接的结果。在图中,表A具有三行记录:1,2和3,而表B也具有三行记录:x,y和z。 那么笛卡尔积结果有九行:

以下语句等同于使用上面的CROSS JOIN子句的语句:
SELECT column_list FROM A, B;
2. SQL CROSS JOIN示例
我们将创建两个用于演示交叉连接的新表:
sales_organization表存储销售组织。sales_channel表存储销售渠道。
以下语句用于创建sales_organization和sales_channel表:
-- 创建表1 CREATE TABLE sales_organization ( sales_org_id INT PRIMARY KEY, sales_org VARCHAR (255) ); -- 创建表2 CREATE TABLE sales_channel ( channel_id INT PRIMARY KEY, channel VARCHAR (255) );
假设该公司有两个国内(Domestic)和出口(Export)销售组织,负责国内和国际市场的销售。
以下语句将两个销售组织插入sales_organization表:
INSERT INTO sales_organization (sales_org_id, sales_org) VALUES (1, 'Domestic'), (2, 'Export');
该公司可以通过批发(Wholesale),零售(Retail),电子商务(eCommerce)和电视购物(TV Shopping)等各种渠道分销商品。 以下语句将销售渠道插入sales_channel表:
INSERT INTO sales_channel (channel_id, channel) VALUES (1, 'Wholesale'), (2, 'Retail'), (3, 'eCommerce'), (4, 'TV Shopping');
要查找销售组织可以拥有的所有可能的销售渠道,可以使用CROSS JOIN将sales_organnel表与sales_channel表连接,如下所示:
SELECT sales_org, channel FROM sales_organization CROSS JOIN sales_channel;
执行上面查询语句,得到以下结果 -

结果集包括sales_organization和sales_channel表中的所有行记录。
以下查询等效于使用上面的CROSS JOIN子句的语句:
SELECT sales_org, channel FROM sales_organization, sales_channel;
在某些数据库系统(如PostgreSQL和Oracle)中,可以使用INNER JOIN子句,其条件始终求值为true以执行交叉连接,例如:
SELECT sales_org, channel FROM sales_organization INNER JOIN sales_channel ON 1 = 1;
在本教程中,学习了如何使用SQLCROSS JOIN子句生成两个或多个表的笛卡尔积。
自连接
本教程将向您展示如何使用SQL自连接技术将表连接到自身。
1. SQL自连接简介
有时,将表连接到自身是很有用的。 这种类型的连接称为自连接。
我们将一张表连接到自身来评估同一个表中其他行的行。 要执行自联接,我们使用内连接或左连接子句。
因为同一张表在单个查询中出现两次,所以必须使用表别名。 以下语句说明了如何将表连接到自身。
SELECT column1, column2, column3, ... FROM table1 A INNER JOIN table1 B ON B.column1 = A.column2;
在此语句中,使用INNER JOIN子句将table1连接到自身。A和B是table1的表别名。B.column1 = A.column2是连接条件。
除了INNER JOIN子句,还可以使用LEFT JOIN子句。
下面举几个使用自连接技术的例子。
2. SQL自联接示例
请参阅以下employees表的结构。
mysql> DESC employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
在employees表中,manager_id列指定员工的经理。 以下语句将employees表连接到自身,以查询每位员工的上级经理信息。
SELECT CONCAT(e.first_name, ' ', e.last_name) as employee, CONCAT(m.first_name, ' ', m.last_name) as manager FROM employees e INNER JOIN employees m ON m.employee_id = e.manager_id ORDER BY manager;
执行上面查询语句,得到以下结果 -
+----------------+---------------+ | employee | manager | +----------------+---------------+ | Bruce Wong | Alexander Lee | | David Liang | Alexander Lee | | Valli Chen | Alexander Lee | | Diana Chen | Alexander Lee | | Karen Zhang | Avg Su | | Alexander Su | Avg Su | | Shelli Zhang | Avg Su | | Sigal Zhang | Avg Su | | Guy Zhang | Avg Su | | Alexander Lee | Lex Liang | | Irene Liu | Matthew Han | ... ... | Avg Su | Steven Lee | | John Liu | Steven Lee | | Karen Liu | Steven Lee | | Jonathon Yang | Steven Lee | | Jack Yang | Steven Lee | +----------------+---------------+ 39 rows in set
由于内部联接子句仅包括在另一个表中具有匹配行的行,因此主席未显示在上述查询的结果集中。
主席(president)没有任何经理。 在employees表中,包含主席的行的manager_id为NULL。
要在结果集中包含主席,使用LEFT JOIN子句而不是INNER JOIN子句作为以下查询。
SELECT CONCAT(e.first_name, ' ', e.last_name) as employee, CONCAT(m.first_name, ' ', m.last_name) as manager FROM employees e LEFT JOIN employees m ON m.employee_id = e.manager_id ORDER BY manager;
执行上面查询语句,得到以下结果 -
+----------------+---------------+ | employee | manager | +----------------+---------------+ | Steven Lee | NULL | | Diana Chen | Alexander Lee | | Bruce Wong | Alexander Lee | | David Liang | Alexander Lee | | Valli Chen | Alexander Lee | | Guy Zhang | Avg Su | ... ... | John Liu | Steven Lee | | Karen Liu | Steven Lee | | Jonathon Yang | Steven Lee | +----------------+---------------+ 40 rows in set
在本教程中,演示了如何使用INNER JOIN或LEFT JOIN子句将表连接到自身。
聚合函数
在本教程中,您将了解SQL聚合函数,包括:AVG(),COUNT(),MIN(),MAX()和SUM()。
SQL聚合函数计算一组值并返回单个值。 例如,平均函数(AVG)采用值列表并返回平均值。
因为聚合函数对一组值进行操作,所以它通常与SELECT语句的GROUP BY子句一起使用。 GROUP BY子句将结果集划分为值分组,聚合函数为每个分组返回单个值。
SELECT c1, aggregate_function(c2) FROM table GROUP BY c1;
以下是常用的SQL聚合函数:
- AVG() - 返回集合的平均值。
- COUNT() - 返回集合中的项目数。
- MAX() - 返回集合中的最大值。
- MIN() - 返回集合中的最小值
- SUM() - 返回集合中所有或不同值的总和。
除COUNT()函数外,SQL聚合函数忽略null值。只能将聚合函数用作表达式,如下所示:
SELECT语句的选择列表,子查询或外部查询。- 一个HAVING子句
1. AVG()函数
AVG()函数返回集合中的平均值,以下是AVG()函数的语法:
AVG( ALL | DISTINCT)
ALL关键字指示AVG()函数计算所有值的平均值,而DISTINCT关键字强制函数仅对不同的值进行操作。 默认情况下,使用ALL选项。
以下示例演示如何使用AVG()函数计算每个部门的平均工资:
SELECT department_name, ROUND(AVG(salary), 0) avg_salary FROM employees INNER JOIN departments USING (department_id) GROUP BY department_name ORDER BY department_name;
2. MIN()函数
MIN()函数返回集合的最小值。 以下是MIN()函数的语法:
MIN(column | expression)
例如,以下语句返回每个部门中员工的最低工资:
SELECT department_name, MIN(salary) min_salary FROM employees INNER JOIN departments USING (department_id) GROUP BY department_name ORDER BY department_name;
3. MAX()函数
MAX()函数返回集合的最大值,MAX()函数具有以下语法:
MAX(column | expression)
例如,以下语句返回每个部门中员工的最高薪水:
SELECT department_name, MAX(salary) highest_salary FROM employees INNER JOIN departments USING (department_id) GROUP BY department_name ORDER BY department_name;
4. COUNT()函数
COUNT()函数返回集合中的项目数。 以下显示了COUNT()函数的语法:
COUNT ( [ALL | DISTINCT] column | expression | *)
例如,以下示例使用COUNT(*)函数返回每个部门的人数:
SELECT department_name, COUNT(*) headcount FROM employees INNER JOIN departments USING (department_id) GROUP BY department_name ORDER BY department_name;
5. SUM()函数
SUM()函数返回所有值的总和。 以下说明了SUM()函数的语法:
SUM(ALL | DISTINCT column)
例如,以下语句返回每个部门中所有员工的总薪水:
SELECT department_id, SUM(salary) FROM employees GROUP BY department_id;
在本教程中,您学习了最常用的SQL聚合函数,包括:AVG(),COUNT(),MIN(),MAX()和SUM()函数。
Avg()函数
在本教程中,我们将演示如何使用SQLAVG函数来获取集合的平均值。
1. SQL AVG函数简介
SQLAVG函数是一个聚合函数,用于计算集合的平均值。 以下说明了SQL AVG函数的语法:
AVG([ALL|DISTINCT] expression)
如果使用ALL关键字,AVG函数将获取计算中的所有值。 默认情况下,无论是否指定,AVG函数都使用ALL。
如果明确指定DISTINCT关键字,AVG函数将仅在计算中采用唯一值。
例如,有一组数据集(1,2,3,3,4)并将AVG(ALL)应用于此集合,AVG函数将执行以下计算:
(1+2+3+3+4)/5 = 2.6
但是,如果指定:AVG(DISTINCT)将按如下方式处理:
(1+2+3+4)/4 = 2.5
2. SQL AVG函数示例
将使用示例数据库中的employees表来演示SQLAVG函数的工作原理。 以下图片说明了employees表的结构:
mysql> desc employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
要计算所有员工的平均工资,请将AVG函数应用于salary列,如下所示:
SELECT AVG(salary) FROM employees;
执行上面示例代码,得到以下结果:
+-------------+ | AVG(salary) | +-------------+ | 8060 | +-------------+ 1 row in set
应用DISTINCT运算符来查看结果是否发生了变化:
SELECT AVG(DISTINCT salary) FROM employees;
执行上面示例代码,得到以下结果:
+----------------------+ | AVG(DISTINCT salary) | +----------------------+ | 7845.454545 | +----------------------+ 1 row in set
如上结果有改变,因为一些员工有相同的薪水。要将结果舍入为2位小数,请使用ROUND函数,如下所示:
SELECT ROUND(AVG(DISTINCT salary), 2) FROM employees;
要计算值子集的平均值,在SELECT语句中添加WHERE子句。 例如,要计算部门ID为5中员工的平均工资,使用以下查询:
SELECT AVG(DISTINCT salary) FROM employees WHERE department_id = 5;
以下语句返回工作岗位ID为6的员工的平均工资:
SELECT AVG(salary) FROM employees WHERE job_id = 6;
执行上面示例代码,得到以下结果:
+-------------+ | AVG(salary) | +-------------+ | 7920 | +-------------+ 1 row in set
带有GROUP BY子句的SQL AVG示例
要计算组的平均值,将AVG函数与GROUP BY子句一起使用。 例如,以下语句返回各部门的员工和员工的平均工资。
SELECT department_id, AVG(salary) FROM employees GROUP BY department_id;
可以使用inner join子句将employees表与departments表连接起来以获取部门名称数据:
SELECT e.department_id, department_name, AVG(salary) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id;
带有ORDER BY子句的SQL AVG示例
要对包含AVG结果的结果集进行排序,请使用AVG函数与ORDER BY子句,如下所示:
SELECT e.department_id, department_name, AVG(salary) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id ORDER BY AVG(salary) DESC;
SQL AVG与HAVING子句示例
要过滤分组,请AVG函数中使用HAVING子句。 例如,以下语句获取平均薪水小于5000的部门:
SELECT e.department_id, department_name, AVG(salary) AS avgsalary FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id HAVING avgsalary<5000 ORDER BY AVG(salary) DESC;
执行上面查询语句,得到以下结果:
+---------------+-----------------+-----------+ | department_id | department_name | avgsalary | +---------------+-----------------+-----------+ | 1 | 管理 | 4400 | | 3 | 采购 | 4150 | +---------------+-----------------+-----------+ 2 rows in set
SQL AVG与子查询
可以在单个SQL语句中多次应用AVG函数来计算一组平均值的平均值。
例如,可以使用AVG函数计算每个部门员工的平均工资,并再次应用AVG函数来计算部门的平均工资。
以下查询演示了这个实现:
SELECT AVG(employee_sal_avg) FROM ( SELECT AVG(salary) employee_sal_avg FROM employees GROUP BY department_id ) t;
查询语句的工作原理。
- 子查询返回每个部门的一组员工平均工资。
- 外部查询返回部门的平均工资。
在本教程中,您学习了如何使用SQLAVG函数计算集合的平均值。
Count()函数
本教程将向您展示如何使用SQLCOUNT函数来获取组中的项目数。
1. SQL COUNT函数简介
SQL COUNT函数是一个聚合函数,它返回符合条件行数。 可以使用SELECT语句中的COUNT函数来获取员工数量,每个部门的员工数量,指定工作岗位的员工数量等。
以下是SQLCOUNT函数的语法:
COUNTC ([ALL | DISTINCT] expression);
COUNT函数的结果取决于传递给它的参数。
- 默认情况下,
COUNT函数使用ALL关键字,无论是否指定它。ALL关键字表示考虑组中的所有项目,包括重复值。 例如,如果有一个数据集合(1,2,3,3,4,4)并应用COUNT函数,则结果为6。 - 如果明确指定
DISTINCT关键字,则仅考虑唯一的非NULL值。 如果将COUNT函数应用于数据集(1,2,3,3,4,4),则COUNT函数返回4。
另一种形式的COUNT函数接受星号(*)作为参数如下:
COUNT(*)
COUNT(*)函数返回表中的行数,包括包含NULL值的行。
2. SQL COUNT函数示例
下面举一些例子来看看COUNT函数是如何工作的。将使用示例数据库中的employees表进行演示。
2.1. SQL COUNT(*)示例
要获取employees表中的行数,请使用COUNT(*)函数,如下所示:
SELECT COUNT(*) FROM employees;
执行上面查询语句,得到以下结果:
+----------+ | COUNT(*) | +----------+ | 40 | +----------+ 1 row in set
要查找在部门ID为6中工作的员工数量,请将WHERE子句添加到查询中,如下所示:
SELECT COUNT(*) FROM employees WHERE department_id = 6;
执行上面查询语句,得到以下结果:
+----------+ | COUNT(*) | +----------+ | 5 | +----------+ 1 row in set
同样,要查询工作岗位ID为9的员工数量,请使用以下语句:
SELECT COUNT(*) FROM employees WHERE job_id = 9;
执行上面查询语句,得到以下结果:
+----------+ | COUNT(*) | +----------+ | 5 | +----------+ 1 row in set
2.2. SQL COUNT与GROUP BY子句示例
要在结果集中获取部门名称,需要将employees表与departments表内连接,如下所示:
SELECT e.department_id, department_name, COUNT(*) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id;
2.3. SQL COUNT(*)带有ORDER BY子句的示例
可以在COUNT(*)函数使用ORDER BY子句对每个组的行数进行排序。 例如,以下语句获取每个部门的员工数,并根据员工数按降序对结果集进行排序。
SELECT e.department_id, department_name, COUNT(*) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id ORDER BY COUNT(*) DESC;
2.4. SQL COUNT带有HAVING子句的示例
要按COUNT(*)函数的结果过滤分组,需要在COUNT(*)函数使用HAVING子句。
例如,以下语句获取部门及其员工数量。 此外,它仅选择员工人数大于5的部门。
SELECT e.department_id, department_name, COUNT(*) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id HAVING COUNT(*) > 5 ORDER BY COUNT(*) DESC;
2.5. SQL COUNT(DISTINCT表达式)示例
要获取employees表中的工作岗位数,请将COUNT函数应用于job_id列,如下所示:
SELECT COUNT(job_id) FROM employees;
执行上面示例代码,得到以下结果:
+---------------+ | COUNT(job_id) | +---------------+ | 40 | +---------------+ 1 row in set
上面查询中返回结果为:40,其中包含重复的工作岗位ID。 我们希望找出工作岗位数量,则要删除重复项,那么要将DISTINCT关键字添加到COUNT函数,如下所示:
SELECT COUNT(DISTINCT job_id) FROM employees; +------------------------+ | COUNT(DISTINCT job_id) | +------------------------+ | 19 | +------------------------+ 1 row in set
可以使用COUNT DISTINCT获取经理数量,如下查询:
SELECT COUNT(DISTINCT manager_id) FROM employees; +----------------------------+ | COUNT(DISTINCT manager_id) | +----------------------------+ | 10 | +----------------------------+ 1 row in set
在本教程中,您学习了应用SQLCOUNT函数以获取组中行数的各种方法。
Max()函数
在本教程中,您将学习如何使用SQLMax函数查找组中的最大值。
1. SQL MAX函数简介
SQL提供MAX()函数,用于在一组值中查找最大值。 以下是MAX函数的语法。
MAX(expression)
MAX函数忽略NULL值。
与SUM,COUNT和AVG函数不同,DISTINCT选项不适用于MAX函数。
2. SQL MAX函数示例
我们将使用employees表来演示MAX函数的工作原理。
desc employees ; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
以下SELECT语句返回employees表中员工的最高薪水。
SELECT MAX(salary) FROM employees; +-------------+ | MAX(salary) | +-------------+ | 24000 | +-------------+ 1 row in set
要获得薪水最高的员工,请使用子查询,如下所示:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary = ( SELECT MAX(salary) FROM employees );
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+--------+ | employee_id | first_name | last_name | salary | +-------------+------------+-----------+--------+ | 100 | Steven | Lee | 24000 | +-------------+------------+-----------+--------+ 1 row in set
子查询返回最高薪水,外部查询获得薪水等于最高薪水的员工。
2.1. SQL MAX与GROUP BY示例
我们通常将MAX函数与GROUP BY子句结合使用来查找每个分组的最大值。
例如,可以使用MAX函数查找每个部门中员工的最高薪水,如下所示:
SELECT department_id, MAX(salary) FROM employees GROUP BY department_id;
要在结果中包含部门名称,我们将employees表与departments表连接,如下所示:
SELECT d.department_id, department_name, MAX(salary) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id;
2.2. SQL MAX带有ORDER BY示例
与其他聚合函数一样,要根据MAX函数的结果对结果集进行排序,必须将MAX函数放在ORDER BY子句中。
例如,以下语句返回每个部门中员工的最高工资,并根据最高工资对结果集进行排序。
SELECT d.department_id, department_name, MAX(salary) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id ORDER BY MAX(salary) DESC;
2.3. SQL MAX带有HAVING示例
在MAX函数使用HAVING子句将条件添加到GROUP BY子句汇总分组。
例如,要获得具有最高薪水大于12000的员工的部门,请在MAX函数使用HAVING子句,如下所示:
SELECT d.department_id, department_name, MAX(salary) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id HAVING MAX(salary) > 12000;
执行上面示例代码,得到以下结果:
+---------------+-----------------+-------------+ | department_id | department_name | MAX(salary) | +---------------+-----------------+-------------+ | 2 | 市场营销 | 13000 | | 8 | 销售 | 14000 | | 9 | 行政人员 | 24000 | +---------------+-----------------+-------------+ 3 rows in set
在本教程中,我们将演示如何使用MAX函数来查找一分组值中的最大值。
Min函数
本教程通过示例演示如何使用SQLMIN函数。 在本教程之后,您将了解如何有效地应用MIN函数以查找一组值中的最小值。
1. SQL MIN函数简介
SQLMIN函数返回一组值中的最小值。 以下演示了MIN函数的语法。
MIN(expression)
与MAX函数一样,MIN函数也忽略NULL值,DISTINCT选项不适用于MIN函数。
2. SQL MIN函数示例
我们将使用employees表来演示MIN函数的功能。
DESC employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
要查找员工的最低薪水,请将MIN函数应用于employees表的salary列。
SELECT MIN(salary) FROM employees; +-------------+ | MIN(salary) | +-------------+ | 2500 | +-------------+ 1 row in set
要获取薪水最低的员工的信息,请使用以下子查询:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary = ( SELECT MIN(salary) FROM employees );
执行上面查询语句,得到以下结果:
+-------------+------------+-----------+--------+ | employee_id | first_name | last_name | salary | +-------------+------------+-----------+--------+ | 119 | Karen | Zhang | 2500 | +-------------+------------+-----------+--------+ 1 row in set
首先,子查询返回最低工资。 然后,外部查询检索其薪水等于子查询返回的最低薪水的员工。
2.1. SQL MIN带有GROUP BY示例
我们经常将MIN函数与GROUP BY子句一起使用来查找每个分组中的最小值。
例如,以下查询返回每个部门(分组)中薪水最低的员工。
SELECT department_id, MIN(salary) FROM employees GROUP BY department_id;
执行上面查询语句,得到以下结果:
+---------------+-------------+ | department_id | MIN(salary) | +---------------+-------------+ | 1 | 4400 | | 2 | 6000 | | 3 | 2500 | | 4 | 6500 | | 5 | 2700 | | 6 | 4200 | | 7 | 10000 | | 8 | 6200 | | 9 | 17000 | | 10 | 6900 | | 11 | 8300 | +---------------+-------------+ 11 rows in set
GROUP BY子句按部门对员工进行分组。 对于每个分组,查询返回薪水最低的行。但是结果集无法看到部门的名称。
要在结果集中组合部门的名称,需要使用内部联接子句将employees表与departments连接,如下所示:
SELECT d.department_id, department_name, MIN(salary) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY d.department_id;
2.2. SQL MIN与ORDER BY示例
要通过MIN函数的结果对分组进行排序,需要在MIN函数之后使用ORDER BY子句。
以下查询首先检索每个部门中薪水最低的员工,然后按薪酬按升序对这些部门进行排序。
SELECT d.department_id, department_name, MIN(salary) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY d.department_id ORDER BY MIN(salary);
2.3. SQL MIN与HAVING示例
可以使用HAVING子句指定组的过滤条件。 要根据MIN函数的结果过滤分组,在MIN函数之后使用HAVING子句。
例如,以下查询检索每个部门中薪水最低的员工,并且只包括薪水低于3000的部门。
SELECT d.department_id, department_name, MIN(salary) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY d.department_id HAVING MIN(salary) < 3000;
执行上面查询语句,得到以下结果:
+---------------+-----------------+-------------+ | department_id | department_name | MIN(salary) | +---------------+-----------------+-------------+ | 3 | 采购 | 2500 | | 5 | 运输 | 2700 | +---------------+-----------------+-------------+ 2 rows in set
所以现在您应该知道如何使用SQLMIN函数来查找一个分组值中的最小值。
Sum()函数
在本教程中,我们将演示如何使用SQLSUM函数,此函数计算所有值或不同值的总和。
1. SQL SUM函数简介
SQLSUM函数是一个聚合函数,它返回所有或不同值的总和。需要注意的是,只能将SUM函数应用于数字列。
以下说明了SUM函数的语法。
SUM([ALL|DISTINCT] expression)
ALL运算符用于将聚合应用于所有值。SUM函数默认使用ALL运算符。
例如,如果有一组集合值:(1,2,3,3,NULL)。 使用SUM函数将返回9,请注意,SUM函数忽略NULL值。
要计算唯一值的总和,可以使用DISTINCT运算符,例如,集合(1,2,3,3,NULL)的SUM(DISTINCT)为6。
2. SQL SUM函数示例
我们将使用下面的employees表进行演示。
mysql> DESC employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
要获得所有员工的工资总和,我们将SUM函数应用于salary列,如下面的查询:
SELECT SUM(salary) FROM employees;
要计算在部门ID为5中工作的员工的工资总和,在上面的查询中添加一个WHERE子句,如下所示:
SELECT SUM(salary) FROM employees WHERE department_id = 5; +-------------+ | SUM(salary) | +-------------+ | 41200.00 | +-------------+ 1 row in set
2.1. SQL SUM带有GROUP BY子句的示例
我们经常将SUM函数与GROUP BY子句结合使用来计算分组的总和。
例如,要计算每个部门的员工工资总和,我们将SUM函数应用于salary列,并按department_id列对行进行分组,如下所示:
SELECT department_id, SUM(salary) FROM employees GROUP BY department_id;
2.2. SQL SUM带有ORDER BY子句的示例
假设希望将部门工资的总和按降序排序,我们在ORDER BY子句使用SUM函数,如下所示:
例如,如果要获取工资总和大于3000的部门信息,请使用以下语句:
SELECT e.department_id, department_name, SUM(salary) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id HAVING SUM(salary) > 30000 ORDER BY SUM(salary) DESC;
在本教程中,您学习了如何使用SUM函数计算集合中的值的总和。
Group By子句
在本教程中,您将学习如何使用SQLGROUP BY子句根据一列或多列对行进行分组。
1. SQL GROUP BY子句简介
分组是使用数据库时必须处理的最重要任务之一。 要将行分组,请使用GROUP BY子句。
GROUP BY子句是SELECT语句的可选子句,它根据指定列中的匹配值将行组合成组,每组返回一行。
经常将GROUP BY与MIN,MAX,AVG,SUM或COUNT等聚合函数结合使用,以计算为每个分组提供信息的度量。
以下是GROUP BY子句的语法。
SELECT column1, column2, AGGREGATE_FUNCTION (column3) FROM table1 GROUP BY column1, column2;
在SELECT子句中包含聚合函数不是强制性的。 但是,如果使用聚合函数,它将计算每个组的汇总值。
如果要在分组之前过滤行,请添加WHERE子句。 但是要过滤组,请使用HAVING子句。
需要强调的是,在对行进行分组之前应用WHERE子句,而在对行进行分组之后应用HAVING子句。 换句话说,WHERE子句应用于行,而HAVING子句应用于分组。
要对组进行排序,请在GROUP BY子句后添加ORDER BY子句。
GROUP BY子句中出现的列称为分组列。 如果分组列包含NULL值,则所有NULL值都汇总到一个分组中,因为GROUP BY子句认为NULL值相等。
2. SQL GROUP BY示例
我们将使用示例数据库中的employees和departments表来演示GROUP BY子句的工作方式。
要查找每个部门的员工数量,请按department_id列对员工进行分组,并将COUNT函数应用于每个组,如下所示:
SELECT department_id, COUNT(employee_id) headcount FROM employees GROUP BY department_id;
2.1. SQL GROUP BY带有INNER JOIN示例
要获取部门名称,请使用departments表将employees表连接,如下所示:
SELECT e.department_id, department_name, COUNT(employee_id) headcount FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id;
2.2. SQL GROUP BY带有ORDER BY示例
要按人数排序部门,请添加ORDER BY子句作为以下语句:
SELECT e.department_id, department_name, COUNT(employee_id) headcount FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id ORDER BY headcount DESC;
注意,可以在ORDER BY子句中使用headcount别名或COUNT(employee_id)。
2.3. SQL GROUP BY有HAVING示例
要查找人数大于5的部门,请使用HAVING子句,如下查询语句:
SELECT e.department_id, department_name, COUNT(employee_id) headcount FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id HAVING headcount > 5 ORDER BY headcount DESC;
执行上面查询语句,得到以下结果:
+---------------+-----------------+-----------+ | department_id | department_name | headcount | +---------------+-----------------+-----------+ | 5 | 运输 | 7 | | 3 | 采购 | 6 | | 10 | 财务 | 6 | | 8 | 销售 | 6 | +---------------+-----------------+-----------+ 4 rows in set
2.4. SQL GROUP BY与MIN,MAX和AVG示例
以下查询返回每个部门中员工的最低,最高和平均工资。
SELECT e.department_id, department_name, MIN(salary) min_salary, MAX(salary) max_salary, ROUND(AVG(salary), 2) average_salary FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id;
2.5. SQL GROUP BY带有SUM函数示例
要获得每个部门的总薪水,请将SUM函数应用于salary列,并通过department_id列分组员工,如下所示:
SELECT e.department_id, department_name, SUM(salary) total_salary FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id;
执行上面查询语句,得到以下结果:
+---------------+-----------------+--------------+ | department_id | department_name | total_salary | +---------------+-----------------+--------------+ | 1 | 管理 | 4400.00 | | 2 | 市场营销 | 19000.00 | | 3 | 采购 | 24900.00 | | 4 | 人力资源 | 6500.00 | | 5 | 运输 | 41200.00 | | 6 | IT | 28800.00 | | 7 | 公共关系 | 10000.00 | | 8 | 销售 | 57700.00 | | 9 | 行政人员 | 58000.00 | | 10 | 财务 | 51600.00 | | 11 | 会计 | 20300.00 | +---------------+-----------------+--------------+ 11 rows in set
2.6. SQL GROUP BY多列
到目前为止,您已经看到将所有员工分组为一列。 例如,以下子句 -
GROUP BY department_id
将所有具有相同值的行放在一个组的department_id列中。如何按department_id和job_id列中的值对员工进行分组?
GROUP BY department_id, job_id
此子句将在一个组的department_id和job_id列中为所有具有相同值的员工进行分组。
以下语句将同一组中department_id和job_id列中具有相同值的行分组,然后返回每个组的行。
SELECT e.department_id, department_name, e.job_id, job_title, COUNT(employee_id) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id INNER JOIN jobs j ON j.job_id = e.job_id GROUP BY e.department_id , e.job_id;
第2,3和5部门不止一个。
这是因为这些部门的员工有不同的工作。 例如,在运输部门,有2名员工在运输业务员工作,1名员工在库存员工作,4名员工在库存管理员工作。
2.7. SQL GROUP BY和DISTINCT
如果使用GROUP BY子句而不使用聚合函数,则GROUP BY子句的行为类似于DISTINCT运算符。
以下内容获取员工的电话号码,并按电话号码分组。
SELECT phone_number FROM employees GROUP BY phone_number;
以下语句还检索电话号码,但不使用GROUP BY子句,而是使用DISTINCT运算符。
ELECT DISTINCT phone_number FROM employees;
结果集是相同的,只是DISTINCT运算符返回的结果集没有排序。
在本教程中,我们向您展示了如何使用GROUP BY子句将行汇总到分组中,并将聚合函数应用于每个分组。
Having子句
本教程将向您介绍SQLHAVING子句,该子句用于为GROUP BY子句汇总的组指定条件。
1. SQL HAVING子句简介
在上一个教程中,我们学习了如何使用GROUP BY子句将行汇总到分组中,并将聚合函数(如MIN,MAX,SUM,COUNT,AVG)应用于每个分组。
要指定分组的条件,请使用HAVING子句。
HAVING子句通常与SELECT语句中的GROUP BY子句一起使用。 如果使用带GROUP BY子句的HAVING子句,HAVING子句的行为类似于WHERE子句。
以下是HAVING子句的语法:
SELECT column1, column2, AGGREGATE_FUNCTION (column3) FROM table1 GROUP BY column1, column2 HAVING group_condition;
请注意,HAVING子句紧跟在GROUP BY子句之后出现。
HAVING与WHERE
在通过GROUP BY子句将行汇总到分组之前,WHERE子句将条件应用于各个行。 但是,HAVING子句在将行分组到组之后将条件应用于组。
因此,需要注意的是,在GROUP BY子句之前应用WHERE子句之后应用HAVING子句。
2. SQL HAVING子句示例
我们将使用示例数据库中的employees和departments表进行演示。
要获取经理及其下属员工数量,请使用GROUP BY子句按管理员对员工进行分组,并使用COUNT函数计算下属员工数量。
以下查询实现了上面要求:
SELECT manager_id, first_name, last_name, COUNT(employee_id) direct_reports FROM employees WHERE manager_id IS NOT NULL GROUP BY manager_id;
要查找至少包含五个下属员工的经理,请在上面的查询中添加HAVING子句,如下所示:
SELECT manager_id, first_name, last_name, COUNT(employee_id) direct_reports FROM employees WHERE manager_id IS NOT NULL GROUP BY manager_id HAVING direct_reports >= 5;
执行上面查询语句,得到以下结果:
+------------+------------+-----------+----------------+ | manager_id | first_name | last_name | direct_reports | +------------+------------+-----------+----------------+ | 100 | Neena | Wong | 14 | | 101 | Nancy | Chen | 5 | | 108 | Daniel | Chen | 5 | | 114 | Alexander | Su | 5 | +------------+------------+-----------+----------------+ 4 rows in set
2.1. SQL HAVING与SUM函数示例
以下语句计算公司为每个部门支付的工资总和,并仅选择工资总和在20000和30000之间的部门。
SELECT department_id, SUM(salary) FROM employees GROUP BY department_id HAVING SUM(salary) BETWEEN 20000 AND 30000 ORDER BY SUM(salary);
执行上面查询语句,得到以下结果 -
+---------------+-------------+ | department_id | SUM(salary) | +---------------+-------------+ | 11 | 20300.00 | | 3 | 24900.00 | | 6 | 28800.00 | +---------------+-------------+ 3 rows in set
2.2. SQL HAVING与MIN函数示例
要查找具有最低工资大于10000的员工的部门,请使用以下查询:
SELECT e.department_id, department_name, MIN(salary) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id HAVING MIN(salary) >= 10000 ORDER BY MIN(salary);
执行上面查询语句,得到以下结果 -
+---------------+-----------------+-------------+ | department_id | department_name | MIN(salary) | +---------------+-----------------+-------------+ | 7 | 公共关系 | 10000 | | 9 | 行政人员 | 17000 | +---------------+-----------------+-------------+ 2 rows in set
以上查询的工作原理。
- 首先,使用
GROUP BY子句按部门对员工进行分组。 - 其次,使用
MIN函数查找每个分组最低工资。 - 第三,将条件应用于
HAVING子句。
2.3. SQL HAVING子句带有AVG函数的示例
要查找员工平均薪水在5000到7000之间的部门,请使用AVG函数如下查询语句:
SELECT e.department_id, department_name, ROUND(AVG(salary), 2) FROM employees e INNER JOIN departments d ON d.department_id = e.department_id GROUP BY e.department_id HAVING AVG(salary) BETWEEN 5000 AND 7000 ORDER BY AVG(salary);
执行上面示例代码,得到以下结果:
+---------------+-----------------+-----------------------+ | department_id | department_name | ROUND(AVG(salary), 2) | +---------------+-----------------+-----------------------+ | 6 | IT | 5760 | | 5 | 运输 | 5885.71 | | 4 | 人力资源 | 6500 | +---------------+-----------------+-----------------------+ 3 rows in set
在本教程中,您学习了如何使用SQLHAVING子句将条件应用于分组。
Grouping Sets运算符
在本教程中,您将学习如何使用SQLGROUPING SETS运算符生成多个分组集。
创建样本表
让我们创建一个名为inventory的新表来演示GROUPING SETS的功能。
首先,创建一个名为inventory的新表:
CREATE TABLE inventory ( warehouse VARCHAR(255), product VARCHAR(255) NOT NULL, model VARCHAR(50) NOT NULL, quantity INT, PRIMARY KEY (warehouse,product,model) );
第二步,将数据插入inventory表:
INSERT INTO inventory(warehouse, product, model, quantity)
VALUES('San Jose', 'iPhone','6s',100);
INSERT INTO inventory(warehouse, product, model, quantity)
VALUES('San Fransisco', 'iPhone','6s',50);
INSERT INTO inventory(warehouse, product, model, quantity)
VALUES('San Jose','iPhone','7',50);
INSERT INTO inventory(warehouse, product, model, quantity)
VALUES('San Fransisco', 'iPhone','7',10);
INSERT INTO inventory(warehouse, product, model, quantity)
VALUES('San Jose','iPhone','X',150);
INSERT INTO inventory(warehouse, product, model, quantity)
VALUES('San Fransisco', 'iPhone','X',200);
INSERT INTO inventory(warehouse, product, model, quantity)
VALUES('San Jose','Samsung','Galaxy S',200);
INSERT INTO inventory(warehouse, product, model, quantity)
VALUES('San Fransisco','Samsung','Galaxy S',200);
INSERT INTO inventory(warehouse, product, model, quantity)
VALUES('San Fransisco','Samsung','Note 8',100);
INSERT INTO inventory(warehouse, product, model, quantity)
VALUES('San Jose','Samsung','Note 8',150);
第三,查询inventory表中的数据:
SELECT * FROM inventory; +---------------+---------+----------+----------+ | warehouse | product | model | quantity | +---------------+---------+----------+----------+ | San Jose | iPhone | 6s | 100 | | San Fransisco | iPhone | 6s | 50 | | San Jose | iPhone | 7 | 50 | | San Fransisco | iPhone | 7 | 10 | | San Jose | iPhone | X | 150 | | San Fransisco | iPhone | X | 200 | | San Jose | Samsung | Galaxy S | 200 | | San Fransisco | Samsung | Galaxy S | 200 | | San Fransisco | Samsung | Note 8 | 100 | | San Jose | Samsung | Note 8 | 150 | +---------------+---------+----------+----------+ 10 rows in set
1. SQL GROUPING SETS简介
分组集是一组使用GROUP BY子句进行分组的列。 通常,单个聚合查询定义单个分组集。
以下示例定义分组集(仓库,产品)。 它返回仓库和产品中存储在库存中的库存单位数(SKU)。
SELECT warehouse, product, SUM(quantity) qty FROM inventory GROUP BY warehouse, product;
以下查询查找仓库的SKU数量。 它定义了分组集(warehouse):
SELECT warehouse, SUM(quantity) qty FROM inventory GROUP BY warehouse; +---------------+-----+ | warehouse | qty | +---------------+-----+ | San Fransisco | 560 | | San Jose | 650 | +---------------+-----+ 2 rows in set
以下查询返回产品的SKU数。 它定义了分组集(product):
SELECT product, SUM(quantity) qty FROM inventory GROUP BY product;
执行上面查询语句,得到以下结果:
+---------+-----+ | product | qty | +---------+-----+ | iPhone | 560 | | Samsung | 650 | +---------+-----+ 2 rows in set
以下查询查找所有仓库和产品的SKU数。 它定义了一个空的分组集()。
SELECT SUM(quantity) qty FROM inventory;
执行上面示例代码,得到以下结果:
+------+ | qty | +------+ | 1210 | +------+ 1 row in set
到目前为止,我们有四个分组集:(warehouse, product),(warehouse),(product)和()。 要使用单个查询返回所有分组集,可以使用UNION ALL运算符组合上面的所有查询。
UNION ALL要求所有结果集具有相同的列数,因此,需要将NULL添加到每个查询的选择列表中,如下所示:
SELECT warehouse, product, SUM(quantity) qty FROM inventory GROUP BY warehouse, product UNION ALL SELECT warehouse, null, SUM(quantity) qty FROM inventory GROUP BY warehouse UNION ALL SELECT null, product, SUM(quantity) qty FROM inventory GROUP BY product UNION ALL SELECT null, null, SUM(quantity) qty FROM inventory;
执行上面查询语句,得到以下结果 -
+---------------+---------+------+ | warehouse | product | qty | +---------------+---------+------+ | San Fransisco | iPhone | 260 | | San Fransisco | Samsung | 300 | | San Jose | iPhone | 300 | | San Jose | Samsung | 350 | | San Fransisco | NULL | 560 | | San Jose | NULL | 650 | | NULL | iPhone | 560 | | NULL | Samsung | 650 | | NULL | NULL | 1210 | +---------------+---------+------+ 9 rows in set
从输出中可以清楚地看到,查询生成了一个结果集,其中包含所有分组集的聚合。尽管查询按预期工作,但它有两个主要问题:
- 首先,查询语句很难阅读,因为它很冗长。
- 其次,它存在性能问题,因为数据库系统必须多次扫描库存表。
为解决这些问题,SQL提供了GROUPING SETS。GROUPING SETS是GROUP BY子句的一个选项。 GROUPING SETS在同一查询中定义多个分组集。
以下是GROUPING SETS选项的一般语法:
SELECT c1, c2, aggregate (c3) FROM table GROUP BY GROUPING SETS ( (c1, c2), (c1), (c2), () );
此查询定义了四个分组集(c1,c2),(c1),(c2)和()。可以使用GROUPING SETS将上面的UNION ALL子句查询重写:
SELECT warehouse, product, SUM (quantity) qty FROM inventory GROUP BY GROUPING SETS( (warehouse,product), (warehouse), (product), () );
执行上面查询语句,得到以下结果:
+---------------+---------+------+ | warehouse | product | qty | +---------------+---------+------+ | San Fransisco | iPhone | 260 | | San Fransisco | Samsung | 300 | | San Jose | iPhone | 300 | | San Jose | Samsung | 350 | | San Fransisco | NULL | 560 | | San Jose | NULL | 650 | | NULL | iPhone | 560 | | NULL | Samsung | 650 | | NULL | NULL | 1210 | +---------------+---------+------+ 9 rows in set
此查询比上面的查询更具可读性和执行速度,因为数据库系统不必多次读取库存表。
现在,应该知道如何使用SQL GROUPING SETS使用单个查询生成多个分组集。
Rollup
在本教程中,您将学习如何使用SQLROLLUP生成多个分组集。
1. SQL ROLLUP简介
ROLLUP是GROUP BY子句的扩展。 ROLLUP选项允许包含表示小计的额外行,通常称为超级聚合行,以及总计行。 通过使用ROLLUP选项,可以使用单个查询生成多个分组集。
SELECT warehouse, SUM(quantity) qty FROM inventory GROUP BY warehouse;
有关GROUPING SETS的更多信息,请查看分组集教程。
以下是SQLROLLUP的基本语法:
SELECT c1, c2, aggregate_function(c3) FROM table GROUP BY ROLLUP (c1, c2);
ROLLUP假定输入列之间存在层次结构。 例如,如果输入列是(c1,c2),则层次结构c1> c2。ROLLUP生成考虑此层次结构有意义的所有分组集。 这就是为什么我们经常使用ROLLUP来生成小计和总计以用于报告目的。
在上面的语法中,ROLLUP(c1,c2)生成以下三个分组集:
(c1,c2) (c1) ()
Oracle,Microsoft SQL Server和PostgreSQL支持此语法。 但是,MySQL的语法略有不同,如下所示:
SELECT c1, c2, aggregate_function(c3) FROM table_name GROUP BY c1, c2 WITH ROLLUP;
2. SQL ROLLUP示例
我们将使用在GROUPING SETS教程中设置的inventory表进行演示。
mysql> select * from inventory; +---------------+---------+----------+----------+ | warehouse | product | model | quantity | +---------------+---------+----------+----------+ | San Jose | iPhone | 6s | 100 | | San Fransisco | iPhone | 6s | 50 | | San Jose | iPhone | 7 | 50 | | San Fransisco | iPhone | 7 | 10 | | San Jose | iPhone | X | 150 | | San Fransisco | iPhone | X | 200 | | San Jose | Samsung | Galaxy S | 200 | | San Fransisco | Samsung | Galaxy S | 200 | | San Fransisco | Samsung | Note 8 | 100 | | San Jose | Samsung | Note 8 | 150 | +---------------+---------+----------+----------+ 10 rows in set
2.1. SQL ROLLUP有一个列示例
以下语句使用GROUP BY子句和SUM()函数按仓库查找总库存:
SELECT warehouse, SUM(quantity) FROM inventory GROUP BY warehouse; +---------------+---------------+ | warehouse | SUM(quantity) | +---------------+---------------+ | San Fransisco | 560 | | San Jose | 650 | +---------------+---------------+ 2 rows in set
要检索所有仓库中的总产品数,请将ROLLUP添加到GROUP BY子句,如下所示:
SELECT warehouse, SUM(quantity) FROM inventory GROUP BY ROLLUP(warehouse);
执行上面示例代码,得到以下结果:

正如在结果中看到的那样,warehouse列中的NULL值指定了总计超级聚合行。 在此示例中,ROLLUP选项使查询生成另一行,显示所有仓库中的总产品数量。
要使输出更具可读性,可以使用COALESCE()函数将NULL值替换All值,如下所示:
SELECT COALESCE(warehouse, 'All warehouses') AS warehouse, SUM(quantity) FROM inventory GROUP BY ROLLUP (warehouse);
执行上面示例代码,得到以下结果:

2.2. SQL ROLLUP有多列示例
以下语句按warehouse和product计算库存:
SELECT warehouse, product, SUM(quantity) FROM inventory GROUP BY warehouse, product;
执行上面示例代码,得到以下结果:

将ROLLUP添加到GROUP BY子句:
SELECT warehouse, product, SUM(quantity) FROM inventory GROUP BY ROLLUP (warehouse , product);
执行上面示例代码,得到以下结果:

请注意,输出包含两个分析级别的摘要信息,而不仅仅是一个:
- 在指定仓库的每组产品行之后,将显示一个额外的摘要行,显示总库存。 在这些行中,
product列中的值设置为NULL。 - 在所有行之后,将显示一个额外的摘要行,显示所有仓库和产品的总库存。 在这些行中,
warehouse和product列中的值设置为NULL。
2.3. SQL ROLLUP带有部分汇总的示例
可以使用ROLLUP执行部分汇总,以减少计算的小计数,如以下示例所示:
SELECT warehouse, product, SUM(quantity) FROM inventory GROUP BY warehouse, ROLLUP (product);
执行上面示例代码,得到以下结果:

在此示例中,ROLLUP仅为product列而不是warehouse列生成超级聚合摘要。
在本教程中,您学习了如何使用SQLROLLUP通过单个查询执行多级分析。
Union运算符
本教程将演示如何使用SQLUNION组合来自多个查询的两个或多个结果集,并解释UNION和UNION ALL之间的区别。
1. SQL UNION运算符简介
UNION运算符将两个或多个SELECT语句的结果集合并到一个结果集中。 以下语句说明了如何使用UNION运算符组合两个查询的结果集:
SELECT column1, column2 FROM table1 UNION [ALL] SELECT column3, column4 FROM table2;
要使用UNION运算符,可以编写单独的SELECT语句,并通过关键字UNION将它们连接起来。
SELECT语句返回的列必须具有相同或可转换的数据类型,大小和相同的顺序。
数据库系统首先执行两个SELECT语句来处理查询。 然后,它将两个单独的结果集合并为一个,并消除重复的行。 为了消除重复的行,数据库系统对每列的组合结果进行排序,并扫描它以查找彼此相邻的匹配行。
要保留结果集中的重复行,请使用UNION ALL运算符。
假设我们有两个结果集A(1,2)和B(2,3)。 下图说明了A UNION B结果:


联合与联接不同,联接组合了多个表的列,而联合组合了表的行。
2. SQL UNION示例
要从A表中获取数据,请使用以下SELECT语句:
SELECT id FROM A;
执行上面查询语句,得到以下结果:
SELECT id FROM A;
要从B表中检索数据,请使用以下语句:
mysql> SELECT id FROM B; +----+ | id | +----+ | 2 | | 3 | +----+ 2 rows in set
要组合这两个查询的结果集,请使用UNION运算符,如下所示:
SELECT id FROM a UNION SELECT id FROM b;
执行上面查询语句,得到以下结果:
+----+ | id | +----+ | 1 | | 2 | | 3 | +----+ 3 rows in set
结果集仅包含3行,因为UNION运算符删除了一个重复行。
3. SQL UNION ALL示例
要保留重复行,请使用UNION ALL运算符,如下所示:
SELECT id FROM a UNION ALL SELECT id FROM b;
执行上面查询语句,得到以下结果:
+----+ | id | +----+ | 1 | | 2 | | 2 | | 3 | +----+ 4 rows in set
4. SQL UNION带有ORDER BY示例
要对结果集进行排序,请在所有SELECT语句之后放置ORDER BY子句,如下所示:
SELECT id FROM a UNION SELECT id FROM b ORDER BY id DESC;
执行上面查询语句,得到以下结果:
+----+ | id | +----+ | 3 | | 2 | | 1 | +----+ 3 rows in set
数据库系统执行以下步骤:
- 首先,分别执行每个
SELECT语句。 - 其次,组合结果集并删除重复行以创建组合结果集。
- 第三,按
ORDER BY子句中指定的列对组合结果集进行排序。
实际上,我们经常使用UNION运算符来组合来自不同表的数据。 请参阅以下employees和dependents表:

以下语句使用UNION运算符组合员工和受抚养人的名字和姓氏。
SELECT first_name, last_name FROM employees UNION SELECT first_name, last_name FROM dependents ORDER BY last_name;
执行上面查询语句,得到以下结果:
+------------+-----------+ | first_name | last_name | +------------+-----------+ | Grace | Chen | | Dan | Chen | | Daniel | Chen | | Matthew | Chen | | John | Chen | | Valli | Chen | | Diana | Chen | | Helen | Chen | | Nancy | Chen | | Karl | Chen | | Matthew | Han | ..... | Guy | Zhang | | Karen | Zhang | | Ed | Zhao | | Britney | Zhao | | Jennifer | Zhao | | Susan | Zhou | | Uma | Zhou | | Bob | Zhou | | Lucille | Zhou | | Michael | Zhou | | Pat | Zhou | +------------+-----------+ 70 rows in set
在本教程中,您学习了如何使用UNION运算符组合来自多个查询的两个或多个结果集。
Intersect运算符
本教程解释了SQLINTERSECT运算符,并向演示如何应用它来获取两个或多个查询的交集。
1. SQL INTERSECT运算符简介
INTERSECT运算符是一个集合运算符,它从SELECT语句返回两个或多个结果集的不同行。
假设有两个表记录:A(1,2)和B(2,3)。
下图说明了A和B表的交集。

紫色部分是绿色和蓝色结果集的交集。
与UNION运算符一样,INTERSECT运算符从最终结果集中删除重复的行。以下语句说明了如何使用INTERSECT运算符查找两个结果集的交集。
SELECT id FROM a INTERSECT SELECT id FROM b;
要使用INTERSECT运算符,SELECT语句的列需要遵循以下规则:
- 列的数据类型必须兼容。
SELECT语句中的列数及其顺序必须相同。
3. SQL INTERSECT运算符示例
以下SELECT语句返回表A中的行:
SELECT id FROM A; +----+ | id | +----+ | 1 | | 2 | +----+ 2 rows in set
以下语句从表B中检索数据:
SELECT id FROM B; +----+ | id | +----+ | 2 | | 3 | +----+ 2 rows in set
以下语句使用INTERSECT运算符来获取两个查询的交集。
SELECT id FROM a INTERSECT SELECT id FROM b;
执行上面查询语句,得到以下结果:

SQL INTERSECT带有ORDER BY示例
要对INTERSECT运算符返回的结果集进行排序,请将ORDER BY子句放在所有语句的末尾。
例如,以下语句将INTERSECT运算符应用于A和B表,并按降序对id列的组合结果集进行排序。
SELECT id FROM a INTERSECT SELECT id FROM b ORDER BY id DESC
执行上面查询语句,得到以下结果:

使用INNER JOIN子句模拟SQL INTERSECT运算符
大多数关系数据库系统支持INTERSECT运算符,如Oracle数据库,Microsoft SQL Server,PostgreSQL等。但是,某些数据库系统(MySQL)不提供INTERSECT运算符。
要模拟SQL INTERSECT运算符,可以使用INNER JOIN子句,如下所示:
SELECT a.id FROM a INNER JOIN b ON b.id = a.id
它返回A表中与B表中匹配行的行,这些行产生与INTERSECT运算符相同的结果。
现在您应该对SQLINTERSECT运算符有一个很好的理解,并知道如何使用它来查找多个查询的交集。
Minus运算符
在本教程中,您将学习如何使用SQLMINUS运算符从另一个结果集中减去一个结果集。
1. SQL MINUS运算符简介
除了UNION,UNION ALL和INTERSECT运算符之外,SQL还为我们提供了MINUS运算符,用于从另一个结果集中减去一个结果集。
INTERSECT
以下是MINUS运算符的语法。
SELECT id FROM A MINUS SELECT id FROM B;
要使用MINUS运算符,可以编写单独的SELECT语句并将MINUS运算符放在它们之间。MINUS运算符返回第一个查询生成的唯一行,但不返回第二个查询生成的唯一行。
下图是MINUS运算符的说明。

为了获得结果集,数据库系统执行两个查询并从第二个查询中减去第一个查询的结果集。
要使用MINUS运算符,SELECT子句中的列必须匹配,并且必须具有相同或至少可转换的数据类型。
我们经常在ETL中使用MINUS运算符。 ETL是数据仓库系统中的软件组件。 ETL代表Extract,Transform和Load。 ETL负责将数据从源系统加载到数据仓库系统。
完成加载数据后,可以使用MINUS运算符通过从源系统中的数据中减去目标系统中的数据来确保数据已完全加载。
2. SQL MINUS示例
请考虑示例数据库中的 employees 和 dependents 表,它们的关系如下所示:
示例数据库

每个员工都有零个或多个家属,而每个员工依赖于一个且只有一个员工。 家属与员工之间的关系是一对多的关系。
dependents表中的employee_id列引用employees表中的employee_id列。
可以使用MINUS运算符查找没有任何家属的员工。 要执行此操作,请从dependents表中的employee_id结果集中减去employees表中的employee_id结果集。
以下查询实现了这个想法:
SELECT employee_id FROM employees MINUS SELECT employee_id FROM dependents;
执行上面查询语句,得到以下结果:

2.1. SQL MINUS使用ORDER BY示例
要对MINUS运算符返回的结果集进行排序,请将ORDER BY子句放在最后一个SELECT语句的末尾。
例如,要对没有任何家属的员工进行排序,请使用以下查询:
SELECT employee_id FROM employees MINUS SELECT employee_id FROM dependents ORDER BY employee_id;

通过本文的学习,现在您应该对SQLMINUS运算符有一个很好的理解,并知道如何应用它来比较两个结果集。
子查询
在本教程中,您将了解SQL子查询以及如何使用子查询来形成灵活的SQL语句。
1. SQL子查询基本
请考虑示例数据库中的以下员工(employees)和部门(departments)表:

假设要查找位置ID为1700的所有员工,可能会想出以下解决方案。
首先,找到位置ID为1700的所有部门:
SELECT * FROM departments WHERE location_id = 1700;
执行上面查询语句,得到以下结果:
+---------------+-----------------+-------------+ | department_id | department_name | location_id | +---------------+-----------------+-------------+ | 1 | 管理 | 1700 | | 3 | 采购 | 1700 | | 9 | 行政人员 | 1700 | | 10 | 财务 | 1700 | | 11 | 会计 | 1700 | +---------------+-----------------+-------------+ 5 rows in set
其次,使用上一个查询的部门ID列表,查找属于位置ID为1700的所有员工:
SELECT employee_id, first_name, last_name FROM employees WHERE department_id IN (1 , 3, 8, 10, 11) ORDER BY first_name , last_name;

该解决方案有两个问题。 首先,查询departments表以检查哪个部门属于位置ID为1700。
由于数据量较小,可以轻松获得部门列表。 但是,在具有大量数据的实际系统中,可能存在问题。
另一个问题是,只要想找到其它位置的员工,就必须修改查询。更好的解决方案是使用子查询。 根据定义,子查询是嵌套在另一个查询中的查询,例如:SELECT,INSERT,UPDATE或DELETE语句。 在本教程中,我们将重点介绍与SELECT语句一起使用的子查询。
在此示例中,可以重写上面的两个查询,如下所示:
SELECT employee_id, first_name, last_name FROM employees WHERE department_id IN (SELECT department_id FROM departments WHERE location_id = 1700) ORDER BY first_name , last_name;
放在括号内的查询称为子查询,它也称为内部查询或内部选择。 包含子查询的查询称为外部查询或外部选择。
要执行查询,首先,数据库系统必须执行子查询并将括号之间的子查询替换为其结果 - 位于位置ID为1700的多个部门ID - 然后执行外部查询。
可以在许多地方使用子查询,例如:
- 使用
IN或NOT IN运算符 - 比较运算符中
- 使用
EXISTS或NOT EXISTS运算符 - 使用
ANY或ALL运算符 - 在
FROM子句中 - 在
SELECT子句中
2. SQL子查询示例
下面我们举一些使用子查询来了解它们如何工作的例子。
2.1. 带有IN或NOT IN运算符的SQL子查询
在前面的示例中,已经了解了子查询如何与IN运算符一起使用。 以下示例使用带有NOT IN运算符的子查询来查找未找到位置ID为1700的所有员工:
SELECT employee_id, first_name, last_name FROM employees WHERE department_id NOT IN (SELECT department_id FROM departments WHERE location_id = 1700) ORDER BY first_name , last_name;
执行上面查询语句,得到以下结果:
+-------------+------------+-----------+ | employee_id | first_name | last_name | +-------------+------------+-----------+ | 103 | Alexander | Lee | | 193 | Britney | Zhao | | 104 | Bruce | Wong | | 179 | Charles | Yang | | 105 | David | Liang | | 107 | Diana | Chen | | 204 | Hermann | Wu | | 126 | Irene | Liu | | 177 | Jack | Yang | | 145 | John | Liu | | 176 | Jonathon | Yang | | 146 | Karen | Liu | | 178 | Kimberely | Yang | | 120 | Matthew | Han | | 121 | Max | Han | | 201 | Michael | Zhou | | 122 | Min | Liu | | 202 | Pat | Zhou | | 192 | Sarah | Yang | | 123 | Shanta | Liu | | 203 | Susan | Zhou | | 106 | Valli | Chen | +-------------+------------+-----------+ 22 rows in set
2.2. 带有比较运算符的SQL子查询
以下语法说明了子查询如何与比较运算符一起使用:
comparison_operator (subquery)
比较运算符是这些运算符之一:
- 等于(
=) - 大于(
>) - 小于(
<) - 大于或等于(
>=) - 小于等于(
<=) - 不相等(
!=)或(<>)
以下示例查找薪水最高的员工:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary = (SELECT MAX(salary) FROM employees) ORDER BY first_name , last_name;
执行上面示例代码,得到以下结果:
ORDER BY first_name , last_name; +-------------+------------+-----------+--------+ | employee_id | first_name | last_name | salary | +-------------+------------+-----------+--------+ | 100 | Steven | Lee | 24000 | +-------------+------------+-----------+--------+ 1 row in set
在此示例中,子查询返回所有员工的最高薪水,外部查询查找薪水等于最高员工的员工。
以下语句查询所有薪水都高于的平均薪水的员工:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);

在此示例中,首先,子查询返回所有员工的平均工资。 然后,外部查询使用大于运算符来查找工资大于平均值的所有员工。
2.3. 带有EXISTS或NOT EXISTS运算符的SQL子查询
EXISTS运算符检查子查询返回的行是否存在。 如果子查询包含任何行,则返回true。 否则,它返回false。
EXISTS运算符的语法如下:
EXISTSE (subquery )
NOT EXISTS运算符与EXISTS运算符相反。
NOT EXISTS (subquery)
以下示例查找至少有一名员工的薪水大于10000的所有部门:
SELECT department_name FROM departments d WHERE EXISTS( SELECT 1 FROM employees e WHERE salary > 10000 AND e.department_id = d.department_id) ORDER BY department_name;
执行上面查询语句,得到以下结果:

同样,以下语句查找所有没有薪水大于10000的员工的部门:
SELECT department_name FROM departments d WHERE NOT EXISTS( SELECT 1 FROM employees e WHERE salary > 10000 AND e.department_id = d.department_id) ORDER BY department_name;
执行上面查询语句,得到以下结果:

2.4. 带有ALL运算符的SQL子查询
子查询与ALL运算符一起使用时的语法如下:
comparison_operator ALL (subquery)
如果x大于子查询返回的每个值,则以下条件的计算结果为true。
x > ALL (subquery)
例如,假设子查询返回三个值:1,2和3。 如果x大于3,则以下条件的计算结果为true。
x > ALL (1,2,3)
以下查询使用GROUP BY子句和MIN()函数按部门查找最低工资:
SELECT MIN(salary) FROM employees GROUP BY department_id ORDER BY MIN(salary) DESC;

以下示例查找薪水大于每个部门最低薪水的所有员工:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary >= ALL (SELECT MIN(salary) FROM employees GROUP BY department_id) ORDER BY first_name , last_name;

2.5. 带有ANY运算符的SQL子查询
以下是带有ANY运算符的子查询的语法:
comparison_operator ANY (subquery)
例如,如果x大于子查询返回的任何值,则以下条件的计算结果为true。 因此,如果x大于1,则条件x> SOME(1,2,3)的计算结果为true。
x > ANY (subquery)
请注意,SOME运算符是ANY运算符的同义词,因此可以互换使用它们。
以下查询查找薪水大于或等于每个部门的最高薪水的所有员工。
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary >= SOME (SELECT MAX(salary) FROM employees GROUP BY department_id);
执行上面查询语句,得到以下结果:
+-------------+------------+-----------+--------+ | employee_id | first_name | last_name | salary | +-------------+------------+-----------+--------+ | 100 | Steven | Lee | 24000 | | 101 | Neena | Wong | 17000 | | 102 | Lex | Liang | 17000 | | 103 | Alexander | Lee | 9000 | | 104 | Bruce | Wong | 6000 | | 105 | David | Liang | 4800 | | 106 | Valli | Chen | 4800 | | 108 | Nancy | Chen | 12000 | ... ... | 200 | Jennifer | Zhao | 4400 | | 201 | Michael | Zhou | 13000 | | 202 | Pat | Zhou | 6000 | | 203 | Susan | Zhou | 6500 | | 204 | Hermann | Wu | 10000 | | 205 | Shelley | Wu | 12000 | | 206 | William | Wu | 8300 | +-------------+------------+-----------+--------+ 31 rows in set
在此示例中,子查询查找每个部门中员工的最高薪水。 外部查询查看这些值并确定哪个员工的工资大于或等于按部门划分的任何最高工资。
2.7. FROM子句中的SQL子查询
可以在SELECT语句的FROM子句中使用子查询,如下所示:
SELECT * FROM (subquery) AS table_name
在此语法中,表别名是必需的,因为FROM子句中的所有表都必须具有名称。
请注意,FROM子句中指定的子查询在MySQL中称为派生表,在Oracle中称为内联视图。
以下语句返回每个部门的平均工资:
SELECT AVG(salary) average_salary FROM employees GROUP BY department_id;

可以将此查询用作FROM子句中的子查询,以计算部门平均工资的平均值,如下所示:
SELECT ROUND(AVG(average_salary), 0) FROM (SELECT AVG(salary) average_salary FROM employees GROUP BY department_id) department_salary; +-------------------------------+ | ROUND(AVG(average_salary), 0) | +-------------------------------+ | 8536 | +-------------------------------+ 1 row in set
2.8. SELECT子句中的SQL子查询
可以在SELECT子句中使用表达式的任何位置使用子查询。 以下示例查找所有员工的工资,平均工资以及每个员工的工资与平均工资之间的差值。
SELECT employee_id, first_name, last_name, salary, (SELECT ROUND(AVG(salary), 0) FROM employees) average_salary, salary - (SELECT ROUND(AVG(salary), 0) FROM employees) difference FROM employees ORDER BY first_name , last_name;
执行上面查询语句,得到以下结果 -
+-------------+------------+-----------+--------+----------------+------------+ | employee_id | first_name | last_name | salary | average_salary | difference | +-------------+------------+-----------+--------+----------------+------------+ | 103 | Alexander | Lee | 9000 | 8060 | 940 | | 115 | Alexander | Su | 3100 | 8060 | -4960 | | 114 | Avg | Su | 11000 | 8060 | 2940 | | 193 | Britney | Zhao | 3900 | 8060 | -4160 | | 104 | Bruce | Wong | 6000 | 8060 | -2060 | | 179 | Charles | Yang | 6200 | 8060 | -1860 | | 109 | Daniel | Chen | 9000 | 8060 | 940 | | 105 | David | Liang | 4800 | 8060 | -3260 | ... ... | 192 | Sarah | Yang | 4000 | 8060 | -4060 | | 123 | Shanta | Liu | 6500 | 8060 | -1560 | | 205 | Shelley | Wu | 12000 | 8060 | 3940 | | 116 | Shelli | Zhang | 2900 | 8060 | -5160 | | 117 | Sigal | Zhang | 2800 | 8060 | -5260 | | 100 | Steven | Lee | 24000 | 8060 | 15940 | | 203 | Susan | Zhou | 6500 | 8060 | -1560 | | 106 | Valli | Chen | 4800 | 8060 | -3260 | | 206 | William | Wu | 8300 | 8060 | 240 | +-------------+------------+-----------+--------+----------------+------------+ 40 rows in set
通过上面的学习,现在您应该了解SQL子查询是什么,以及如何使用子查询来形成灵活的SQL语句。
相关子查询
在本教程中,您将了解SQL相关子查询,它是使用外部查询中的值的子查询。
1. SQL相关子查询简介
下面通过一个例子开始。
请参阅示例数据库中的employees表:
desc employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
以下查询查找薪水大于所有员工平均薪水的员工:
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
执行上面查询语句,得到以下结果:
+-------------+------------+-----------+--------+ | employee_id | first_name | last_name | salary | +-------------+------------+-----------+--------+ | 100 | Steven | Lee | 24000 | | 101 | Neena | Wong | 17000 | | 102 | Lex | Liang | 17000 | | 103 | Alexander | Lee | 9000 | | 108 | Nancy | Chen | 12000 | | 109 | Daniel | Chen | 9000 | | 110 | John | Chen | 8200 | | 114 | Avg | Su | 11000 | | 121 | Max | Han | 8200 | | 145 | John | Liu | 14000 | | 146 | Karen | Liu | 13500 | | 176 | Jonathon | Yang | 8600 | | 177 | Jack | Yang | 8400 | | 201 | Michael | Zhou | 13000 | | 204 | Hermann | Wu | 10000 | | 205 | Shelley | Wu | 12000 | | 206 | William | Wu | 8300 | +-------------+------------+-----------+--------+ 17 rows in set
在此示例中,子查询在WHERE子句中使用。可以从此查询中看到一些要点:
首先,可以执行子查询,此子查询独立返回所有员工的平均工资。
SELECT AVG(salary) FROM employees;
其次,数据库系统只需要对子查询进行一次评估。
第三,外部查询使用从子查询返回的结果。 外部查询依赖于子查询的值。 但是,子查询不依赖于外部查询。 有时,我们称这个子查询是一个普通的子查询。
与普通子查询不同,相关子查询是使用外部查询中的值的子查询。 此外,可以针对外部查询选择的每一行评估相关子查询一次。 因此,使用相关子查询的查询可能很慢。
相关子查询也称为重复子查询或同步子查询。
2. SQL相关的子查询示例
让我们看一下相关子查询的一些例子,以便更好地理解它们。
2.1. WHERE子句示例中的SQL相关子查询
以下查询查找薪水高于其部门员工平均薪水的所有员工:
SELECT employee_id,first_name,last_name,salary,department_id FROM employees e WHERE salary > (SELECT AVG(salary) FROM employees WHERE department_id = e.department_id) ORDER BY department_id , first_name , last_name;
执行上面查询语句,得到以下结果:

在此示例中,外部查询是:
SELECT employee_id, first_name, last_name, salary, department_id FROM employees e WHERE salary > ...
相关子查询是:
SELECT AVG( list_price ) FROM products WHERE category_id = p.category_id
对于每个员工,数据库系统必须执行一次相关子查询,以计算当前员工部门中员工的平均工资。
2.2. SELECT子句示例中的SQL相关子查询
以下查询返回员工及其部门中所有员工的平均薪水:
SELECT employee_id, first_name, last_name, department_name, salary, (SELECT ROUND(AVG(salary),0) FROM employees WHERE department_id = e.department_id) avg_salary_in_department FROM employees e INNER JOIN departments d ON d.department_id = e.department_id ORDER BY department_name, first_name, last_name;
执行上面查询语句,得到以下结果:
+-------------+------------+-----------+-----------------+--------+--------------------------+ | employee_id | first_name | last_name | department_name | salary | avg_salary_in_department | +-------------+------------+-----------+-----------------+--------+--------------------------+ | 103 | Alexander | Lee | IT | 9000 | 5760 | | 104 | Bruce | Wong | IT | 6000 | 5760 | | 105 | David | Liang | IT | 4800 | 5760 | | 107 | Diana | Chen | IT | 4200 | 5760 | | 106 | Valli | Chen | IT | 4800 | 5760 | | 203 | Susan | Zhou | 人力资源 | 6500 | 6500 | | 205 | Shelley | Wu | 会计 | 12000 | 10150 | ... ... | 119 | Karen | Zhang | 采购 | 2500 | 4150 | | 116 | Shelli | Zhang | 采购 | 2900 | 4150 | | 117 | Sigal | Zhang | 采购 | 2800 | 4150 | | 179 | Charles | Yang | 销售 | 6200 | 9617 | | 177 | Jack | Yang | 销售 | 8400 | 9617 | | 145 | John | Liu | 销售 | 14000 | 9617 | | 176 | Jonathon | Yang | 销售 | 8600 | 9617 | | 146 | Karen | Liu | 销售 | 13500 | 9617 | | 178 | Kimberely | Yang | 销售 | 7000 | 9617 | +-------------+------------+-----------+-----------------+--------+--------------------------+ 40 rows in set
对于每个员工,数据库系统必须执行一次相关子查询,以计算员工部门的平均工资。
2.3. SQL将子查询与EXISTS运算符示例相关联
经常使用与EXISTS运算符相关的子查询。 例如,以下查询返回没有依赖项的所有员工:
SELECT employee_id, first_name, last_name FROM employees e WHERE NOT EXISTS( SELECT * FROM dependents d WHERE d.employee_id = e.employee_id) ORDER BY first_name , last_name;

在本教程中,您了解了SQL相关子查询以及如何将其应用于形成复杂查询。
Exists运算符
在本教程中,您将学习如何使用SQLEXISTS运算符来测试子查询是否包含任何行。
1. SQL EXISTS运算符简介
EXISTS运算符用于指定子查询以测试行的存在。 以下是EXISTS运算符的语法:
EXISTS (subquery)
如果子查询包含任何行,则EXISTS运算符返回true。 否则它返回false。
EXISTS运算符在找到行后立即终止查询处理,因此,可以利用EXISTS运算符的此功能来提高查询性能。
2. SQL EXISTS运算符示例
我们将使用示例数据库中的employees和dependents表进行演示。

以下语句查找至少有一个家属的所有员工:
SELECT employee_id, first_name, last_name FROM employees WHERE EXISTS( SELECT 1 FROM dependents WHERE dependents.employee_id = employees.employee_id);
执行上面查询语句,得到以下结果:
+-------------+------------+-----------+ | employee_id | first_name | last_name | +-------------+------------+-----------+ | 100 | Steven | Lee | | 101 | Neena | Wong | | 102 | Lex | Liang | | 103 | Alexander | Lee | | 104 | Bruce | Wong | | 105 | David | Liang | | 106 | Valli | Chen | ... ... | 176 | Jonathon | Yang | | 200 | Jennifer | Zhao | | 201 | Michael | Zhou | | 202 | Pat | Zhou | | 203 | Susan | Zhou | | 204 | Hermann | Wu | | 205 | Shelley | Wu | | 206 | William | Wu | +-------------+------------+-----------+ 30 rows in set
子查询是相关的。 对于employees表中的每一行,子查询检查dependents表中是否有对应的行。 如果有匹配行,则子查询返回一个使外部查询包含employees表中的当前行的子查询。 如果没有相应的行,则子查询不返回导致外部查询不包括结果集中employees表中的当前行的行。
3. SQL NOT EXISTS
要取消EXISTS运算符,可以使用NOT运算符,如下所示:
NOT EXISTS (subquery)
例如,以下查询查找没有任何家属的员工:
SELECT employee_id, first_name, last_name FROM employees WHERE NOT EXISTS( SELECT 1 FROM dependents WHERE dependents.employee_id = employees.employee_id);
执行上面查询语句,得到以下结果:

4. SQL EXISTS和NULL
如果子查询返回NULL,则EXISTS运算符仍返回结果集。 这是因为EXISTS运算符仅检查子查询返回的行的存在。 行是否为NULL无关紧要。
在以下示例中,子查询返回NULL,但EXISTS运算符仍然计算为true:
SELECT employee_id, first_name, last_name FROM employees WHERE EXISTS( SELECT NULL) ORDER BY first_name , last_name;
该查询返回employees表中的所有行。
在本教程中,您学习了如何使用SQLEXISTS运算符来测试子查询返回的行的存在。
All运算符
在本教程中,您将了解SQL ALL运算符以及如何使用它来将值与一组值进行比较。
1. SQL ALL运算符简介
SQLALL运算符是一个逻辑运算符,它将单个值与子查询返回的单列值集进行比较。
以下是SQLALL运算符的语法:
WHERE column_name comparison_operator ALL (subquery)
SQLALL运算符必须以比较运算符开头,例如:>,>=,<,<=,<>,=,后跟子查询。 某些数据库系统(如Oracle)允许使用文字值列表而不是子查询。
请注意,如果子查询不返回任何行,则WHERE子句中的条件始终为true。 假设子查询返回一行或多行,下表说明了SQLALL运算符的含义:
| 条件 | 描述 |
|---|---|
c > ALL(…) |
c列中的值必须大于要评估为true的集合中的最大值。 |
c >= ALL(…) |
c列中的值必须大于或等于要评估为true的集合中的最大值。 |
c < ALL(…) |
c列中的值必须小于要评估为true的集合中的最小值。 |
c <= ALL(…) |
c列中的值必须小于或等于要评估为true的集合中的最小值。 |
c <> ALL(…) |
c列中的值不得等于要评估为true的集合中的任何值。 |
c = ALL(…) |
c列中的值必须等于要评估为true的集合中的任何值。 |
2. SQL All运算符示例
我们将使用示例数据库中的employees表进行演示:
2.1. SQL ALL使用大于运算符
以下查询查找column_name列中的值大于子查询返回的最大值的行:
SELECT * FROM table_name WHERE column_name > ALL (subquery);
例如,以下语句查找工资大于部门ID为2的员工最高工资的所有员工:
SELECT first_name, last_name, salary FROM employees WHERE salary > ALL (SELECT salary FROM employees WHERE department_id = 2) ORDER BY salary;
执行上面查询语句,得到以下结果:

下面通过查询部门ID为2中员工的最高薪水来验证它:
mysql> SELECT MAX(salary) FROM employees WHERE department_id = 2; +-------------+ | MAX(salary) | +-------------+ | 13000 | +-------------+ 1 row in set
此查询返回13000,该值小于使用上述ALL运算符的查询返回的任何薪水。
2.2. SQL ALL大于或等于运算符
下面显示了具有大于或等于运算符的SQLALL运算符的语法:
SELECT * FROM table_name WHERE column_name >= ALL (subquery);
该查询返回column_name列中的值大于或等于子查询返回的所有值的所有行。
例如,以下查询查找薪水大于或等于市场营销部门(department_id=2)员工最高薪水的所有员工:
SELECT first_name, last_name, salary FROM employees WHERE salary >= ALL (SELECT salary FROM employees WHERE department_id = 2) ORDER BY salary;
如上图中所示,Michael员工的薪水为13000,等于营销部门员工的最高薪水包含在结果集中。
2.3. SQL ALL使用小于运算符
以下说明了ALL运算符结合小于运算符一起使用的查询:
SELECT * FROM table_name WHERE column_name < ALL (subquery);
此查询返回column_name列中的值小于子查询返回的最小值的所有行。
以下语句查找市场营销部门(department_id=2)中员工的最低薪水:
SELECT MIN(salary) FROM employees WHERE department_id = 2; +-------------+ | MIN(salary) | +-------------+ | 6000 | +-------------+ 1 row in set
要查找薪水低于市场营销部门(department_id=2)员工最低薪水的所有员工,请使用ALL运算符和小于运算符,如下所示:
SELECT first_name, last_name, salary FROM employees WHERE salary < ALL (SELECT salary FROM employees WHERE department_id = 2) ORDER BY salary DESC;
2.4. SQL ALL小于或等于运算符
以下是ALL运算符与小于或等于运算符一起使用的语法:
SELECT * FROM table_name WHERE column_name <= ALL (subquery);
例如,以下语句查找薪水小于或等于市场营销部门(department_id=2)员工最低薪水的所有员工:
SELECT first_name, last_name, salary FROM employees WHERE salary <= ALL (SELECT salary FROM employees WHERE department_id = 2) ORDER BY salary DESC;
2.5. SQL ALL与不等于运算符
以下查询返回column_name列中的值不等于子查询返回的任何值的所有行:
SELECT * FROM table_name WHERE column_name <> ALL (subquery);
例如,要查找工资不等于每个部门平均工资的员工,请使用以下查询:
SELECT first_name, last_name, salary FROM employees WHERE salary <> ALL (SELECT AVG(salary) FROM employees GROUP BY department_id) ORDER BY salary DESC;
执行以上查询语句,得到以下结果:
+------------+-----------+--------+ | first_name | last_name | salary | +------------+-----------+--------+ | Steven | Lee | 24000 | | Neena | Wong | 17000 | | Lex | Liang | 17000 | | John | Liu | 14000 | | Karen | Liu | 13500 | | Michael | Zhou | 13000 | | Nancy | Chen | 12000 | | Shelley | Wu | 12000 | | Avg | Su | 11000 | | Alexander | Lee | 9000 | ... ... | Shelli | Zhang | 2900 | | Sigal | Zhang | 2800 | | Irene | Liu | 2700 | | Guy | Zhang | 2600 | | Karen | Zhang | 2500 | +------------+-----------+--------+ 35 rows in set
请注意,子查询通过使用AVG()函数和GROUP BY子句查找部门员工的平均工资。
2.6. SQL ALL与等于运算符
当将ALL运算符与等于运算符一起使用时,查询将查找column_name列中的值等于子查询返回的任何值的所有行:
SELECT * FROM table_name WHERE column_name = ALL (subquery);
以下示例查找薪水等于市场营销部门(department_id=2)员工最高薪水的所有员工:
SELECT first_name, last_name, salary FROM employees WHERE salary = ALL (SELECT MAX(salary) FROM employees WHERE department_id = 2);
执行上面查询语句,得到以下结果:
+------------+-----------+--------+ | first_name | last_name | salary | +------------+-----------+--------+ | Michael | Zhou | 13000 | +------------+-----------+--------+ 1 row in set
在本教程中,您学习了如何使用SQLALL运算符来测试值是否与子查询返回的值集匹配。
Any运算符
在本教程中,您将了解SQLANY运算符以及如何使用它来将值与一组值进行比较。
1. SQL ANY运算符简介
ANY运算符是一个逻辑运算符,它将值与子查询返回的一组值进行比较。ANY运算符必须以比较运算符:>,>=,<,<=,=,<>开头,后跟子查询。
以下是ANY运算符的语法:
WHERE column_name comparison_operator ANY (subquery)
如果子查询不返回任何行,则条件的计算结果为false。 假设子查询不返回零行,下面说明了ANY运算符与每个比较运算符一起使用时的含义:
| 条件 | 表示含义 |
|---|---|
x = ANY (…) |
c列中的值必须与集合中的一个或多个值匹配,以评估为true。 |
x != ANY (…) |
c列中的值不能与集合中的一个或多个值匹配以评估为true。 |
x > ANY (…) |
c列中的值必须大于要评估为true的集合中的最小值。 |
x < ANY (…) |
c列中的值必须小于要评估为true的集合中的最大值。 |
x >= ANY (…) |
c列中的值必须大于或等于要评估为true的集合中的最小值。 |
x <= ANY (…) |
c列中的值必须小于或等于要评估为true的集合中的最大值。 |
2. SQL ANY示例
在下面示例中,我们将使用示例数据库中的employees表:
mysql> DESC employees; +---------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+----------------+ | employee_id | int(11) | NO | PRI | NULL | auto_increment | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(25) | NO | | NULL | | | email | varchar(100) | NO | | NULL | | | phone_number | varchar(20) | YES | | NULL | | | hire_date | date | NO | | NULL | | | job_id | int(11) | NO | MUL | NULL | | | salary | decimal(8,2) | NO | | NULL | | | manager_id | int(11) | YES | MUL | NULL | | | department_id | int(11) | YES | MUL | NULL | | +---------------+--------------+------+-----+---------+----------------+ 10 rows in set
2.1. SQL ANY等于运算符示例以下语句使用AVG()函数和GROUP BY子句来查找每个部门的平均工资:
SELECT ROUND(AVG(salary), 2) FROM employees GROUP BY department_id ORDER BY AVG(salary) DESC;
执行上面示例代码,得到以下结果:

要查找工资等于所在部门平均工资的所有员工,请使用以下查询:
SELECT first_name, last_name, salary FROM employees WHERE salary = ANY ( SELECT AVG(salary) FROM employees GROUP BY department_id) ORDER BY first_name, last_name, salary;
执行上面示例代码,得到以下结果:

2.2. SQL ANY与不等于运算符的示例
同样,以下查询查找工资不等于每个部门平均工资的所有员工:
SELECT first_name, last_name, salary FROM employees WHERE salary <> ANY (SELECT AVG(salary) FROM employees GROUP BY department_id) ORDER BY first_name, last_name, salary;
执行上面示例代码,得到以下结果:
+------------+-----------+--------+ | first_name | last_name | salary | +------------+-----------+--------+ | Alexander | Lee | 9000 | | Alexander | Su | 3100 | | Avg | Su | 11000 | | Britney | Zhao | 3900 | ... ... | Sigal | Zhang | 2800 | | Steven | Lee | 24000 | | Susan | Zhou | 6500 | | Valli | Chen | 4800 | | William | Wu | 8300 | +------------+-----------+--------+ 40 rows in set
2.3. SQL ANY和大于运算符的示例
以下查询查找薪水大于每个部门平均薪水的所有员工:
SELECT first_name, last_name, salary FROM employees WHERE salary > ANY (SELECT AVG(salary) FROM employees GROUP BY department_id) ORDER BY salary;
执行上面查询语句,得到以下结果 -
+------------+-----------+--------+ | first_name | last_name | salary | +------------+-----------+--------+ | Diana | Chen | 4200 | | Jennifer | Zhao | 4400 | | David | Liang | 4800 | | Valli | Chen | 4800 | | Bruce | Wong | 6000 | | Pat | Zhou | 6000 | | Charles | Yang | 6200 | | Shanta | Liu | 6500 | ... ... | Karen | Liu | 13500 | | John | Liu | 14000 | | Neena | Wong | 17000 | | Lex | Liang | 17000 | | Steven | Lee | 24000 | +------------+-----------+--------+ 32 rows in set
请注意,最低平均工资是4150。 上面的查询返回薪水大于最低薪水的所有员工。
2.4. SQL ANY使用大于或等于运算符示例
以下语句将返回薪水大于或等于每个部门平均薪水的所有员工:
SELECT first_name, last_name, salary FROM employees WHERE salary >= ANY (SELECT AVG(salary) FROM employees GROUP BY department_id) ORDER BY first_name , last_name , salary;
执行上面查询语句,得到以下结果 -
+------------+-----------+--------+ | first_name | last_name | salary | +------------+-----------+--------+ | Alexander | Lee | 9000 | | Avg | Su | 11000 | | Bruce | Wong | 6000 | | Charles | Yang | 6200 | | Daniel | Chen | 9000 | | David | Liang | 4800 | | Diana | Chen | 4200 | | Hermann | Wu | 10000 | ... ... | Pat | Zhou | 6000 | | Shanta | Liu | 6500 | | Shelley | Wu | 12000 | | Steven | Lee | 24000 | | Susan | Zhou | 6500 | | Valli | Chen | 4800 | | William | Wu | 8300 | +------------+-----------+--------+ 32 rows in set
2.5. SQL ANY使用小于运算符的示例
以下查询查找薪水低于每个部门平均薪水的所有员工:
SELECT first_name, last_name, salary FROM employees WHERE salary < ANY (SELECT AVG(salary) FROM employees GROUP BY department_id) ORDER BY salary DESC;
执行上面查询语句,得到以下结果 -
+------------+-----------+--------+ | first_name | last_name | salary | +------------+-----------+--------+ | Neena | Wong | 17000 | | Lex | Liang | 17000 | | John | Liu | 14000 | | Karen | Liu | 13500 | | Michael | Zhou | 13000 | | Nancy | Chen | 12000 | | Shelley | Wu | 12000 | ... ... | Alexander | Su | 3100 | | Shelli | Zhang | 2900 | | Sigal | Zhang | 2800 | | Irene | Liu | 2700 | | Guy | Zhang | 2600 | | Karen | Zhang | 2500 | +------------+-----------+--------+ 39 rows in set
在此示例中,员工的工资小于每个部门的最高平均工资:
2.6. SQL ANY使用小于或等于运算符示例
要查找工资小于或等于每个部门平均工资的员工,请使用以下查询:
SELECT first_name, last_name, salary FROM employees WHERE salary <= ANY (SELECT AVG(salary) FROM employees GROUP BY department_id) ORDER BY salary DESC;
执行上面查询语句,得到以下结果 -
+------------+-----------+--------+ | first_name | last_name | salary | +------------+-----------+--------+ | Neena | Wong | 17000 | | Lex | Liang | 17000 | | John | Liu | 14000 | | Karen | Liu | 13500 | | Michael | Zhou | 13000 | | Nancy | Chen | 12000 | | Shelley | Wu | 12000 | ... ... | Alexander | Su | 3100 | | Shelli | Zhang | 2900 | | Sigal | Zhang | 2800 | | Irene | Liu | 2700 | | Guy | Zhang | 2600 | | Karen | Zhang | 2500 | +------------+-----------+--------+ 39 rows in set
如上结果所示,结果集包括员工的工资低于或等于每个部门的最高平均工资。
现在,您应该知道如何使用SQLANY运算符通过将值与一组值进行比较来形成条件。
主键约束
在本教程中,将介绍主键以及如何使用SQLPRIMARY KEY约束向表中添加主键。
1. SQL中的主键是什么?
表由列和行组成。 通常,表具有一列或多列,列的值唯一地标识表中的每一行。 此列或多列称为主键。
由两列或更多列组成的主键也称为复合主键。
请参阅以下课程(courses)表。

由于course_id列中的值唯一标识courses表中的第一行,因此course_id列是courses表的主键。
每个表都有一个且只有一个主键。 主键不接受NULL或重复值。如果主键由两列或更多列组成,则值可能在一列中重复,但主键中所有列的值组合必须是唯一的。
training表的主键包含employee_id和course_id列。course_id列中的值是重复的,但employee_id和course_id中的值组合不是重复的。
2. 使用PRIMARY KEY创建表
通常,在创建表时定义主键。 如果主键由一列组成,则可以使用PRIMARY KEY约束作为列或表约束。 如果主键由两列或更多列组成,则必须使用PRIMARY KEY约束作为表约束。
假设要在数据库中管理公司的项目和项目分配。 则需要创建两个表:projects和project_assignments。
以下语句创建项目(projects)表:
CREATE TABLE projects ( project_id INT PRIMARY KEY, project_name VARCHAR(255), start_date DATE NOT NULL, end_date DATE NOT NULL );
可以在列定义中添加PRIMARY KEY,以使project_id列成为projects表的主键。以下语句等效于上述语句,但它不使用PRIMARY KEY约束作为列约束,而是使用表约束。
CREATE TABLE projects ( project_id INT, project_name VARCHAR(255), start_date DATE NOT NULL, end_date DATE NOT NULL, CONSTRAINT pk_id PRIMARY KEY (project_id) );
可以使用CREATE TABLE语句末尾的CONSTRAINT子句将project_id列指定为主键。
要存储表示分配给哪个项目的项目分配,需要使用以下语句创建project_assignments表:
CREATE TABLE project_assignments ( project_id INT, employee_id INT, join_date DATE NOT NULL, CONSTRAINT pk_assgn PRIMARY KEY (project_id , employee_id) );
由于主键由两列组成:project_id和employee_id,因此必须使用PRIMARY KEY作为表约束。
3. 使用ALTER TABLE语句添加主键
首先,使用CREATE TABLE语句定义没有主键的表,尽管这不是一个好习惯。 然后,使用ALTER TABLE语句将主键添加到表中。
例如,以下语句创建没有主键的project_milestones表。project_milesones存储项目的进度。
CREATE TABLE project_milestones( milestone_id INT, project_id INT, milestone_name VARCHAR(100) );
现在,可以使用以下ALTER TABLE语句将milestone_id列设置为主键。
ALTER TABLE project_milestones ADD CONSTRAINT pk_milestone_id PRIMARY KEY (milestone_id);
可以跳过CONSTRAINT子句,如下所示:
ALTER TABLE project_milestones ADD PRIMARY KEY (milestone_id);
4. 删除主键约束
一般很少删除表的主键。 但是,如果必须这样做,可以使用ALTER TABLE语句,如下所示:
ALTER TABLE table_name DROP CONSTRAINT primary_key_constraint;
如果使用的是MySQL,则删除主键的语法更简单,如下所示:
ALTER TABLE table_name DROP PRIMARY KEY;
例如,要删除project_milestones表的主键约束,请使用以下语句。
ALTER TABLE project_milestones DROP CONSTRAINT pk_milestone_id;
在本教程中,我们介绍了主键概念,并向展示了如何管理表的主键,包括添加和删除主键。
外键
在本教程中,将学习SQL外键以及如何创建FOREIGN KEY约束以强制表之间的关系。
1. SQL外键约束简介
外键是一列或一组列,用于强制两个表中的数据之间的链接。 在外键引用中,第一个表的主键列(或多个列)由第二个表的列(或列)引用。 第二个表的列(或列)成为外键。
在创建或更改表时,可以使用FOREIGN KEY约束创建外键。 下面来看一个简单的例子以更好地理解。
2. SQL FOREIGN KEY约束示例
请参阅以下project表和project_assignments表:
CREATE TABLE projects ( project_id INT AUTO_INCREMENT PRIMARY KEY, project_name VARCHAR(255), start_date DATE NOT NULL, end_date DATE NOT NULL ); CREATE TABLE project_milestones( milestone_id INT AUTO_INCREMENT PRIMARY KEY, project_id INT, milestone_name VARCHAR(100) );
每个项目可能有零个或多个里程碑,而一个里程碑必须属于一个且只有一个项目。 使用这些表的应用程序必须确保project_milestones表中的每一行都在projects表中存在相应的行。 换句话说,没有项目就不可能存在里程碑。
不幸的是,用户可能使用客户端工具编辑数据库,或者如果应用程序中存在错误,则可能会在project_milestones表中添加一行,该行不对应于项目表中的任何行。 或者用户可以删除项目表中的行,在project_milestones表中留下孤立的行。 这会导致应用程序无法正常工作。
解决方案是向project_milestones表添加SQLFOREIGN KEY约束,以强制执行project表和project_milestones表之间的关系。
可以在创建表时创建FOREIGN KEY约束,如下所示:
CREATE TABLE project_milestones ( milestone_id INT AUTO_INCREMENT PRIMARY KEY, project_id INT, milestone_name VARCHAR(100), FOREIGN KEY (project_id) REFERENCES projects (project_id) );
FOREIGN KEY子句将project_milestones表的project_id设置为引用project表的project_id列的外键。
FOREIGN KEY (project_id) REFERENCES projects (project_id)
可以为FOREIGN KEY约束指定名称,如下所示:
CREATE TABLE project_milestones ( milestone_id INT AUTO_INCREMENT PRIMARY KEY, project_id INT, milestone_name VARCHAR(100), CONSTRAINT fk_project FOREIGN KEY (project_id) REFERENCES projects (project_id) );
hk_project是FOREIGN KEY约束的名称。将FOREIGN KEY约束添加到现有表
,要向现有表添加FOREIGN KEY约束,请使用ALTER TABLE语句。
ALTER TABLE table_1 ADD CONSTRAINT fk_name FOREIGN KEY (fk_key_column) REFERENCES table_2(pk_key_column)
假设project_milestones列已经存在,但是没有任何预定义的外键,如果想要为project_id列定义FOREIGN KEY约束。 为此,请使用以下ALTER TABLE语句:
ALTER TABLE project_milestones ADD CONSTRAINT fk_project FOREIGN KEY(project_id) REFERENCES projects(project_id);
3. 删除外键约束
要删除外键约束,还要使用ALTER TABLE语句,如下所示:
ALTER TABLE table_name DROP CONSTRAINT fk_name;
如果使用的是MySQL,则可以使用更清晰的语法,如下所示:
ALTER TABLE table_name DROP FOREIGN KEY fk_name;
例如,要删除fk_project外键约束,请使用以下语句:
ALTER TABLE project_milestones DROP CONSTRAINT fk_project;
在本教程中,我们介绍了外键概念,并演示了如何使用SQLFOREIGN KEY约束创建和删除外键。
唯一约束
在本教程中,将学习如何使用SQLUNIQUE约束强制列或一组列中值的唯一性。
1. 什么是SQL UNIQUE约束
有时,希望确保一列或多列中的值不重复。 例如,employees表中不能接受的重复电子邮件。由于电子邮件列不是主键的一部分,因此防止电子邮件列中重复值的唯一方法是使用UNIQUE约束。
根据定义,SQLUNIQUE约束定义了一个规则,该规则可防止存储在不参与主键的特定列中有重复值。
UNIQUE与PRIMARY KEY约束比较
PRIMARY KEY约束最多只能有一个,而表中可以有多个UNIQUE约束。 如果表中有多个UNIQUE约束,则所有UNIQUE约束必须在不同的列集。
与PRIMARY KEY约束不同,UNIQUE约束允许NULL值。 这取决于RDBMS要考虑NULL值是否唯一。
例如,MySQL将NULL值视为不同的值,因此,可以在参与UNIQUE约束的列中存储多个NULL值。 但是,Microsoft SQL Server或Oracle数据库不是这种情况。
下表说明了UNIQUE约束和PRIMARY KEY约束之间的区别:
| 比较项 | PRIMARY KEY约束 | UNIQUE约束 |
|---|---|---|
| 约束的数量 | 一个 | 多个 |
| NULL值 | 不允许 | 允许 |
2. 创建UNIQUE约束
通常,在创建表时创建UNIQUE约束。 以下CREATE TABLE语句定义users表,其中username列是唯一的。
CREATE TABLE users ( user_id INT AUTO_INCREMENT PRIMARY KEY, username VARCHAR(255) NOT NULL UNIQUE, password VARCHAR(255) NOT NULL );
要为列创建UNIQUE约束,需要在列定义中添加UNIQUE关键字。 在这个示例中,创建了UNIQUE约束作为列约束。
如果插入或更新与username列中已存在的值相同的值,则RDBMS将拒绝更改并返回错误。以下语句等效于使用表约束语法创建的UNIQUE约束的上述语句。
CREATE TABLE users ( user_id INT AUTO_INCREMENT PRIMARY KEY, username VARCHAR(255) NOT NULL, password VARCHAR(255) NOT NULL, CONSTRAINT uc_username UNIQUE (username) );
在这个示例中,将CONSTRAINT子句放在CREATE TABLE语句的末尾。
3. 将UNIQUE约束添加到现有表
如果表已存在,则可以为列添加UNIQUE约束,前提条件是参与UNIQUE约束的列或列组合必须包含唯一值。
假设创建的users表没有为username列定义UNIQUE约束。 要将UNIQUE约束添加到username列,请使用ALTER TABLE语句,如下所示:
ALTER TABLE users ADD CONSTRAINT uc_username UNIQUE(username);
如果要添加新列并为创建UNIQUE约束,请使用以下形式的ALTER TABLE语句。
ALTER TABLE users ADD new_column data_type UNIQUE;
例如,以下语句将带有UNIQUE约束的email列添加到users表。
ALTER TABLE users ADD email VARCHAR(255) UNIQUE;
4. 删除UNIQUE约束
要删除UNIQUE约束,请使用ALTER TABLE语句,如下所示:
ALTER TABLE table_name DROP CONSTRAINT unique_constraint_name;
例如,要删除users表中的uc_username唯一约束,请使用以下语句。
ALTER TABLE users DROP CONSTRAINT uc_username;
在本教程中,我们学习了UNIQUE约束以及如何应用它来强制一列或多列中值的唯一性。
Not Null约束
本教程将演示如何使用SQLNOT NULL约束来强制列存储NULL值。
1. SQL NOT NULL约束简介
NOT NULL约束是一个列约束,它定义将列限制为仅具有非NULL值的规则。
这意味着当使用INSERT语句向表中插入新行时,必须指定NOT NULL列的值。以下语句是NOT NULL约束语法。 它强制column_name不能接受NULL值。
CREATE TABLE table_name( ... column_name data_type NOT NULL, ... );
逻辑上,NOT NULL约束等同于CHECK约束,因此,上述语句等效于以下语句。
CREATE TABLE table_name ( ... column_name data_type, ... CHECK (column_name IS NOT NULL) );
例如,以下语句创建一个名称为training表,表中有带一个NOT NULL约束的taken_date列。
CREATE TABLE training ( employee_id INT, course_id INT, taken_date DATE NOT NULL, PRIMARY KEY (employee_id , course_id) );
大多数关系数据库管理系统默认情况下会自动将NOT NULL约束添加到主键列,因此不必明确指定它。
以下INSERT语句违反了NOT NULL约束。
INSERT INTO training(employee_id,course_id) VALUES(1,1);
上面插入语句中,taken_date列未指定值,因此默认使用NULL值,但是taken_date列指定了NOT NULL约束,所以插入数据时会出现错误。
2. ALTER TABLE NOT NULL语句
通常,在创建表时为列定义NOT NULL约束。 但是,有时希望更改列的约束以接受NULL值。
要进行更改以接受NULL值,可参考以下两个步骤:
首先,使用UPDATE语句将所有当前NULL值更新为非NULL值。
UPDATE table_name SET column_name = 0 WHERE column_name IS NULL;
请注意,在WHERE子句中使用IS NULL运算符来查找column_name为NULL的行。
其次,使用ALTER TABLE语句将NOT NULL约束添加到列
ALTER TABLE table_name MODIFY column_name data_type NOT NULL;
假设training表的taken_date列为NULL,想将它更改为NOT NULL。
首先,将taken_date列中的所有NULL值更新为特定日期,例如:当前日期。
UPDATE training SET taken_date = CURRENT_DATE () WHERE taken_date IS NULL;
其次,将take_date列更改为NOT NULL约束。
ALTER TABLE training MODIFY taken_date date NOT NULL;
在本教程中,讲解了NOT NULL约束的概念,并演示了如何使用NOT NULL约束将列约束为仅接受非NULL值。
检查约束
在本教程中,将学习如何使用SQLCHECK约束来验证基于布尔表达式的列或一组列中的数据。
1. SQL CHECK约束简介
CHECK约束是SQL中的完整性约束,它允许指定列或列集中的值必须满足布尔表达式。
可以在单个列或整个表上定义CHECK约束。 如果在单个列上定义CHECK约束,则CHECK约束仅检查此列的值。 但是,如果在表上定义CHECK约束,则会根据同一行的其他列中的值限制列中的值。
CHECK约束由关键字CHECK后跟括号中的布尔表达式组成:
CHECK(Boolean_expression)
如果要为CHECK约束指定名称,请使用以下语法:
CONSTRAINT constraint_name CHECK(Boolean_expression)
值得注意的是,当布尔表达式返回true或NULL值时,视为满足CHECK约束。 如果其中一个操作数为NULL,则布尔表达式求值为NULL,它们不会阻止约束列存储NULL值。 若要确保该列不包含NULL值,请使用NOT NULL约束。
2. SQL CHECK约束示例
下面来看一些创建CHECK约束的例子。
要创建一个products表,其products_price列中的值必须为正数,请使用以下CREATE TABLE语句:
CREATE TABLE products ( product_id INT PRIMARY KEY, product_name VARCHAR(255) NOT NULL, selling_price NUMERIC(10,2) CHECK (selling_price > 0) );
CHECK约束位于列的数据类型之后。 如果使用负值插入或更新售价,则表达sell_price> = 0将返回false,并且RDMBS将返回错误。
可以为CHECK约束指定单独的名称。 约束名称可帮助明确RDBMS返回的错误消息,并确切地知道该值违反了哪个约束。
要为约束指定名称,请使用CONSTRAINT关键字,后跟约束的名称。
例如,以下语句将positive_selling_price指定为sell_price列上的CHECK约束的名称。
分配CHECK约束名称的语法如下:
CREATE TABLE products ( product_id INT PRIMARY KEY, product_name VARCHAR(255) NOT NULL, selling_price NUMERIC(10,2) CONSTRAINT positive_selling_price CHECK (selling_price > 0) );
可以定义引用多个列的CHECK约束。假设在product表中存储了销售价格和成本,并且希望确保成本始终低于销售价格。
CREATE TABLE products ( product_id INT PRIMARY KEY, product_name VARCHAR (255) NOT NULL, selling_price NUMERIC (10, 2) CHECK (selling_price > 0), cost NUMERIC (10, 2) CHECK (cost > 0), CHECK (selling_price > cost) );
首先,有两个与sell_price和cost列相关联的CHECK约束,以确保每列中的值为正。
其次,有另一个未附加到任何列的CHECK约束,而是显示为CREATE TABLE语句中的最后一个子句。
前两个约束是列约束,而第三个约束是表约束。 表约束不与任何列关联。使用以下语法为表约束指定名称。
CREATE TABLE table_name ( …, CONSTRAINT check_constraint_name CHECK (Boolean_expression) );
例如,以下语句为上面的CHECK约束指定了一个名称。
CREATE TABLE products ( product_id INT PRIMARY KEY, product_name VARCHAR (255) NOT NULL, selling_price NUMERIC (10, 2) CHECK (selling_price > 0), cost NUMERIC (10, 2) CHECK (cost > 0), CONSTRAINT valid_selling_price CHECK (selling_price > cost) );
在本教程中,我们介绍了CHECK约束的一些概念,并演示如何使用CHECK约束来基于布尔表达式验证数据。